学校有几门课程的作业需要我们来写个教程,好吧。
环境准备
软件安装
由于该系统是英文系统,有可能对中文字符支持不友好,因此要安装中文的UTF-8字符集。同时因为Hadoop是Java的杰出产物因此需要安装Java,为了方便,在这里选用OpenJdk,版本Java8。而需要用到的vim、ssh等命令已内置在Ubuntu16.04中,因此无需重复安装。
sudo su
apt install -y language-pack-zh-hant language-pack-zh-hans
apt install -y openjdk-8-jre openjdk-8-jdk
创建用户以及权限配置
本次实验中我们创建一个hadoop用户,而对hadoop的使用操作都通过hadoop用户实现。同时为了方便hadoop操作中的ssh登录,我们配置无密码ssh登录。
useradd -m hadoop -s /bin/bash
passwd hadoop
adduser hadoop sudo
su hadoop
此后,hadoop用户便是运行hadoop程序的用户,以下的操作便是以hadoop用户的身份运行的。接下来生成密钥用于无密码登录:
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
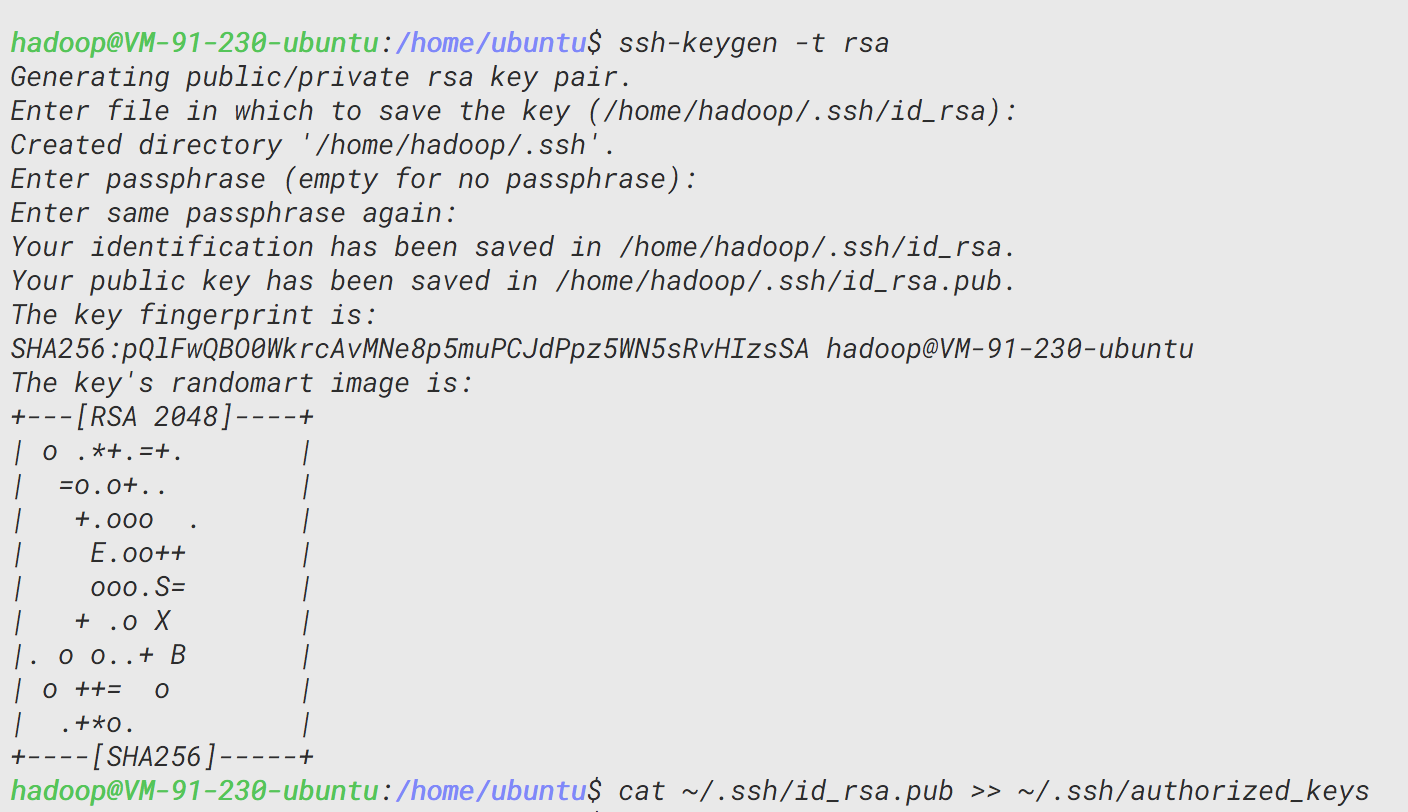
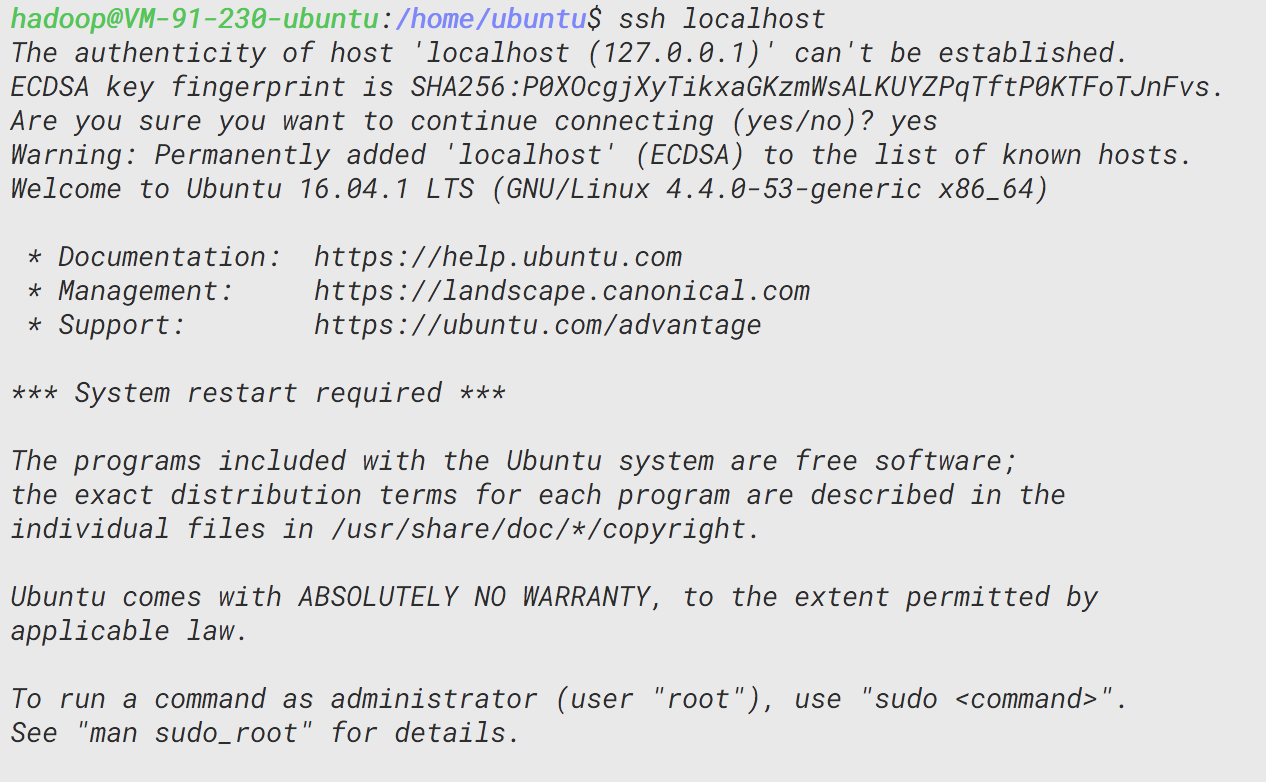
配置完后即可通过ssh localhost命令无密码登录,需要注意的是要按提示输入yes
下载hadoop并放置到约定俗成的位置
这次实验的hadoop版本是2.8.0,下载使用wget命令,软件源为了快速选用国内的清华源,同时将hadoop文件夹移到约定俗成的/usr/local目录下。
wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
tar zxvf hadoop-2.8.0.tar.gz
mv hadoop-2.8.0 hadoop
sudo mv hadoop /usr/local/
sudo chown -R hadoop /usr/local/hadoop
cd /usr/local/hadoop/
此后,/usr/local/hadoop这个目录便是hadoop目录,下面的操作都是在目录下操作的。
配置Java和Hadoop的环境变量
需要在/etc/profile和./etc/hadoop/hadoop-env.sh(目前在hadoop目录下)这两个文件的末尾加入以下变量:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
CLASSPATH=$CLASSPATH.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
修改第一个文件就是修改当前的环境变量,修改第二个文件就是修改ssh后的环境变量。
这些就是Java和Hadoop的环境变量,加载了这些环境变量即可在命令行运行特定命令,现在重新加载这配置文件:
. /etc/profile
配置伪分布式环境
初始化hdfs
编辑./etc/hadoop/core-site.xml和./etc/hadoop/hdfs-site.xml两个文件
vim ./etc/hadoop/core-site.xml
修改里面配置,感兴趣的可以查一下含义,主要是每一个property的name和value:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
vim ./etc/hadoop/hdfs-site.xml
修改里面配置,指名name、data文件夹在这个服务器上的路径(因为是伪分布式,所以都在这个服务器上):
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
以上就完成了伪分布式的配置,接下来就是格式化这些存储节点
./bin/hdfs namenode -format
中间太多了略过直接看末尾:
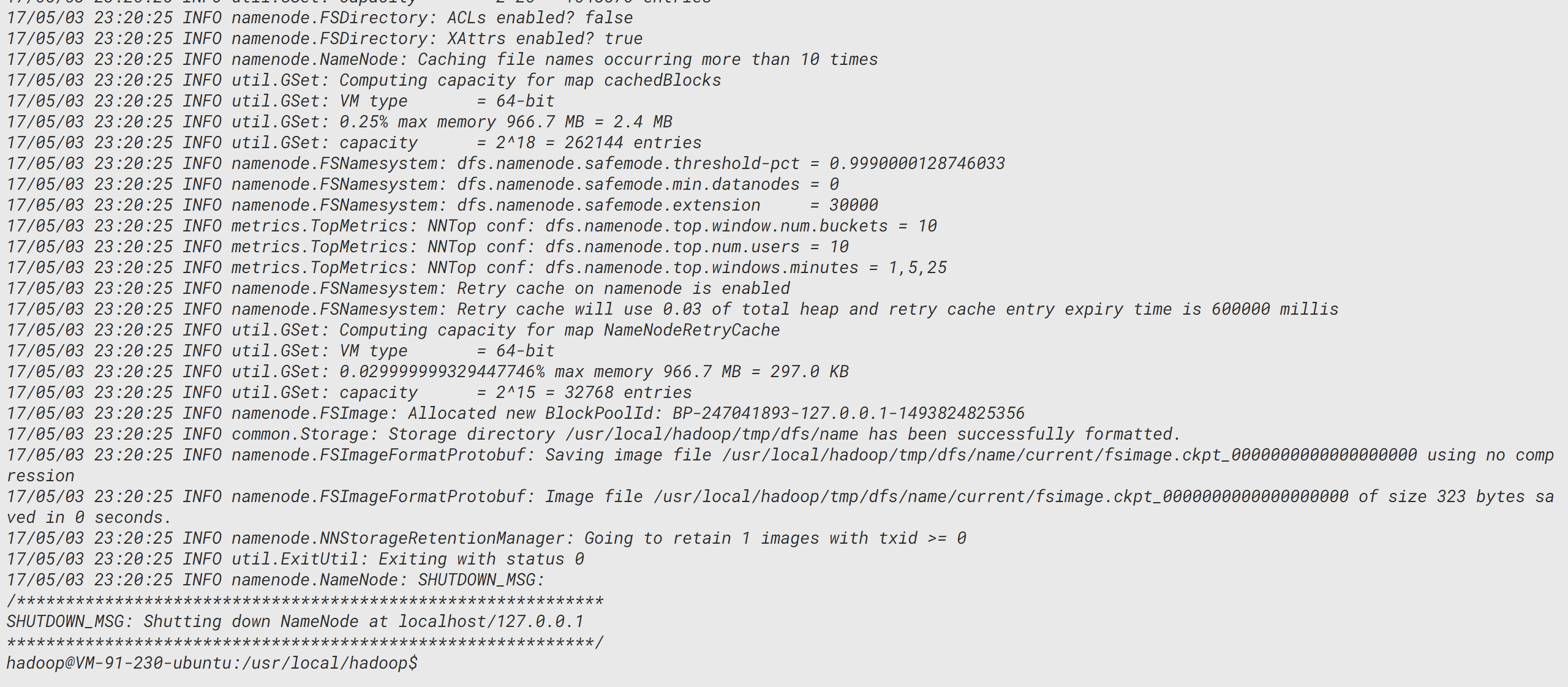
在此看到Exiting status为0,结合大多数程序和系统脚本,结束状态码为0即为正常运行结束。
开启 NameNode 和 DataNode 守护进程
运行./sbin/start-dfs.sh命令即可启动

注意本次运行以及以后的运行程序有可能出现以下WARN:
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
该 WARN 提示可以忽略,并不会影响正常使用(该 WARN 可以通过编译 Hadoop 源码解决)。
而后即可通过 http://机器ip:50070 来访问 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
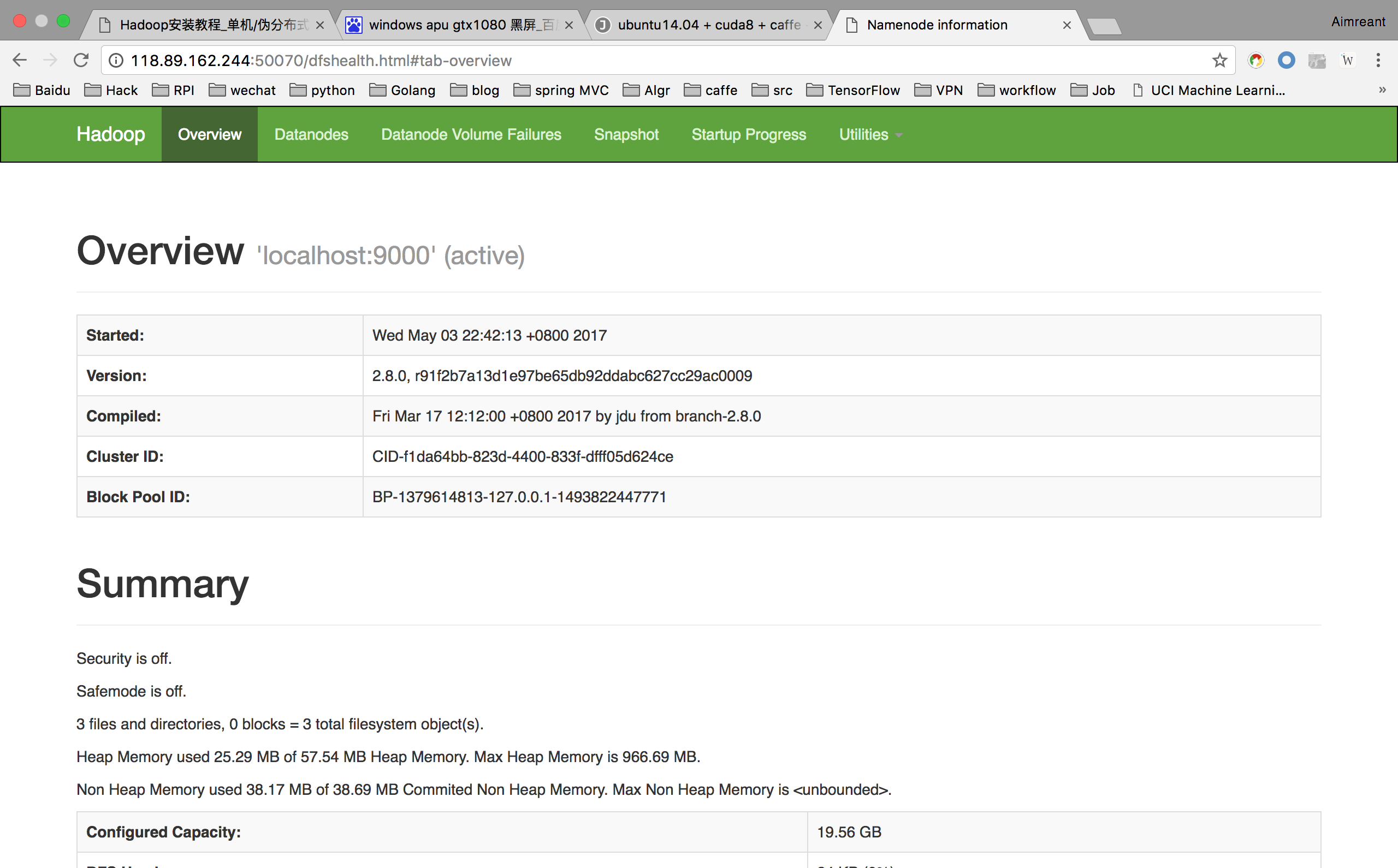
在命令界面也可以通过jps来查看 NameNode 和 Datanode 信息是否在运行。
运行例子
命令查看
可以通过./bin/hdfs dfs -help命令来查看使用方法:
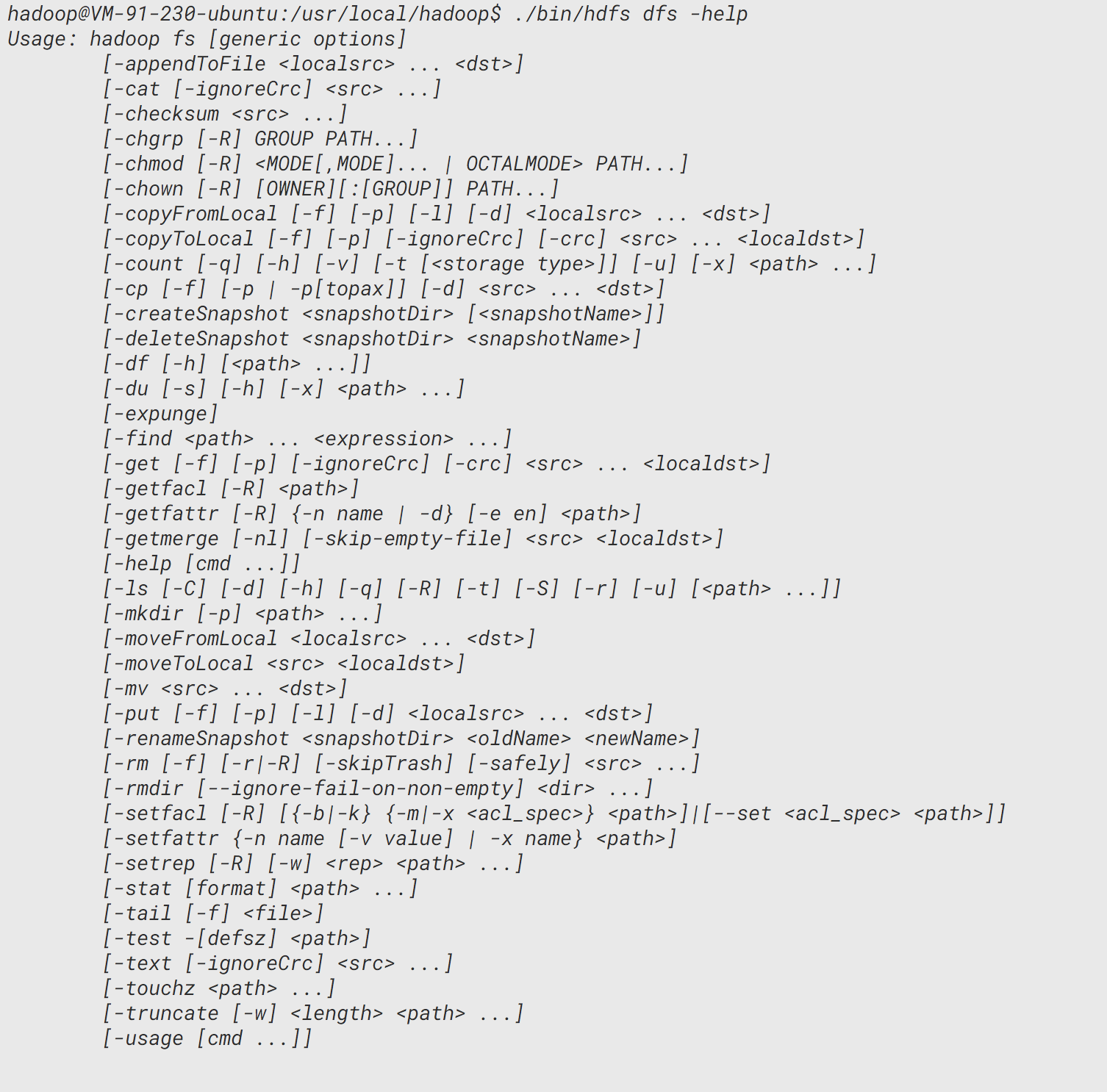
例如查看hadoop版本的命令:

在 HDFS 中创建用户目录
先通过./bin/hdfs dfs -mkdir -p /user/hadoop命令创建一个用户目录
例子一 解析配置文件
本次实验可以就地取材,选择hadoop的配置文件为材料,使用伪分布式hadoop平台来解析。先用put命令把配置文件都放入hdfs的一个新建文件夹input:
./bin/hdfs dfs -mkdir /user/hadoop/input
./bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input/
./bin/hdfs dfs -ls input

然后运行例子,解析input里面的配置文件,并将解析结果放入output文件夹:
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /user/hadoop/input/* /user/hadoop/output 'dfs[a-z.]+'
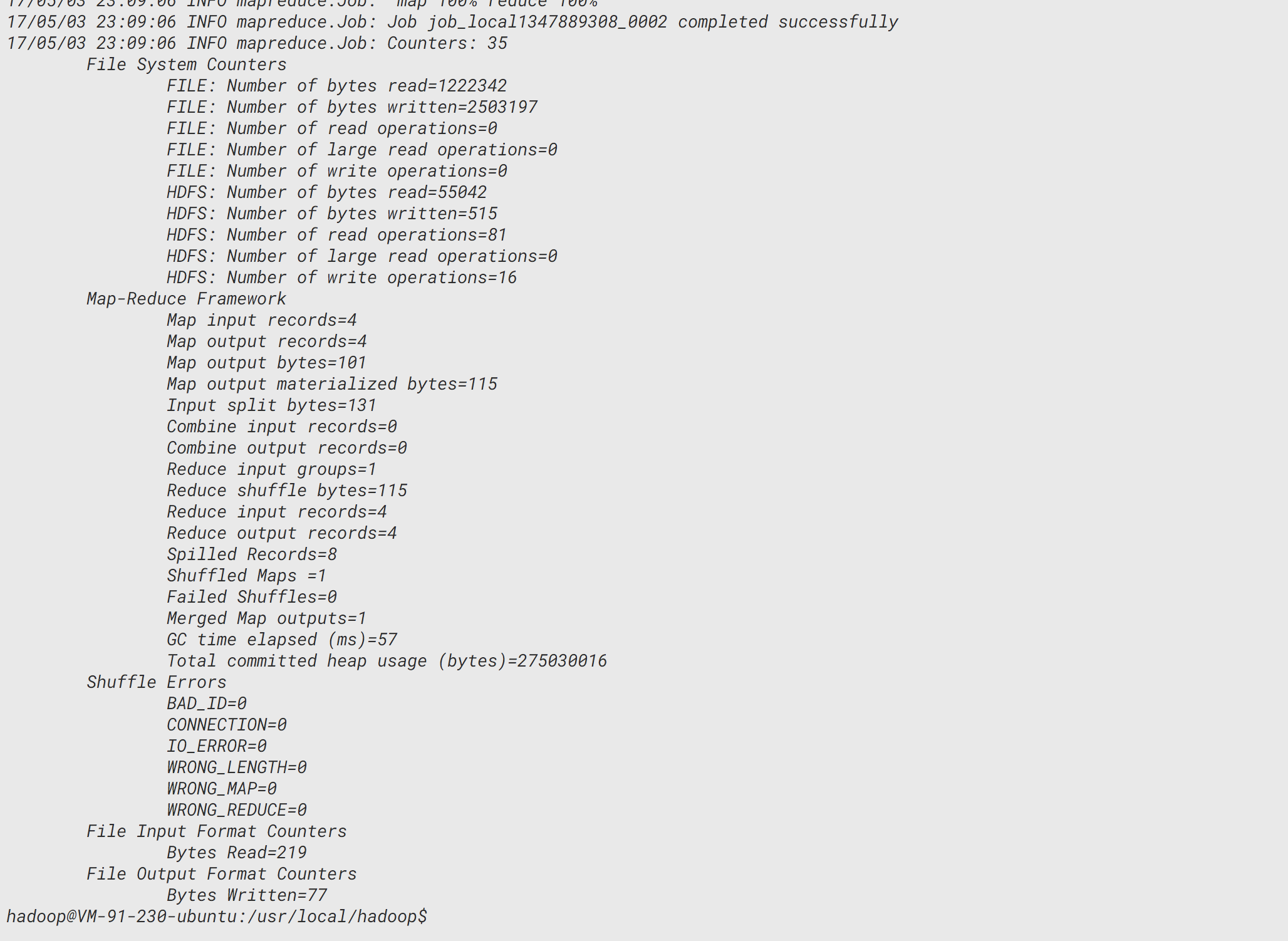
把output里面的解析结果通过cat命令输出:
./bin/hdfs dfs -cat /user/hadoop/output/*

把output里面的解析结果从hdfs中取出(这个操作是常用的,尽管在伪分布式里面没什么意义,但是在真实环境下特别有用):
./bin/hdfs dfs -get /user/hadoop/output ./output
例子二 WordCount
wordcount是一个hadoop内置的范例程序,用于统计单词数量。
首先,要删除例子一留下的实验痕迹:
./bin/hdfs dfs -rm -r -f /user/hadoop/output /user/hadoop/input
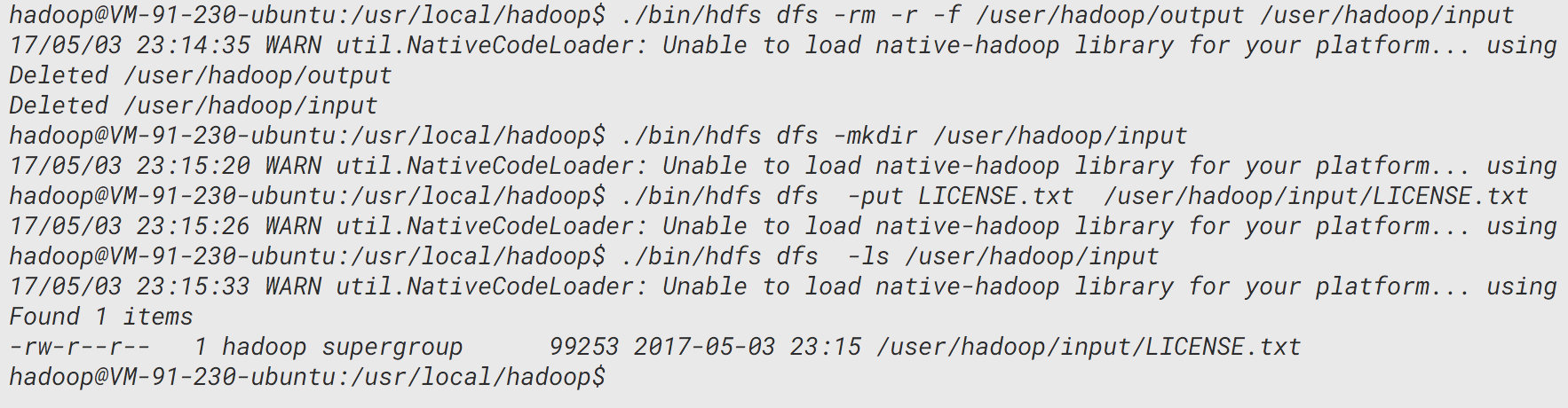
然后和实验一一样,创建hadoop的输入文件夹,同时就地取材一个可读文件:
./bin/hdfs dfs -mkdir /user/hadoop/input
./bin/hdfs dfs -put LICENSE.txt /user/hadoop/input/LICENSE.txt
./bin/hdfs dfs -ls /user/hadoop/input
运行例子,结果放置在output文件夹:
./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar wordcount /user/hadoop/input /user/hadoop/output
./bin/hdfs dfs -cat /user/hadoop/output/*
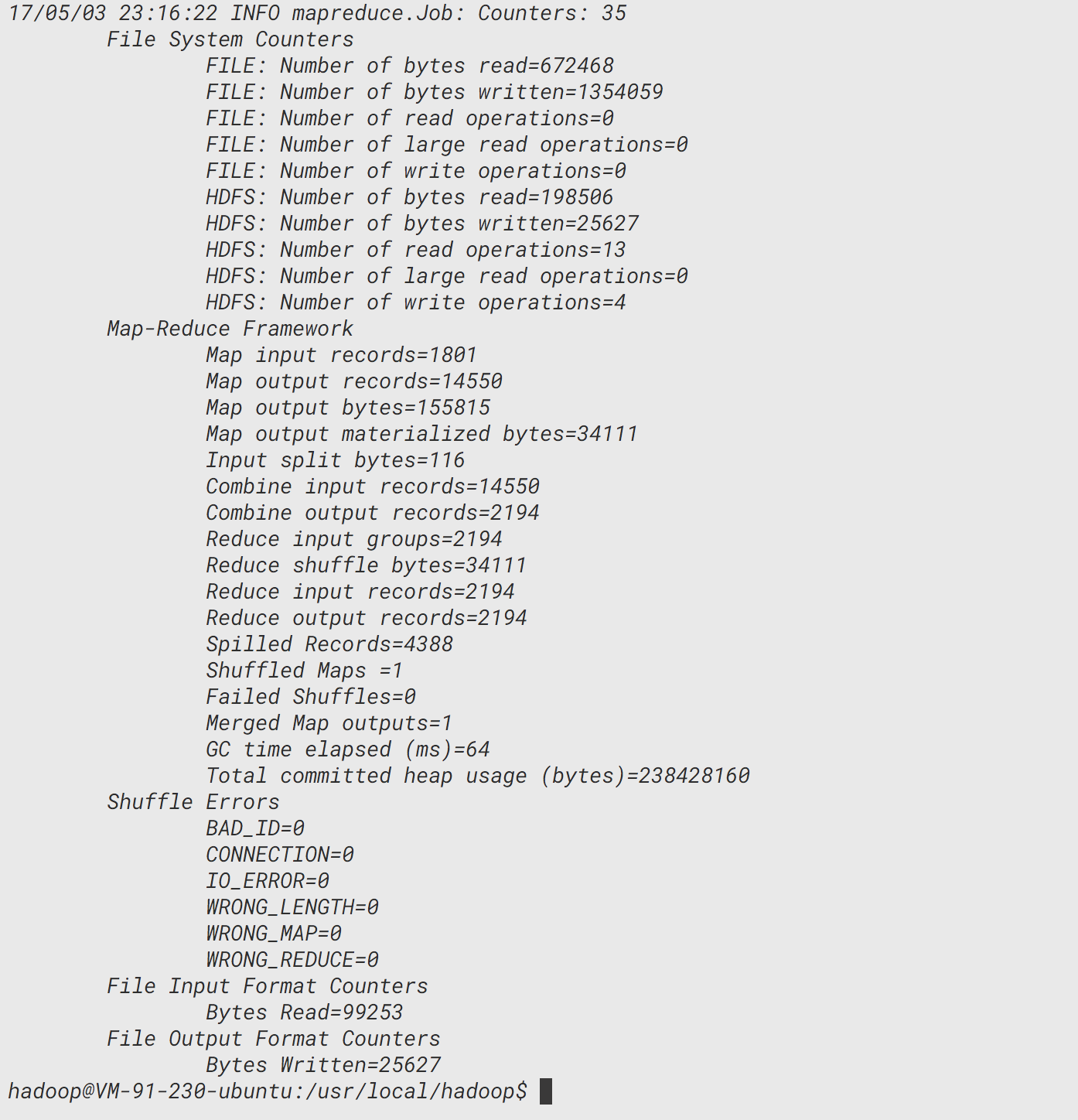
可以看到,屏幕是被刷了好几遍,因为输出太多了,我们可以统计一下输出了有多少行:
./bin/hdfs dfs -cat /user/hadoop/output/* | wc -l
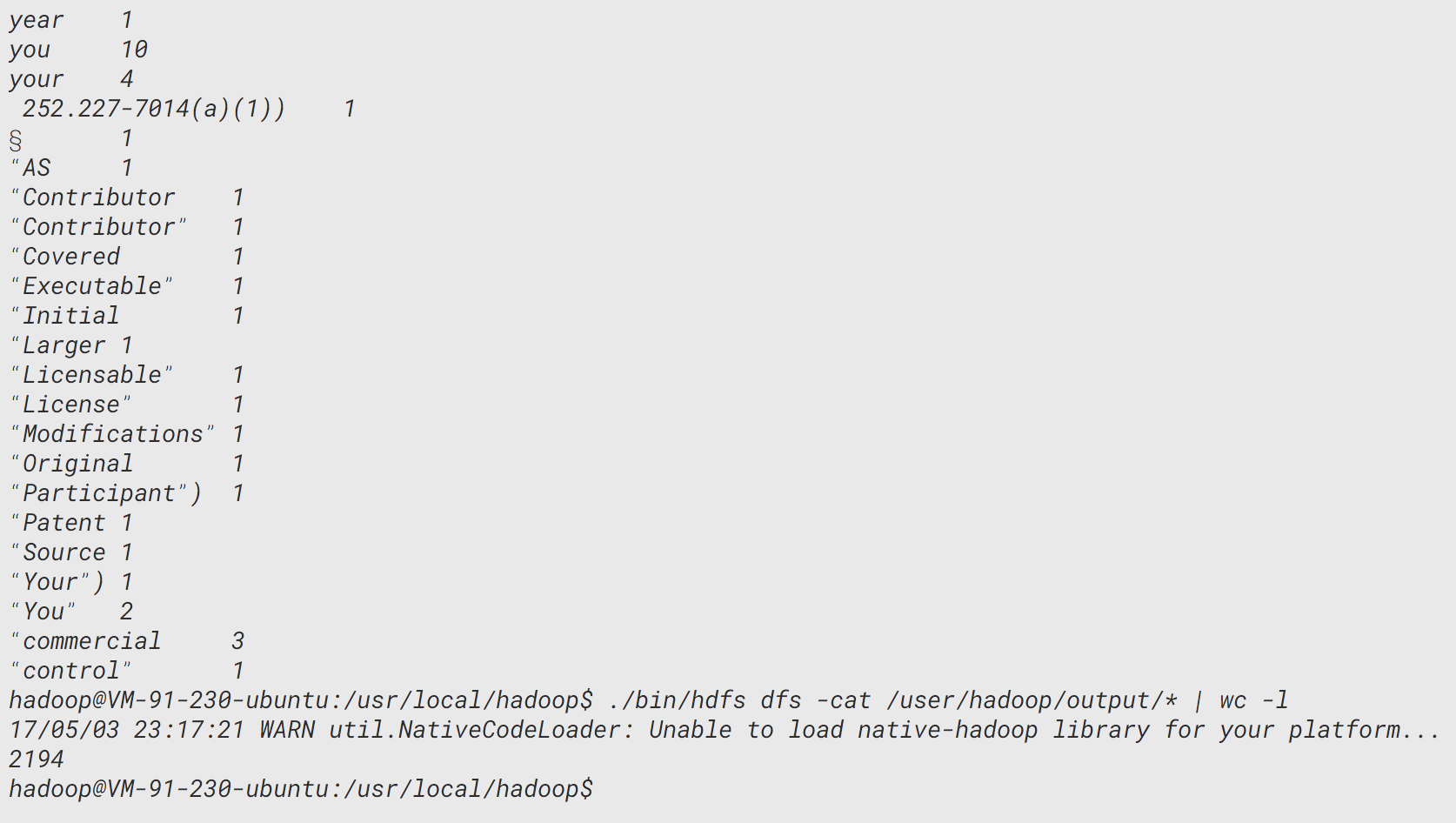
噢,原来有2000多行的输出呢!
结论
hadoop的思想已经融入了我们很多分布式系统里面,熟悉hadoop的思想和操作有助于我们更宏观地观察这个现代化网络世界。
若有错误之处请指出,更多地关注煎鱼。
