author: Yong Zhang, Ph.D.
institution: Nanyang Technological University
email: yzhang067@e.ntu.edu.sg
licence: MIT licensed. No commercial usage
引子
此文是我发表在Information Sciences上的一篇文章的介绍。
简介
句子建模是很多自然语言理解问题的核心,其旨在建立句子的vector representation,是情感分析,文档摘要,机器翻译等等问题的无法绕开的一环。其实句子建模也可以泛化到文档建模(将整个文档视为一个长句),短语建模(一个短语就是一个短句)甚至单词建模(就是word embeeding)。这里的建模可以简单的理解为寻找``句子''的向量表示。
此文基于CNN对句子建模,提出了一个新的pooling机制, 用于解决max pooling丢失信息的问题。本文的贡献在于以下几方面:
- 提出基于attention的pooling机制,可以有效减少pooling层的信息丢失;
- 结合BLSTM和CNN,使句子向量同时包括前向,后向,和局部信息;
- 模型可以隐形地将不同类别的句子分散。
CNN
Convolutional Neural Network (CNN)可以说是近几年最火的算法之一了,凡做图像必用CNN,因为其良好的local representation的能力可以有效提取到图像的局部特征。最近CNN也被广泛应用到NLP领域,本证明学习能力依然出众。基本的CNN模型可以参见Stanford CS231n课程CNN for visual recogonition。本文使用的基本CNN结构包括一层convolution layer和一层pooling layer。简单的结构依然可以取得不错的结果。我们使用了多个不同窗口的CNN以提取不同长度的局部信息,并最终相互连接,这样丰富了句子的表示信息。
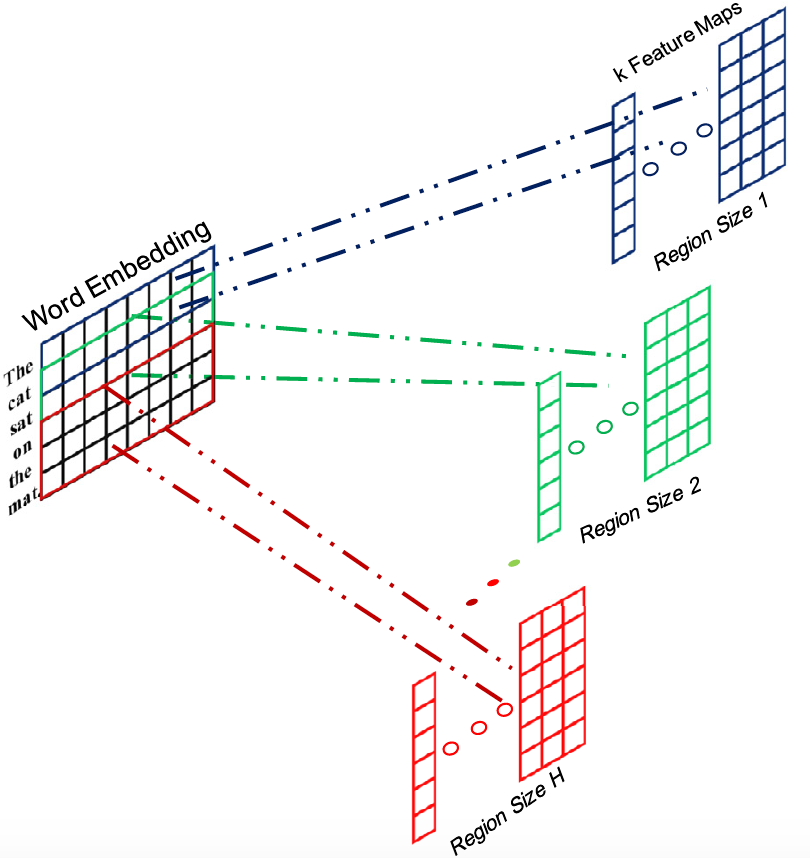
Pooling
Pooling是CNN模型中必不可少的步骤,它可以有效的减少模型中的参数数目从而缓解过拟合的问题。常见的pooling机制包括max-pooling和average-pooling,max-pooling又有多种子方法。下表是对常见的pooling机制的一个总结

可以看到,1-max pooling是取整个feature map的最大值,local max pooling则是将feature分割成几个小区域后对各个小区域求最大值,k-max pooling是取整个feature的最大的k个值。1-max pooling是最简单的也是用的最广泛的,但是它丢失了句子的顺序信息,而且也没能保留词的强度信息。它无法表示一个词是出现了一次还是多次。local-max pooling和k-max pooling都一定程度上缓解了这个问题,但是依然丢失了较多信息。本文借鉴最近很流行的attention机制,尽可能多的保留convolution层后的信息。
Attention pooling
Attention是近年来比较热门的一个方向,它最初源于computer vision领域,是模仿人类视觉的一个杰出成果。人类的眼睛在观察图像是并不会一视同仁,而是将attention放在真正感兴趣的部分。如果机器可以学会只学习最有用的部分,无疑将大大提高学习效率。这就是attention机制想要实现的。Attention已经在computer vision和NLP领域都取得了不错的成绩,感兴趣的可以读读这篇文章Attention and memory in deep learing and nlp。当然仔细阅读相关文献是加深理解的更好办法。
本文希望将attention机制应用到CNN的pooling层以提取最重要的信息。我们的框架如下图。CNN被用于产生句子的局部向量表示,局部表示通过一个attention pooling层得到最后的句子向量表示。Attention weights是通过比较局部向量和一个BLSTM产生的中间句子变量得到的。我们使用BLSTM来产生中间句子变量的原因是文献显示BLSTM本身可以得到较好的句子向量表示。有关LSTM的基本信息可以阅读文章Understanding LSTMs。最后,在预测过程中,BLSTM得到的中间向量也会作为softmax分类器的输入。
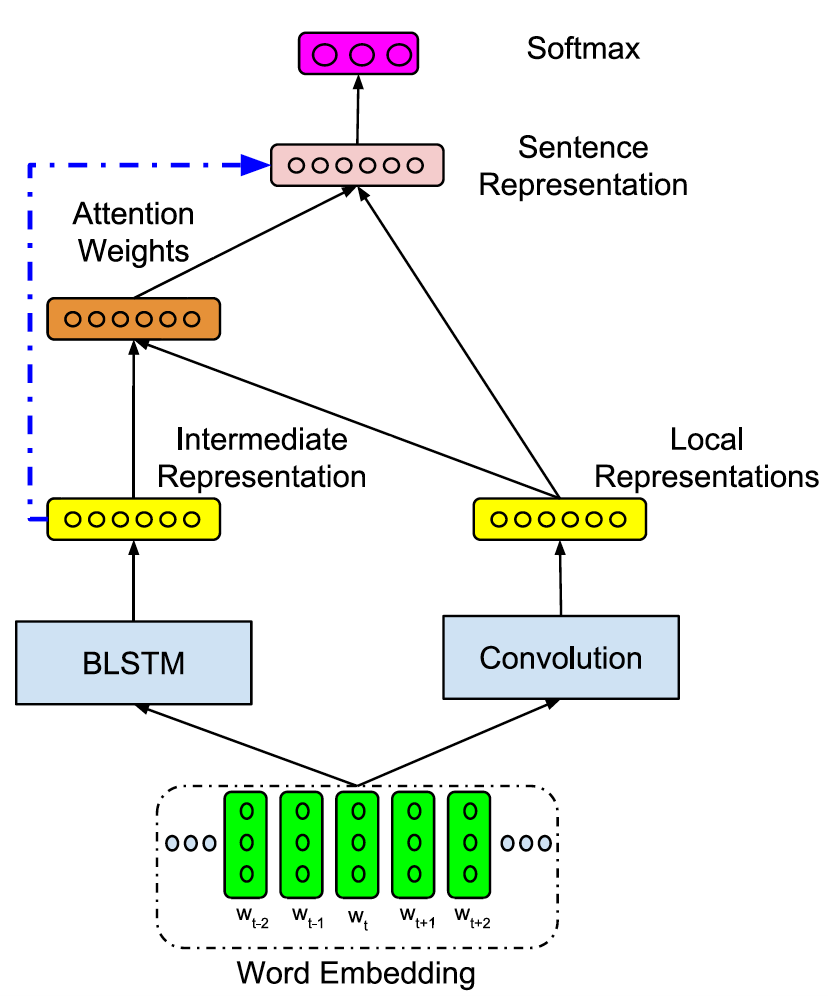
让我们假设CNN得到句子表示为$c = \left[c_1, c_2, \cdots, c_{T}\right] \in {\mathbb{R}^{k \times T}}$(这是pooling以前,所以是个matrix)。k是filter的数目,T是句子的长度。我们在做convolution时选择了`same'模式,意即convlution前后输入和输出的长度相同。
同时我们假设BLSTM得到的句子向量表示为$s'$。我们将$s'$和$c_i$映射到同一个空间就可以对他们进行比较从而得到CNN的局部向量的attention weights了。我们这里使用了cosine similarity进行比较。
$$e_i = sim(c_i,s')$$
$$\alpha_i = \frac{exp(e_{i})}{\sum_{i=1}^{T}exp(e_i)}$$
最终句子的向量表示就是
$$s = \sum_{i=1}^T\alpha_ic_i \in {\mathbb{R}^{k}}$$
Attention pooling可以看做是句子各个词或词组的权重和,每个词的权重代表了该词对句子意思的贡献。模型另外一个重要点在于BLSTM和CNN的结合,BLSTM可以提取句子的前向和后向信息,CNN可以提取到局部信息,那么最终使句子向量同时包括前向,后向,和局部信息。BLSTM的参数在训练过程同时被更新,整个模型是end-to-end的。
Experiment Results
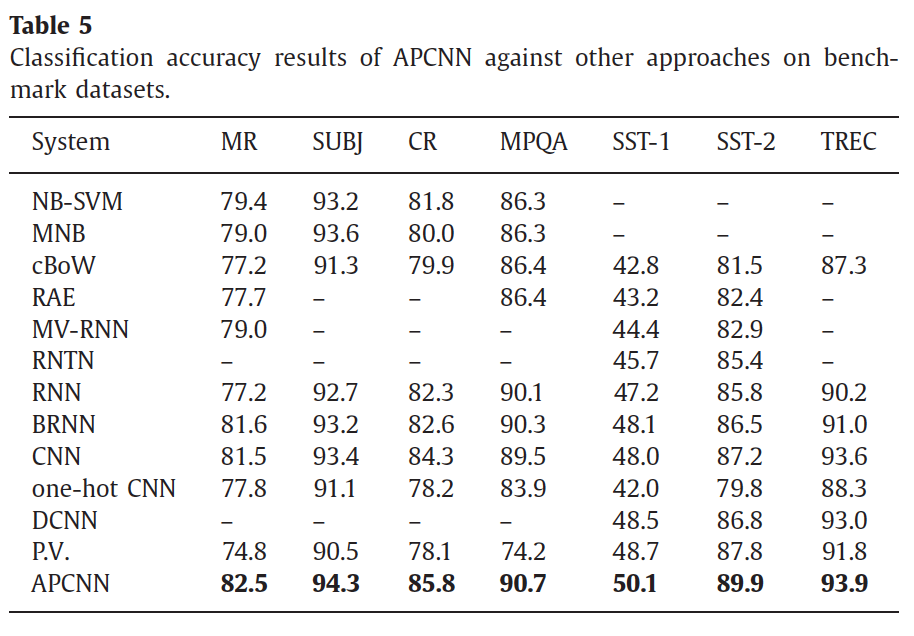
首先是在句子分类问题上的benchmark数据集与state-of-art的方法作比较。胜出!
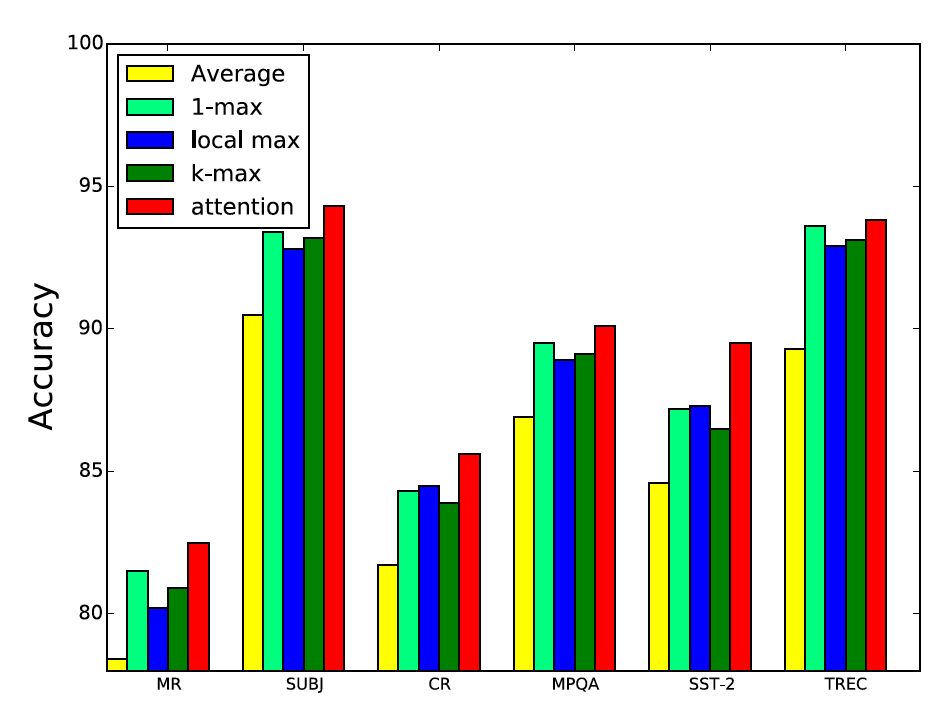
其次是各个pooling机制的比较,胜出!
最后是模型得到的句子向量(SST-2)的一个可视化结果,我们将句子向量通过tsne映射到2-d平面发现来自不同类的句子被有效的分开了。绿色代表negative的句子,红色代表positive的句子。
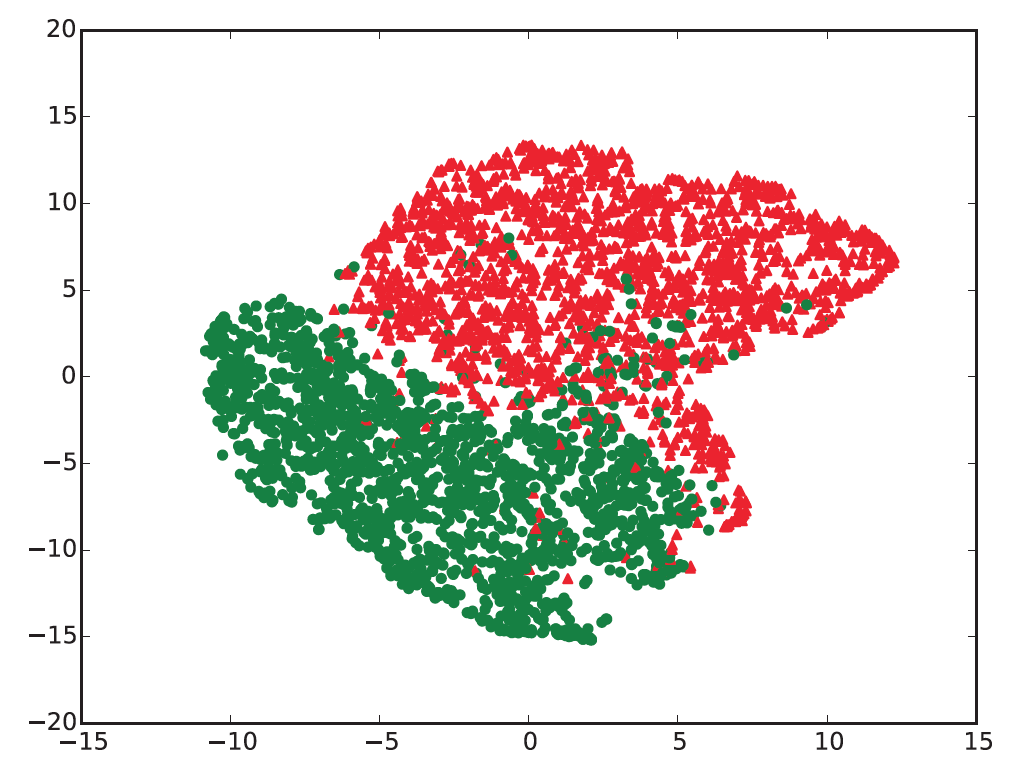
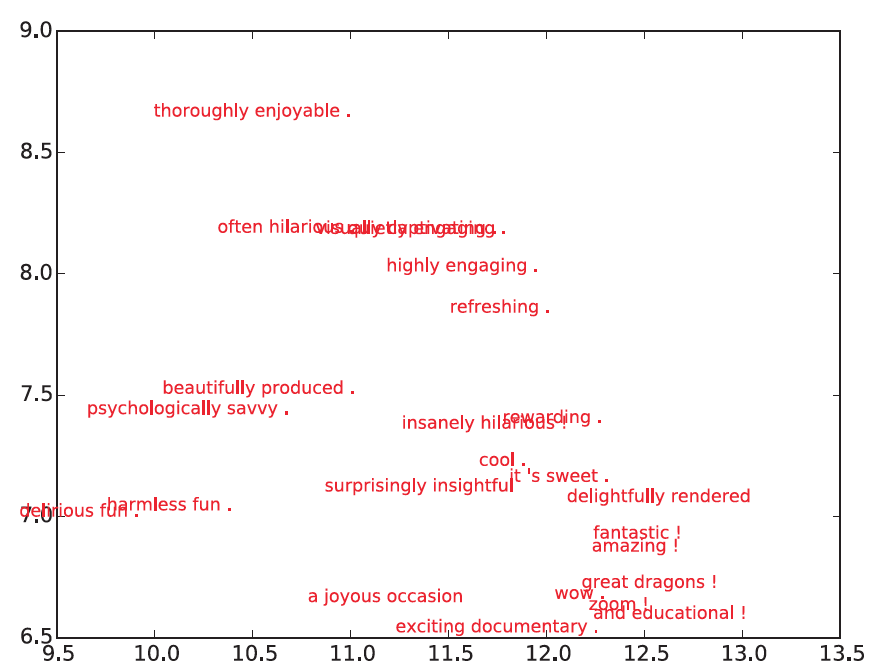
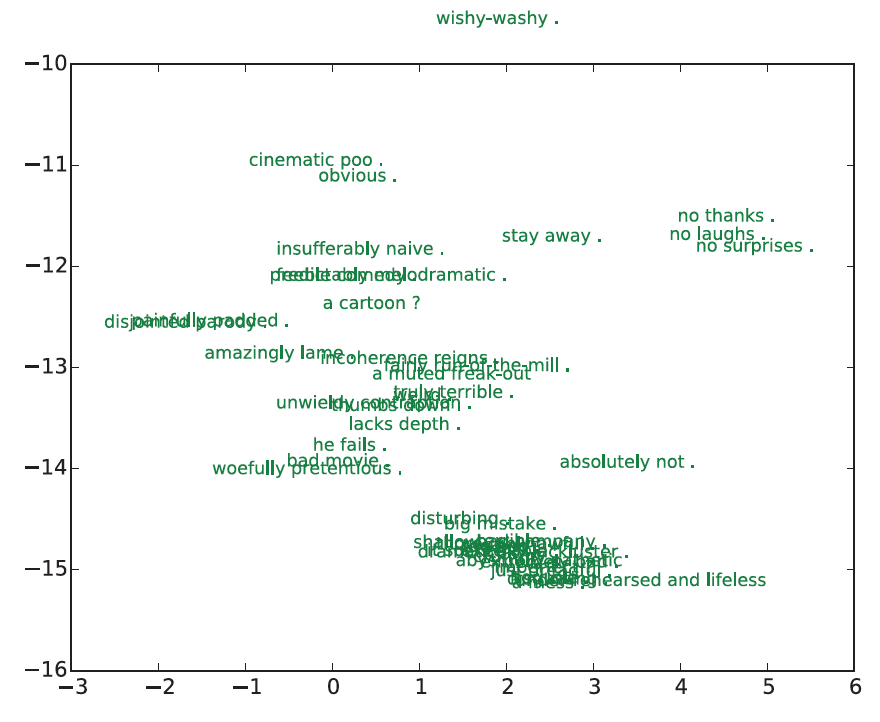
局部放大的效果如下面两张图,我们将点替换成所代表的句子。可以看到,模型做出了很好的判断。
欢迎讨论,如需引用,参见
@article{Er2016388,
title = "Attention pooling-based convolutional neural network for sentence modelling ",
journal = "Information Sciences ",
volume = "373",
number = "",
pages = "388 - 403",
year = "2016",
note = "",
issn = "0020-0255",
doi = "http://dx.doi.org/10.1016/j.ins.2016.08.084",
url = "http://www.sciencedirect.com/science/article/pii/S0020025516306673",
author = "Meng Joo Er and Yong Zhang and Ning Wang and Mahardhika Pratama",
keywords = "Deep learning",
keywords = "Convolutional neural network (CNN)",
keywords = "Long-short term memory (LSTM)",
keywords = "Sentence modelling",
keywords = "Text classification "
}
