很难衡量一个检测算法的好坏,因为除了算法本身的思路之外,还有许多因素影响它的速度和精度,比如:
- 特征提取网络(VGG, ResNet, Inception, MobileNet);
- 输出的步长,越大分类数目越多,相应的速度也会受影响;
- IOU的评判方式;
- nms的阈值;
- 难样本挖掘的比率(正样本和负样本的比率);
- 生成的proposal的数目(不同的方法输出是不同的);
- bbox的编码方式,是预测offset还是相对位置?
- 数据预处理的数据增广方法;
- 用哪个特征层来做检测;
- 定位误差函数的实现方法;
- 不同的框架;
- 训练时候的不同设置参数,如batch_size, 输入图片大小,学习率,学习衰减率等因素;
为了对比不同的算法,可以不考虑上述的所有影响因素,直接对论文结果评测,应该能大体看出不同方法的速度差异。
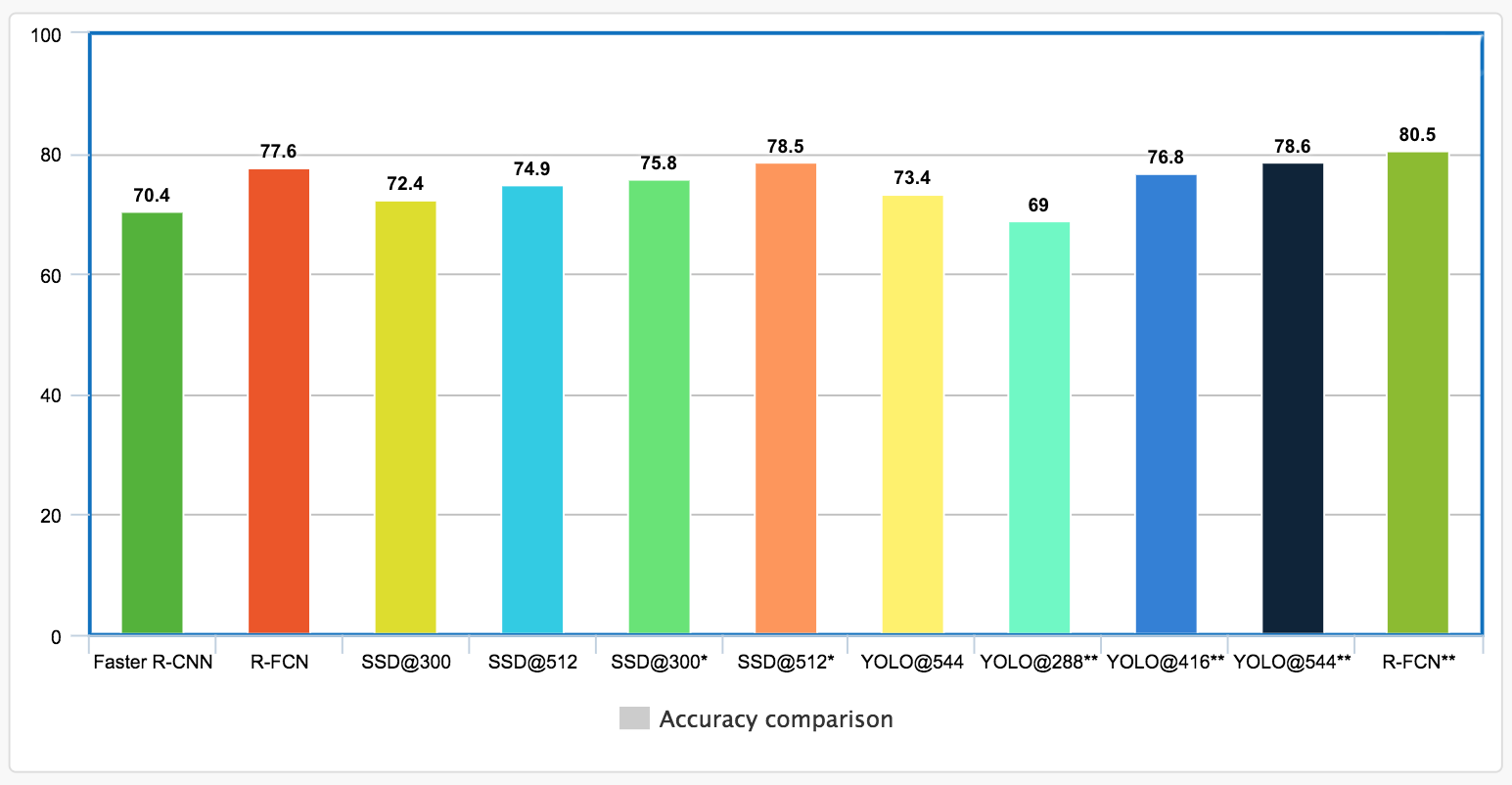
上图是一个所有方法的预览。从图中可以看出RFCN的准确度是最高的。
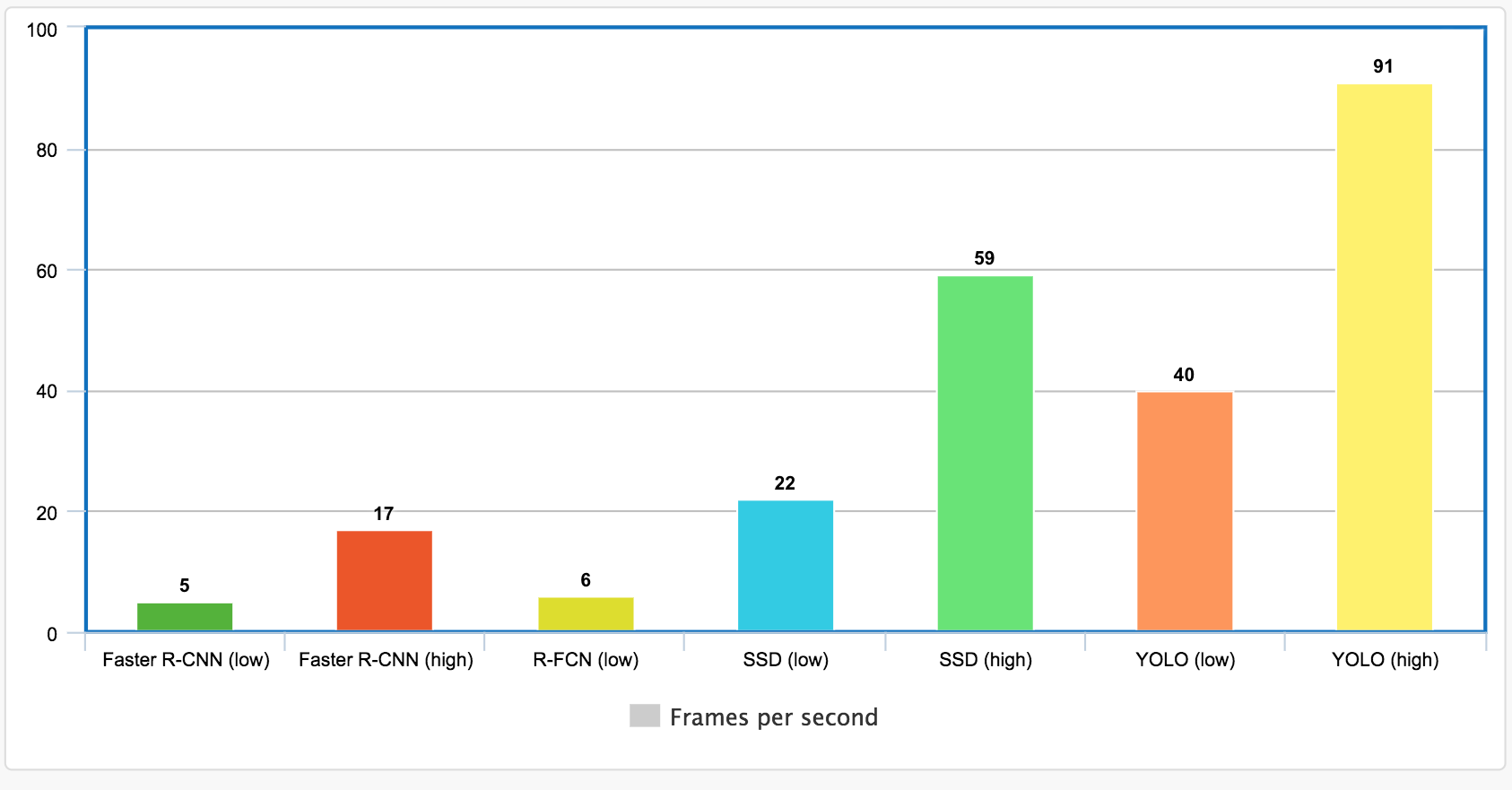
上图可以看出,速度最快的还是yolo和SSD一体化的方法。
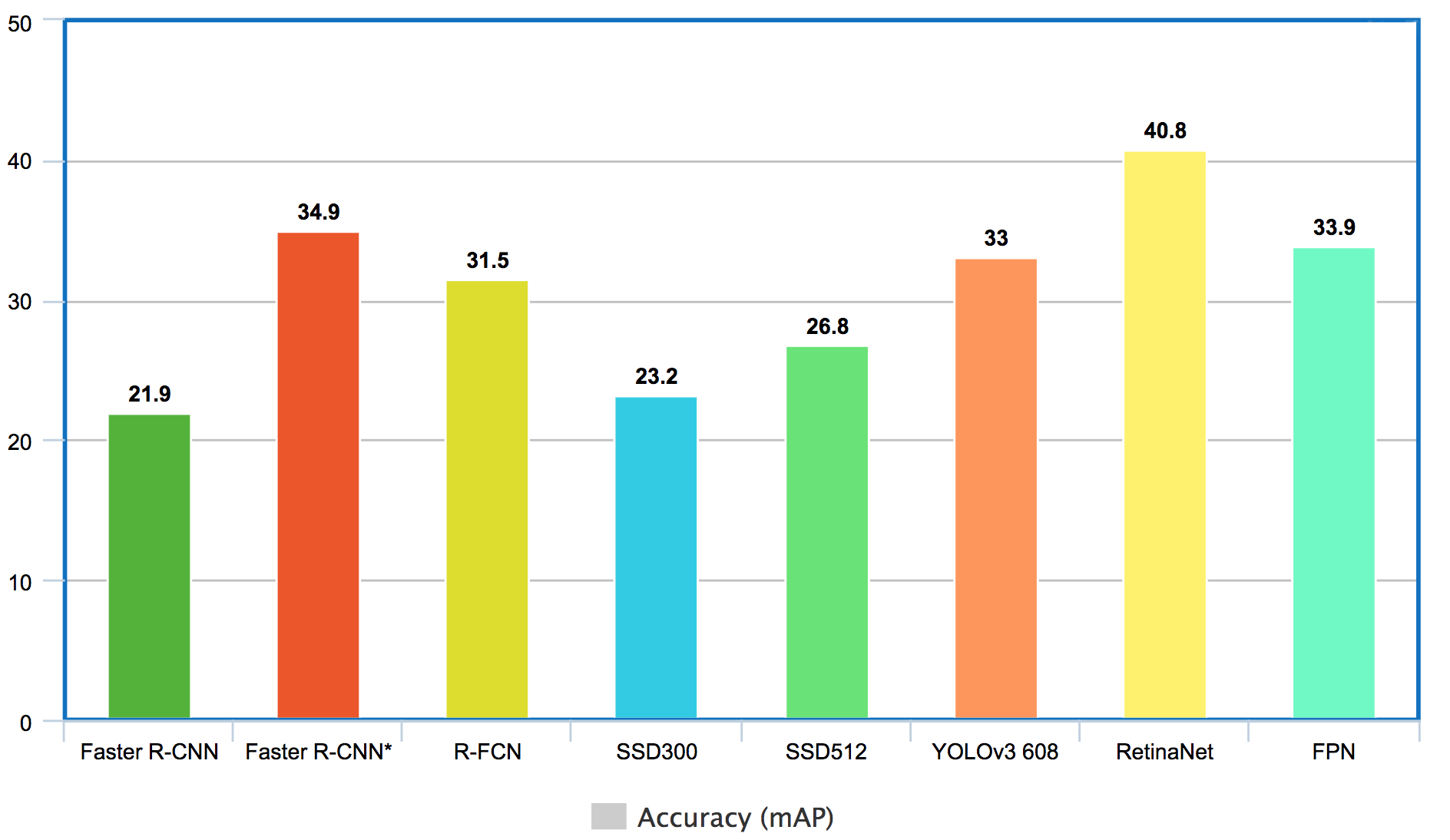
这是在ms-coo数据集上的测试效果,从效果可以看出,Retina-Net在mAP效果是最好的。其中Faster-RCNN改用Resnet作为特征抽取网络准确率有较大的提升。
最后是Google做的一个research,在TensorFlow上统一的实现了所有的检测算法,yolo没有包含在内。最终的测试结果可以表示为:
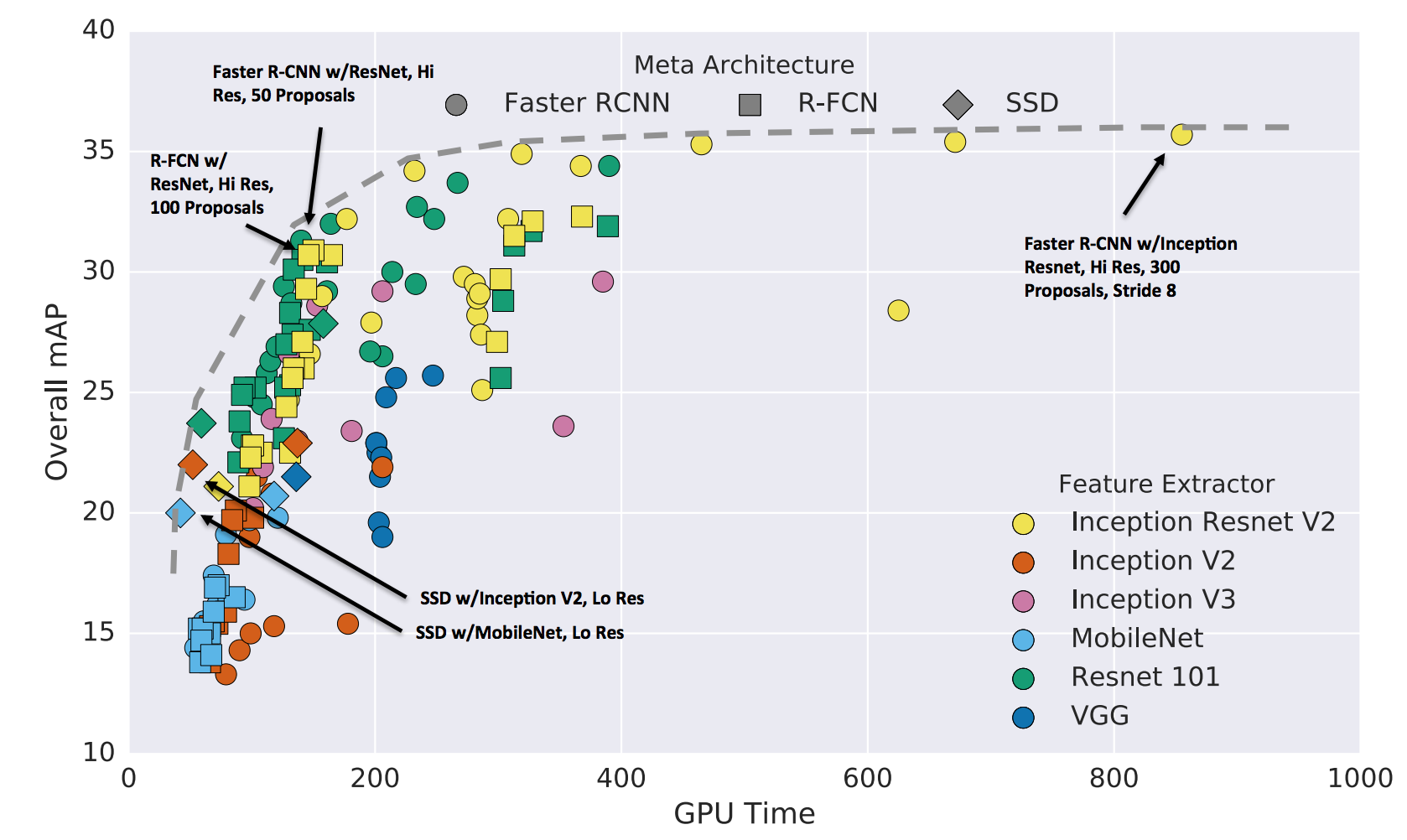
从上面可以大致的看出,Faster-RCNN的准确度更加精确,而RFCN和SSD更快。
上述只是一个预览,但是除了这些之外,我们还需要考虑一些更加细化的因素。
不同的特征抽取网络
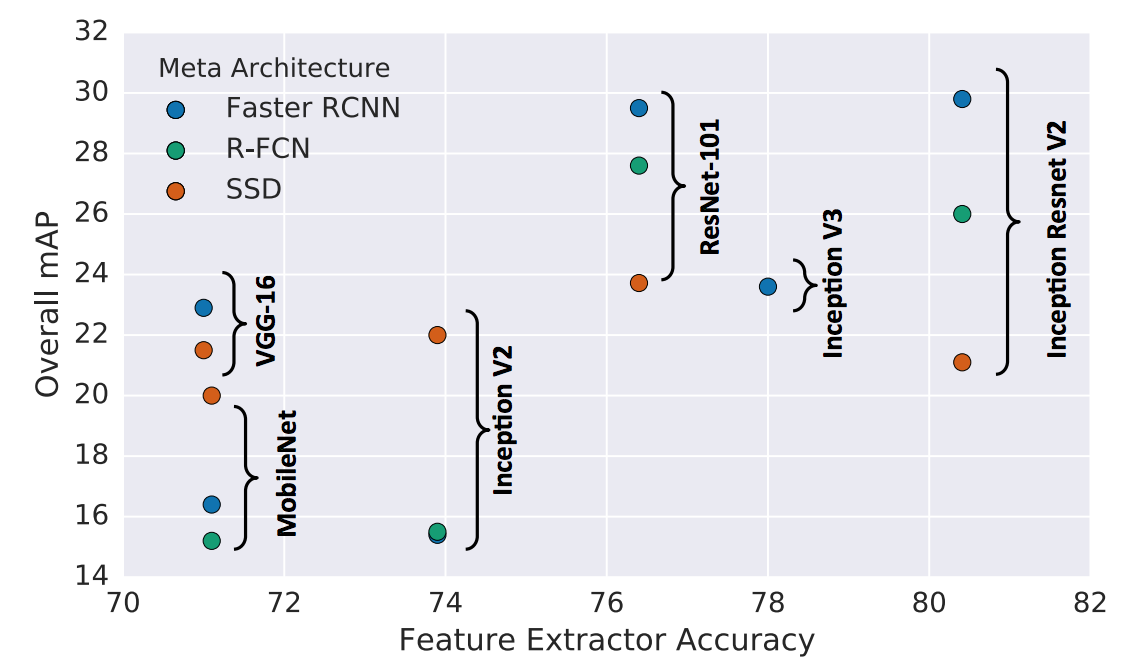
特征抽取网络不通,最终的结果也不同。简单来说,一个更加复杂的特征抽取网络可以大大的提高Faster-RCNN和RFCN的精确度,但是对于SSD,更好的特征抽取网络对结果影响不大,所以你看SSD+MobileNet也不会太大的影响结果。从这个图可以看得很清楚:
目标物体的大小
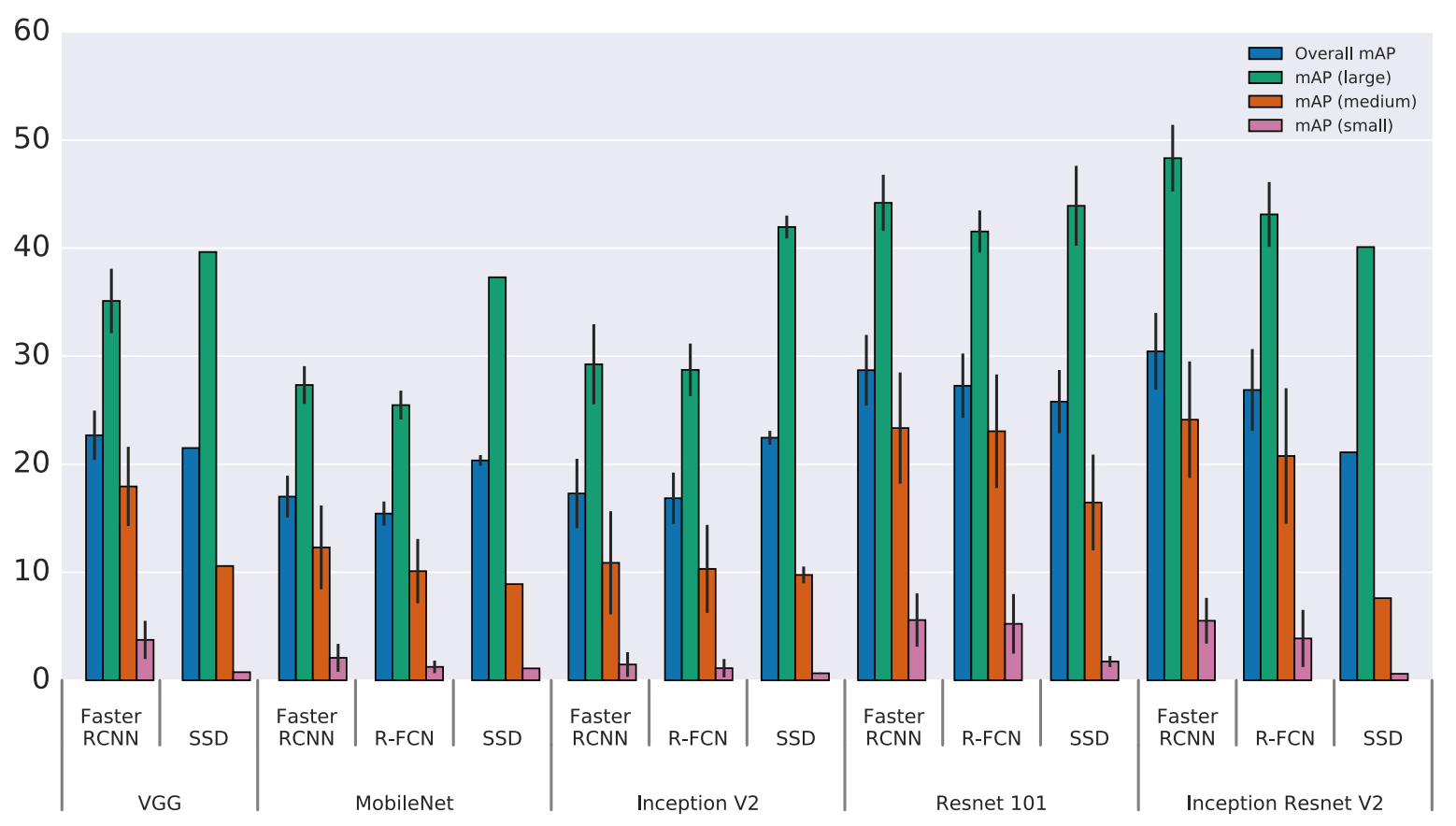
对于大物体,SSD即使使用一个较弱的特征抽取器也可以获取较好的精确度。但在小物体上SSD的表现结果非常不好。
具体来看,SSD在一张图片里面就经常漏检测小物体,比如:

Proposal的数目
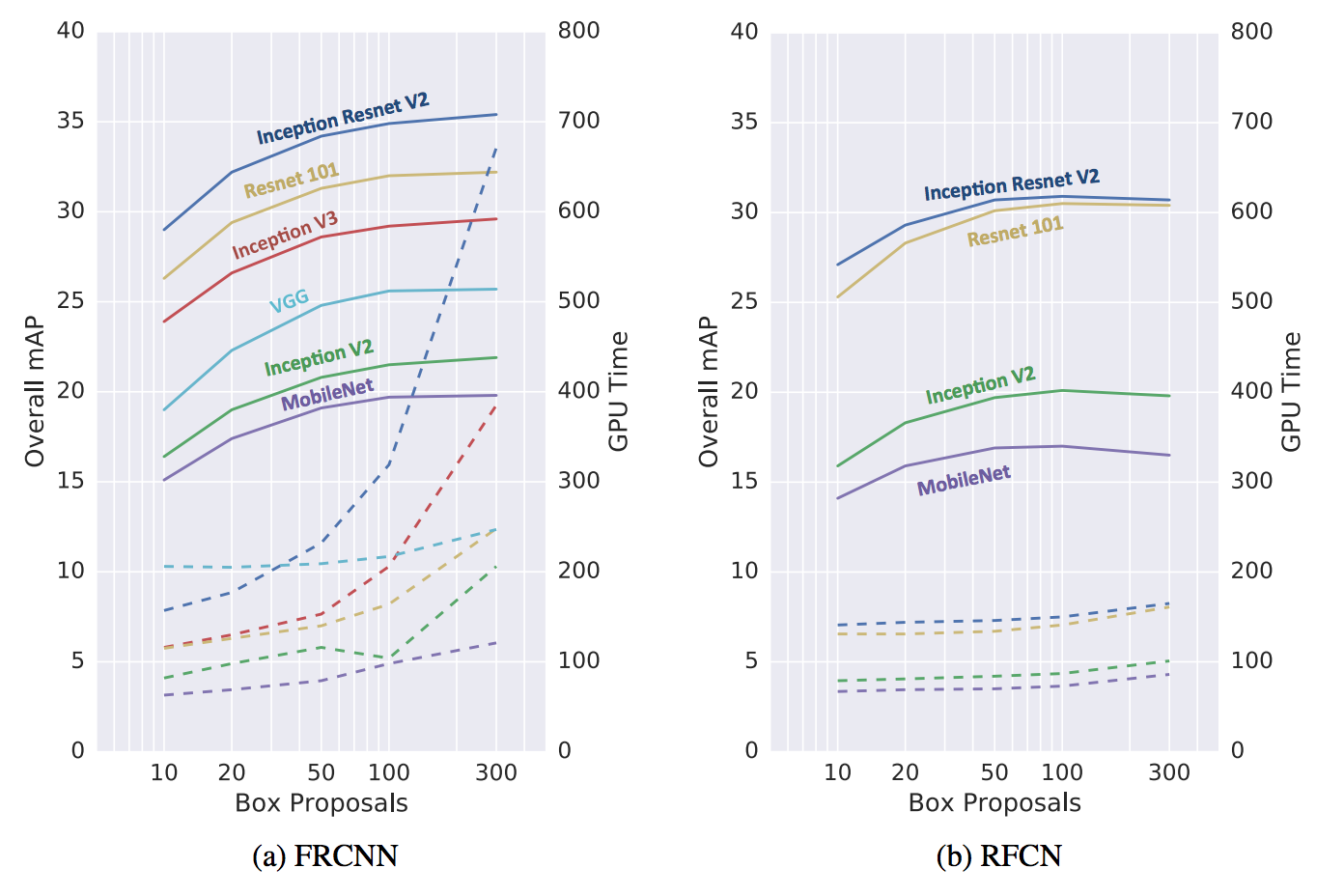
不同的Proposal数目会影响检测器的速度和精度。这个很重要,很多人想加速Faaster-RCNN但是不知道从何下手,显然这里是一个很好的切入点。
将Proposal的数目从300削减到50,速度可以提高3倍,但是精度仅仅降低4%,可以说非常值了。我们从这张图可以看得很清楚:
最终我们可以得到一个很科学的结果:
- 最高精度
使用Faster-RCNN毫无疑问,使用Inception ResNet作为特征抽取网络,但是速度是一张图片1s;
还有一种方法是一种叫做集成的动态选择模型的方法(这个你就不要追求速度了);
- 最快
SSD+MobileNet是速度最快的,但是小目标检测效果差;
- 平衡
如果既要保证精度又要保持速度,采用Faster-RCNN将proposla的数目减少到50,同时还能够达到RFCN和SSD的速度,但mAP更优。
最后,欢迎广大AI从业者、创业者加入深圳地区AI交流群,添加本人微信 jintianiloveu 发送信息:深圳AI交流 拉群。
