主线程有个事件循环。每次有事件的时候,由cocoa框架调用我们写的代码,再回到cocoa框架。NSAutoreleasePool其实是由cocoa框架管理的,当出了我们写的代码,回到框架的时候,放入NSAutoreleasePool的对象就会由框架调用release, 这样就保证跑我们代码的时候,对象是会存在的,出了我们的代码,对象也能够正常地被释放。
比如
系统代码(事件激发)
funA()
funB()
funC()
funD()
系统代码(等待事件)
在funA, funB, funC, funD中,无论调用多少层,也是用户写的代码。autorelease的对象还是存在的。下一次事件激发的时候,上一次事件的对象是不存在的,因为已经被系统框架调用release回收了。除非你自己调用了retain, 自己调用了一次retain, 就应该自己来调用一次release, 这样也没有违背上面说的原则。
自动释放池的缺点:它延缓了对象的释放,在有大量自动释放的对象时,会占用大量内存资源。因此,你需要避免将大量对象自动释放。并且,在以下两种情况下,你需要手动建立并手动销毁掉自动释放池:
1.当你在主线程外开启其它线程时:系统只会在主线程中自动生成并销毁掉自动释放池。(runloop未开启)
2.当你在短时间内制造了大量自动释放对象时:及时地销毁有助于有效利用iPad上有限地内存资源
iOS的运行时是由一个一个runloop组成的,每个runloop都会执行下图的一些步骤:
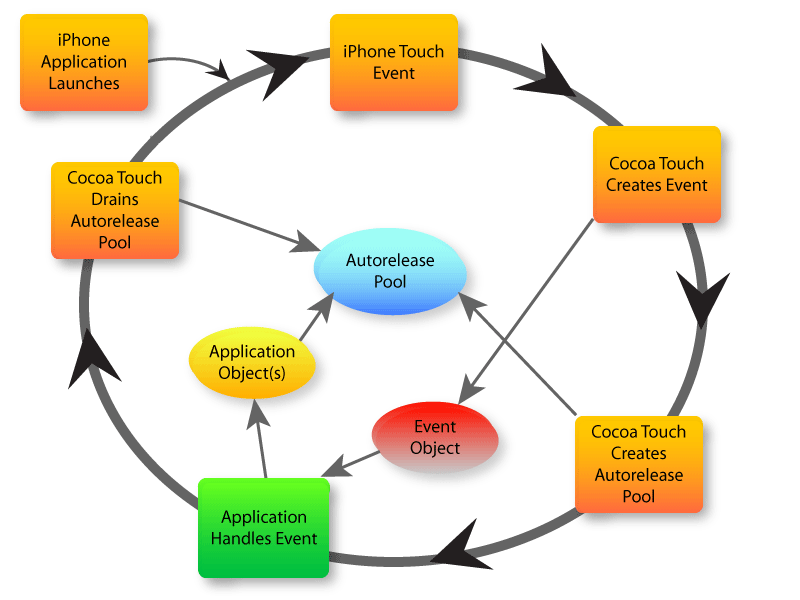
可以看到,每个runloop中都创建一个Autorelease Pool,并在runloop的末尾进行释放,
所以,一般情况下,每个接受autorelease消息的对象,都会在下个runloop开始前被释放。也就是说,在一段同步的代码中执行过程中,生成的对象接受autorelease消息后,一般是不会在代码段执行完成前释放的。
当然也有让autorelease提前生效的办法:自己创建Pool并进行释放
NSAutoreleasePool* pool = [[NSAutoreleasePoolalloc] init];
NSArray* array = [[[NSArrayalloc] init] autorelease];
[pool drain];
上面的array就会在[pool drain]执行时被释放。
所以对于你遇到的问题,可以在for循环外嵌套一个Autorelease Pool进行管理,例如
NSAutoreleasePool* pool = [[NSAutoreleasePoolalloc] init];
for(inti =0; i <10000; i++)
{// ...}
[pool drain];
但由于你提到了生成的每个实例可能会比较大。只在循环外嵌套,可能导致在pool释放前,内存里已经有10000个实例存在,造成瞬间占用内存过大的情况。
因此,如果你的每个实例仅需要在单次循环过程中用到,那么可以考虑可以在循环内创建pool并释放
for(inti =0; i <10000; i++)
{NSAutoreleasePool* pool = [[NSAutoreleasePoolalloc] init];
// ...[pool drain];}
