1.概述
Volley的源代码分析,网上一大把的分析博客,但是当你看完这些博客后,也是云里雾里的,很多一上来就上源代码分析,典型的就是这一篇:
http://blog.csdn.net/guolin_blog/article/details/17656437
还有从结构上讲,总的来说,比上从源代码讲强那么一点,典型的就是这一篇。单总的来说,这一篇比上一篇强一点。
对于一上来就开始分析源代码的行为,我敬而远之。
现在回过头来看Volley的源代码,感觉从设计的角度来说,Volley设计并不算是优秀,但是volley的扩展性非常棒,面向接口编程在这里得到完美的体现,这是阅读volley源代码之后的最大感受。
volley的类没有几个,对于打基础的阶段,阅读该库对提升技术水平有很好的帮助。
volley说明

从名字由来和配图中无数急促的火箭可以看出 Volley 的特点:特别适合数据量小,通信频繁的网络操作。
对于文件上传,文件下载等操作,还是换成另外的库吧。至于为什么,因为其设计就决定了。
源码分析方法
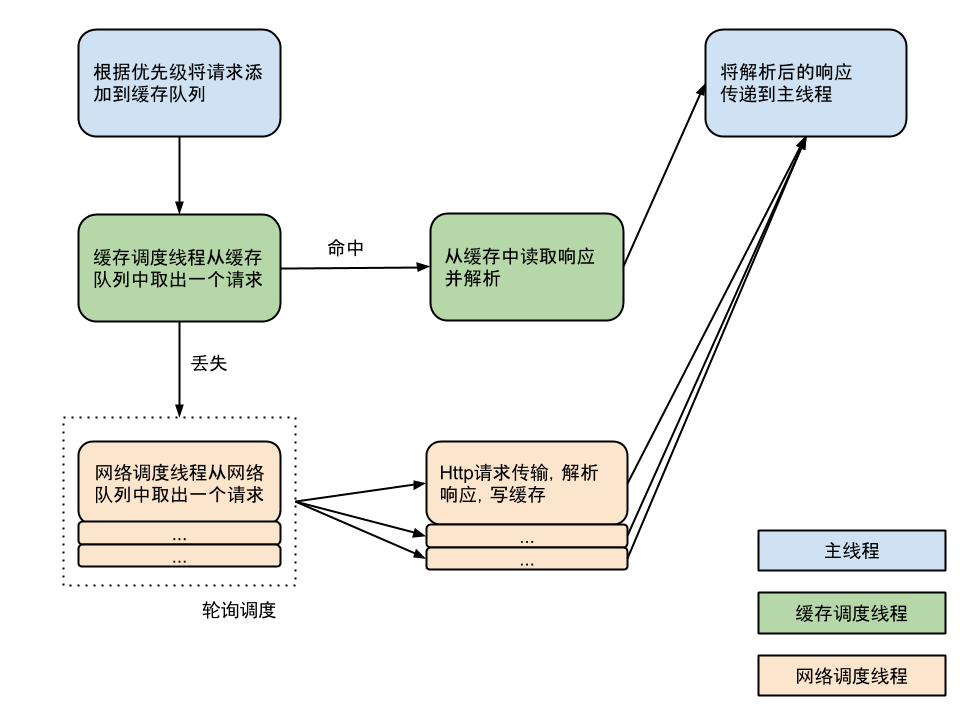
其实Volley的设计思路和源码分析的方式在上面的这个图就已经高度的概括展示出来了。这张图已经说明了volley的工作原理和设计思路。
这是是volley源代码的结构:

源代码分析
我们先不看 "toolbox"文件夹,因为该文件夹主要是其接口的实现。
现在我们看下面一些无关紧要的类:
- VolleyLog。
是一个日志类,与此无关,去掉。
- VolleyError,TimeOutError,ServerError,ParseError,NetworkError,AuthFailureError,NoConnectionError。
这些都是异常的错误处理,其中后面的Error相关的类都时VolleyError的子类,这个对分析volley结构没有什么帮助,去掉不看。
- RetryPolicy ,DefaultRetryPolicy。
后者是前者的子类,我们只看RetryPolicy这个就行了。实际上这个是是重置访问,比如本次访问超时,设置20s后再次连接,这个就是重置的作用,对于分析Volley的整个结构来说,无关紧要,可以不看。在分析具体的代码和细节的时候再去看。
- ResponseDelivery 和 ExecutorDelivery。
后者是前者的一个实现。这个类作用就是异步操作,实际上就是一个Hanlder的事件分发,将子线的结果分发到主线程中。分析结构的时候,只需要关心ResponseDelivery。
- Cache 缓存的接口。
去掉上面那那些无关紧要的类之后,剩下就没有几个类了,我们看看还剩下那些类。
Network 具体的网络访问
CacheDispatcher 缓存调度线程
NetworkDispatcher 网络访问调度线程
NetworkResponse 网络访问的直接结果,不是分发到主线程的结果
Request 网络请求的封装,包括请求的url,请求的方法,请求的的内容等等。
RequestQueue 这个看起来好像是一个请求的对象,实际上这个只是将这些类根据规则组合在一起的东西。源代码的分析就是从这里从这个类开始进行的。
Response 封装了分发的结果,这个怎么理解呢,就是 NetworkRespond的结果经过进一步处理分发到主线程中的结果。
怎么样,剩下的也没有几个,这样就大大的降低了阅读代码的难度了。
RequestQueue开始
这个类是整个Volley的开始部分,先看start()方法:
public void start() {
stop(); // Make sure any currently running dispatchers are stopped.
// Create the cache dispatcher and start it.
mCacheDispatcher = new CacheDispatcher(mCacheQueue, mNetworkQueue, mCache, mDelivery);
mCacheDispatcher.start();
// Create network dispatchers (and corresponding threads) up to the pool size.
for (int i = 0; i < mDispatchers.length; i++) {
NetworkDispatcher networkDispatcher = new NetworkDispatcher(mNetworkQueue, mNetwork,
mCache, mDelivery);
mDispatchers[i] = networkDispatcher;
networkDispatcher.start();
}
}
前面说过了,CacheDispatcher和NetworkDispatcher是两个线程一个是缓存调度线程,一个是网络请求调度的线程。
上面的代码就是开启一个缓存调度线程和若干个(默认四个)网络请求调度线程。
接下来我们看看CacheDispatcher线程。
CacheDispatcher线程
既然是一个线程,那么我们只关心 线程run方法就可以了
下面是伪代码,剔除一些日志,异常判断等无影响代码后的结构
while(true){
//先从缓存队列中拿出一个请求
final Request request = mCacheQueue.take();
//如果这个请求取消了,那么这个请求直接结束,开始下一个循环
if (request.isCanceled()) {
request.finish("cache-discard-canceled");
ontinue;
}
// 如果没有缓存或者缓存失效的话,就将这条请求添加到网络请求调度线程中
Cache.Entry entry = mCache.get(request.getCacheKey());
if (entry == null || entry.isExpired()) {
mNetworkQueue.put(request);
continue;
}
//从缓存中拿出结果。
Response response = request.parseNetworkResponse(
new NetworkResponse(entry.data, entry.responseHeaders));
request.addMarker("cache-hit-parsed");
//分发结果
mDelivery.postResponse(request, response);
}
从上面的伪代码可以看出,实际上缓存调度线程做的事情非常的简单,逻辑一点也不复杂。
先从缓存队列中拿出一条请求。
判断这个请求是否已经标志结束了,如果结束了那么设置这条请求结束,并分发结果。否则进入下一步。
判断缓存是否存在,缓存是否过期,如果过期了,之前没有缓存,那么就将这条请求放到网络调度的线程中。
NetworkDispatcher
网络请求调度线程的分析方法和上面类似,实际上,该类的run()方法中的代码比CacheDispatcher 线程中 run()方法中代码还少,无非就是:
从网络请求队列中拿出一条request。
判断这条请求是否已经结束或者取消了。如果没有那么就是下一步。
开始执行网络请求,并拿到请求的结果。
是否需要缓存结果,如果需要缓存结果,那么就缓存结果。
将请求的结果进行分发。
完成上面的步骤之后,实际上volley的核心代码就分析完成了,其它部分就是细节的问题,比如具体的网络请求是怎么样子的。分发是什么样子的,但这些都是细节问题,不是主干代码。
对于初学者来说,很容易陷入代码汪洋中,即使把代码全部看一篇也无济于事,抓住枝叶,不见主干,分析再多也没有用。典型的例子有:
http://blog.csdn.net/guolin_blog/article/details/17656437
总结:
阅读源代码的方式我总结如下:
首先看一看设计的结构图。
去掉无关紧要的类,比如异常Error相关的类,日志类等。
分析主干代码,比如重点看接口和抽象类而忽略掉其具体的实现,因为优秀的开源库一定是面向接口编程,这些接口和抽象类才是设计的框架所在。
在分析过程中去掉无用的代码,这里的无用指的是那些为了框架稳定性和环境适配的代码,如NUll指针判断,日志记录,异常等。
使用伪代码自己实现一遍框架。
