Introduction:
对于varied细胞图片,很难有一个适用性广的细胞计数算法。有很多人在研究自动聚类和细胞计数。本文用直方图信息来分离物体与背景,用flood fill(泛洪填充) 算法来填充目标,然后通过blob analysis(团块,连通域分析)来识别细胞。如果连通域面积比阈值大,这个连通域就用K-means clustering算法分割。(这里算是启发的地方吧!怎么用K均值聚类有待考虑)通过计算每个连通域里包含的细胞数,可以获得整个图片的细胞数目。
Segmentation of the cell image:
A 、 flood fill algorithm
一种区域填充算法,本质是种子生长算法。用来标记或者分割一些区域,为后续的图像处理分析做准备。它需要确定种子点,然后根据种子点和周围(8邻域或者4邻域)像素是否联通来决定要不要填充___(填充什么东西)。
It needs to determine seed points, then determines whether to be filled by judging neighbor pixel whether communicating with the seed or not, until all pixels in the region are found or the boundary of the region is reached.
B、Segmentation of image
这个系统用了region segmentation来分割细胞图像。分割结果are got by 直方图双阈值。。。
. The segmentation results are got by using histogram dual-threshold which has adjustable upper threshold and lower threshold.
直方图信息还可以快速准确地定位到合适的初始种子生长点。然后使用flood fill 算法填充目标区域。这个方法能够在完成每一步分割和填充以后,real-time展示图片。



(colonies 意思是群落,聚群,可能不是粘连细胞的意思!)
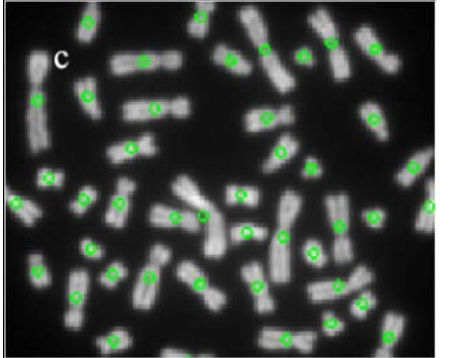
从以上这些结果图可以看出,本文的segmentation and filling方法能够被应用到不同形状的细胞中去。
Cell Detection:
A、 Blob Analysis
Blob Analysis 就是分析具有相似性质的连通区域。在图片处理中,就是指一个像素块有相似的影响特征(颜色,结构)并且是由空间中的联通区域构成的。
(Blob是指图像中的具有相似颜色、纹理等特征所组成的一块连通区域)
it refers to a pixel block which has similar image characteristics (color, texture, etc.) and is constituted by the connected domain in space.
由于联通区域分析是对于封闭的目标形状的处理方法,所以在进行blob analysis之前,把图片分割成联通域像素的集合和背景像素的集合是有必要的。
Because blob analysis is a processing method for closed objective shape, it is necessary to segment image into collection of pixels about and local background before doing blob analysis.
blob analysis 由灰度图片而来(要先进行灰度处理),图片需要被划分成目标像素和背景像素。这一步骤通过直方图分割来实现。
B、 Cell detection using blob analysis
每个object被blob analysis method 有很多属性,比如centroid(质心), roundness(圆的程度)。一个container保存一张细胞图片里blobs的总数,第二个和第三个container保存各个blobs的面积和centroid。
下面是通过blob analysis来识别细胞的算法步骤:
1、遍历整张图片找到所有的blobs,计算他们的面积。定义三个containers,第一个存找到的连通区域,第二个存连通区域的面积,第三个存连通区域的centroids。
2、如果找到的blob的面积比最小的面积阈值还小,那么这个blob是noise,不处理它。
3、如果找到的blob的面积比最大的面积阈值还大,那么这个blob是粘连细胞(adherent cell),需要被分割成subblob。
4、把subblob插入到第一个container里,把subblob的centroid存到第三个container里,更新containers的信息。
5、subblob的数量就是在blob(面积大的)中包含的细胞数量。没有被分割的blob看做一个细胞。
Blob Segmentation:
A、 K-means clustering
K均值聚类在模式识别中被广泛运用。它指定一个K作为样本集合的初始聚类中心,聚类结果是由K个聚类中心所反应的。基于一个给定的聚类目标函数或是聚类准则,这个算法采用迭代更新方法。每一步迭代都向着目标函数值减小的方向靠近。最后的聚类结果是使得目标函数的值最小,把它得到的结果作为聚类结果。

其中,K代表初始的聚类中心(数目),nj代表第j类里面样本的数目,xi代表第i个样本,mj代表第j类的聚类中心。
下面是K均值聚类的算法步骤:
1、随机从样本集中选择K个样本作为初始的聚类中心点。
2、分别计算每个样本到K个聚类中心点的距离,然后根据最小距离重新分配对应目标的聚类范围。(不是这个意思,具体再百度一下)
3、重新计算聚类中心点。
4、循环step2和step3知道每个聚类中心点都不在变化。
(具体实现ML那门课上有,也可以百度)
B、 Blob segmentation using K-means clustering
K means clustering的结果取决于初始聚类中心的好坏。把面积大的blob拿过来聚类。

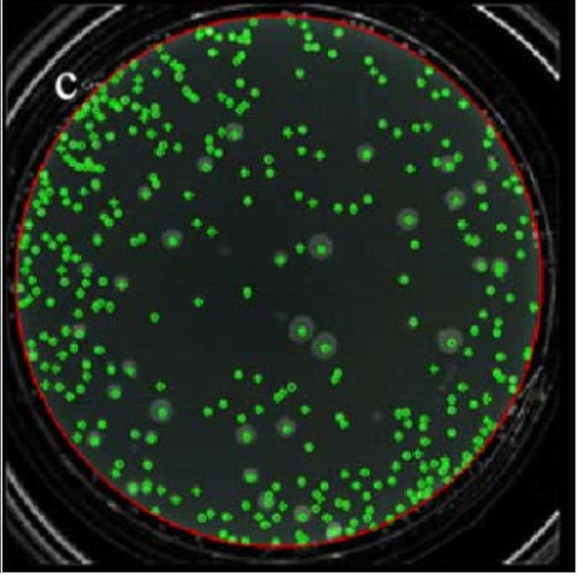
整个流程:
It initially segments the cell image by combining histogram information with Floodfill method, then using blob analysis detects blobs in the whole image, and using K-means clustering segments the blobs which have size beyond the upper threshold of area , finally, the number of cells in the image is obtained accurately.
