Caffe
http://caffe.berkeleyvision.org/
Caffe是伯克利人工智能研究室维护的深度学习库。
- 底层用c++实现
- 支持python接口
- 有大量的预训练模型库
- 支持CUDA
- 支持多块GPU
- 只能单机使用
Theano
http://deeplearning.net/software/theano/
Theano是蒙特利尔大学开源的深度学习库。
- 底层用python实现
- 接口只支持python一种
- 有预训练模型库
- 支持CUDA
- 支持多块GPU
- 只能单机使用
Tensorflow
https://www.tensorflow.org/
TensorFlow是Google开源的深度学习框架。
- 底层用c++实现
- 支持 python,c++,Java,Go
- 没有预训练模型库,无法迁移学习
- 支持Cuda
- 支持多块GPU
- 支持集群
- 支持移动设备
MXNET
http://mxnet.io/
MXNET是由开源社区DMLC发起的深度学习项目,目前MXNET已经被amazon AWS指定为官方深度学习平台。
- 底层用c++实现
- 支持Python、R、Scala、Julia、Perl、MATLAB、JavaScript语言。
- 支持CUDA
- 支持多块GPU
- 有预训练模型库,支持迁移学习
- 支持集群
- 支持移动设备
keras
https://keras-cn.readthedocs.io
Keras是一个高层神经网络API,Keras由纯Python编写而成。Keras是一个模型级的库,提供了快速构建深度学习网络的模块。Keras依赖于处理张量的库称为“后端引擎”。Keras提供了两种后端引擎Theano/Tensorflow,并将其函数统一封装,使得用户可以以同一个接口调用不同后端引擎的函数。Keras 为支持快速实验而生,能够把你的idea迅速转换为结果,如果你有如下需求,请选择Keras:
- 简易和快速的原型设计
- 支持CNN和RNN
- 无缝CPU和GPU切换
速度
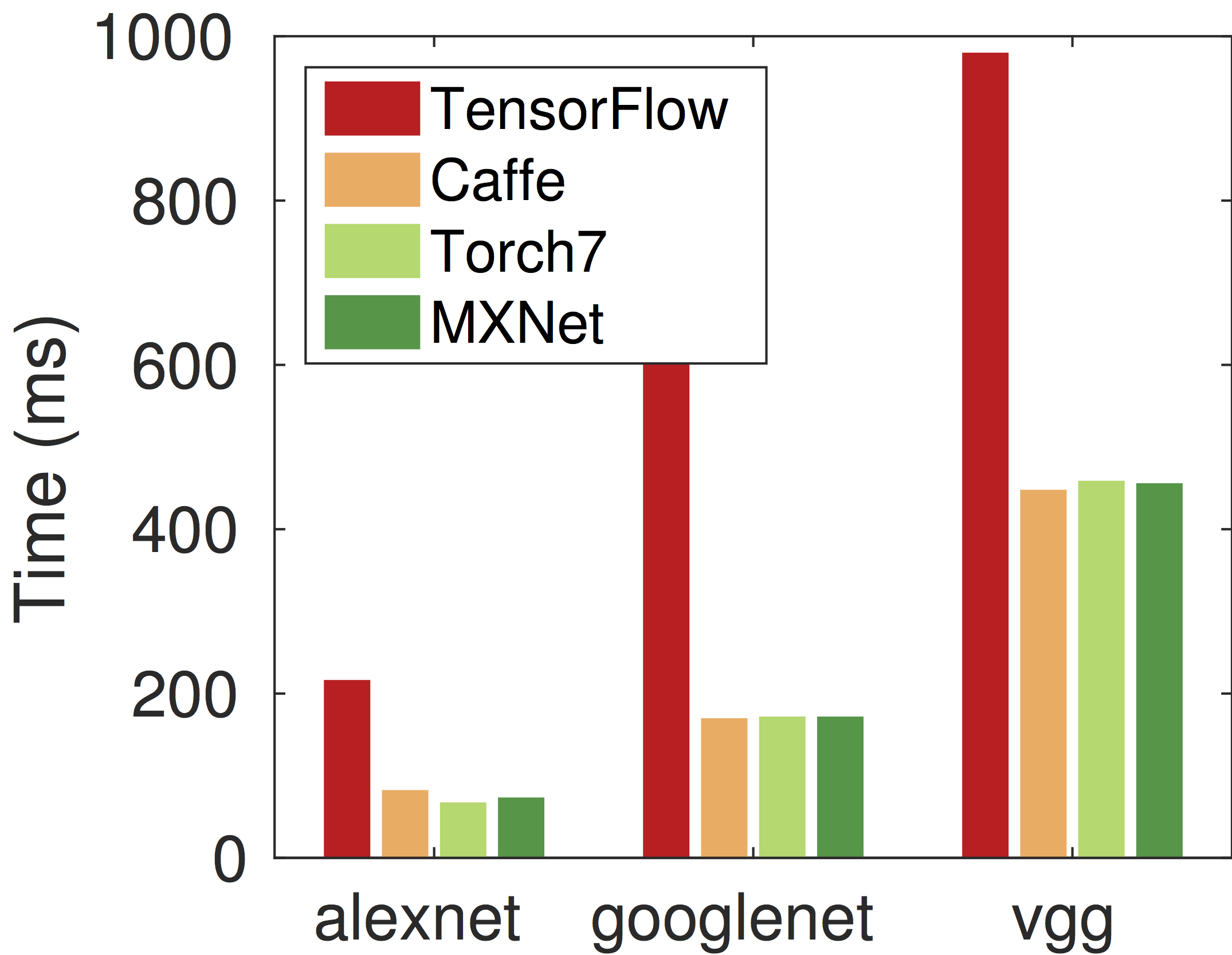
可以看出MXNet,Torch和Caffe三者在性能上不相上下。这个符合预期,因为在单卡上评测的几个网络的绝大部分运算都由CUDA和CUDNN完成。TensorFlow比其他三者都慢2倍以上,这可能由于是低版本的CUDNN和项目刚开源的缘故。
内存占用
Caffe > TensorFlow > MXNET
编程模型比较
编程模型分为命令式和符号式两种。
关于不同编程模型各自的特点,参见:http://mxnet.io/architecture/program_model.html
Caffe是命令式架构,其余都是符号式架构。
非符号架构缺点:
- 命令构架主要的缺点实际上在于人工优化。例如,就地操作必须要人工实现。
- 大多命令构架设计得不够好,比不上符号构架的可表达性。
符号构架优点:
- 符号构架可能可以从依赖图中自动推导优化。
- 一个符号构架可以利用更多内存复用机会,这点 MXNET 做得很好。
- 符号构架能自动计算最佳进度表。
增加新运算符:
- Theano/MXNET: 可以用python内联c语言增加自定义操作,相对简单
- Caffe/TensorFlow: 需要用C++编写自定义操作,比较困难
模型重用性
训练深度网络非常耗时,同时也需要消耗大量资源,所以大多数流行的框架都有自己的预训练模型库,它们能作为初始权重被用于特殊领域或自定义图像的迁移学习或微调深度网络。
- caffe: caffe的模型库是最全的,能够节省科研人员大量的时间,所以论文中引用caffe的最多。
- Theano/Keras:可以使用构建在 Theano 上的高级构架Keras。可以在 Keras 中使用 Caffe 预训练模型权重。
- TensorFlow:不支持预训练模型。
- MXNET:有一个 caffe 转换工具,能够转换基于 caffe 的预训练模型权重,使其可以适应 MXNET。本身也建立了一个模型库。
底层的张量(Tensor)操作支持度
对底层的张量操作支持度越高,则该框架越灵活,能够实现的模型越丰富。但同时也更难使用。
- Theano : 有很多基础操作
- TensorFlow: 最好
- MXNET: 支持较少
- Caffe: 需要自己读懂底层c++代码进行改写
详细的对比见: https://www.leiphone.com/news/201702/T5e31Y2ZpeG1ZtaN.html
