我们会介绍几种方法,帮助你重构代码,以适配使用Lambda表达式,让你的代码具备更好的可读性和灵活性。除此之外,我们还会讨论目前比较流行的几种面向对象的设计模式,
包括策略模式、模板方法模式、观察者模式、责任链模式,以及工厂模式,在结合Lambda表达式之后变得更简洁的情况。最后,我们会介绍如何测试和调试使用Lambda表达式和Stream API的代码。
1. 为改善可读性和灵活性重构代码
1.1 改善代码的可读性
Java 8的新特性也可以帮助提升代码的可读性:
- 使用Java 8,你可以减少冗长的代码,让代码更易于理解
- 通过方法引用和Stream API,你的代码会变得更直观
利用Lambda表达式、方法引用以及Stream改善程序代码的可读性:
- 重构代码,用Lambda表达式取代匿名类
- 用方法引用重构Lambda表达式
- 用Stream API重构命令式的数据处理
1.2 从匿名内部类到Lambda表达式的转换
将实现单一抽象方法的匿名类转换为Lambda表达式
// 传统的方式,使用匿名类
Runnable r1 = new Runnable(){
public void run(){
System.out.println("Hello");
}
}
// 新的方式,使用Lambda表达式
Runnable r2 = () -> System.out.println("Hello");
匿名 类和Lambda表达式中的this和super的含义是不同的。在匿名类中,this代表的是类自身,但是在Lambda中,它代表的是包含类。其次,匿名类可以屏蔽包含类的变量,而Lambda表达式不能(它们会导致编译错误),如下面这段代码:
int a = 10;
Runnable r1 = () -> {
int a = 2; // 编译错误
System.out.println(a);
};
Runnable r2 = new Runnable() {
public void run() {
int a = 2; // 正常
System.out.println(a);
}
}
在涉及重的上下文里,将匿名类转换为Lambda表达式可能导致最终的代码更加晦涩。实际上,匿名类的类型是在初始化时确定的,而Lambda的类型取决于它的上下文。通过下面这个例子,我们可以了解问题是如何发生的。我们假设你用与Runnable同样的签名声明了一个函数接口,我们称之为Task:
interface Task{
public void execute();
}
public static void doSomething(Runnable r){ r.run(); }
public static void doSomething(Task a){ a.execute(); }
doSomething(new Task() {
public void execute() {
System.out.println("Danger danger!!");
}
});
// doSomething(Runnable) 和 doSomething(Task) 都匹配该类型
doSomething(() -> System.out.println("Danger danger!!"));
// 使用显式的类型转换来解决这种模棱两可的情况
doSomething((Task)() -> System.out.println("Danger danger!!"));
目前大多数的集成开发环境,比如NetBeans和IntelliJ都支持这种重构,它们能自动地帮你检查,避免发生这些问题。
1.3 从Lambda表达式到方法引用的转换
Map<CaloricLevel, List<Dish>> dishesByCaloricLevel =
menu.stream()
.collect(
groupingBy(dish -> {
if (dish.getCalories() <= 400) return CaloricLevel.DIET;
else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL;
else return CaloricLevel.FAT;
}));
将Lambda表达式的内容抽取到一个单独的方法中,将其作为参数传递给groupingBy方法。变换之后,代码变得更加简洁,程序的意图也更加清晰了。
Map<CaloricLevel, List<Dish>> dishesByCaloricLevel = menu.stream().collect(groupingBy(Dish::getCaloricLevel));
1.4 从命令式的数据处理切换到Stream
我们建议你将所有使用迭代器这种数据处理模式处理集合的代码都转换成Stream API的方式。为什么呢?
Stream API能更清晰地表达数据处理管道的意图。除此之外,通过短路和延迟载入以及利用第7章介绍的现代计算机的多核架构,我们可以对Stream进行优化。
// 命令式版本
List<String> dishNames = new ArrayList<>();
for(Dish dish: menu){
if(dish.getCalories() > 300){
dishNames.add(dish.getName());
}
}
// 使用Stream API
menu.parallelStream()
.filter(d -> d.getCalories() > 300)
.map(Dish::getName)
.collect(toList());
1.5 增加代码的灵活性
没有函数式接口就无法使用Lambda表达式,因此代码中需要引入函数式接口。引入函数式接口的两种通用模式:
- 有条件的延迟执行
- 环绕执行
2. 使用Lambda重构面向对象的设计模式
使用Lambda表达式后,很多现存的略显臃肿的面向对象设计模式能够用更精简的方式实现了。这一节中,我们会针对五个设计模式展开讨论,它们分别是:
- 策略模式
- 模板方法
- 观察者模式
- 责任链模式
- 工厂模式
2.1 策略模式
策略模式代表了解决一类算法的通用解决方案,你可以在运行时选择使用哪种方案。策略模式包含三部分内容,如图所示。
- 一个代表某个算法的接口(它是策略模式的接口)。
- 一个或多个该接口的具体实现,它们代表了算法的多种实现(比如,实体类ConcreteStrategyA或者ConcreteStrategyB)。
- 一个或多个使用策略对象的客户。

public interface ValidationStrategy {
boolean execute(String s);
}
public class IsAllLowerCase implements ValidationStrategy {
@Override
public boolean execute(String s) {
return s.matches("[a-z]+");
}
}
public class IsNumber implements ValidationStrategy {
@Override
public boolean execute(String s) {
return s.matches("\\d+");
}
}
public class Validator {
private final ValidationStrategy strategy;
public Validator(ValidationStrategy strategy) {
this.strategy = strategy;
}
public boolean validate(String s) {
return strategy.execute(s);
}
}
public class StrategyDemo {
public static void main(String[] args) {
Validator numericValidator = new Validator(new IsNumber());
boolean b1 = numericValidator.validate("aaaa");
Validator lowerCaseValidator = new Validator(new IsAllLowerCase());
boolean b2 = lowerCaseValidator.validate("bbbb");
System.out.println(b1 + " " + b2);
Validator numericValidator1 = new Validator((String s) -> s.matches("[a-z]+"));
boolean b11 = numericValidator1.validate("aaaa");
Validator lowerCaseValidator1 = new Validator((String s) -> s.matches("\\d+"));
boolean b21 = lowerCaseValidator.validate("bbbb");
System.out.println(b11 + " " + b21);
}
}
2.2 模板方法
模板 方法模式在你“希望使用这个算法,但是需要对其中的某些行进行改进,才能达到希望的效果” 时是非常有用的。
public abstract class OnlineBanking {
public void processCustomer(int id) {
Customer c = DataUtil.getCustomerWithId(id);
makeCustomerHappy(c);
}
abstract void makeCustomerHappy(Customer c);
}
public class OnlineBankingLambda {
public void processCustomer(int id, Consumer<Customer> consumer) {
Customer c = DataUtil.getCustomerWithId(id);
consumer.accept(c);
}
}
public class TemplateMethod {
public static void main(String[] args) {
new OnlineBanking() {
@Override
void makeCustomerHappy(Customer c) {
System.out.println(c.getName() + " happy!");
}
}.processCustomer(1);
new OnlineBankingLambda().processCustomer(1, (Customer c) -> System.out.println(c.getName() + " happy!"));
}
}
2.3 观察者模式
观察者模式是一种比较常见的方案,某些事件发生时(比如状态转变),如果一个对象(通常我们称之为主题)需要自动地通知其他多个对象(称为观察者),就会采用该方案。

public interface Observer {
void notify(String tweet);
}
public class NYTime implements Observer {
@Override
public void notify(String tweet) {
if(tweet != null && tweet.contains("money")){
System.out.println("Breaking news in NY! " + tweet);
}
}
}
public class Guardian implements Observer {
@Override
public void notify(String tweet) {
if(tweet != null && tweet.contains("queen")){
System.out.println("Yet another news in London... " + tweet);
}
}
}
public class LeMonde implements Observer {
@Override
public void notify(String tweet) {
if(tweet != null && tweet.contains("wine")){
System.out.println("Today cheese, wine and news! " + tweet);
}
}
}
public interface Subject {
void registerObserver(Observer o);
void nofityObservers(String tweet);
}
public class Feed implements Subject {
private final List<Observer> observers = new ArrayList<>();
@Override
public void registerObserver(Observer o) {
this.observers.add(o);
}
@Override
public void nofityObservers(String tweet) {
observers.forEach(o -> o.notify(tweet));
}
}
public class ObserverDemo {
public static void main(String[] args) {
Feed f = new Feed();
f.registerObserver(new NYTime());
f.registerObserver(new Guardian());
f.registerObserver(new LeMonde());
f.nofityObservers("The queen said her favourite book is Java 8 in Action!");
f.registerObserver((String tweet) -> {
if (tweet != null && tweet.contains("money")) {
System.out.println("Breaking news in NY! " + tweet);
}
});
f.registerObserver((String tweet) -> {
if (tweet != null && tweet.contains("queen")) {
System.out.println("Yet another news in London... " + tweet);
}
});
}
}
2.4 责任链模式
责任链模式是一种创建处理对象序列(比如操作序列)的通用方案。一个处理对象可能需要在完成一些工作之后,将结果传递给另一个对象,这个对象接着做一些工作,再转交给下一个处理对象,以此类推。
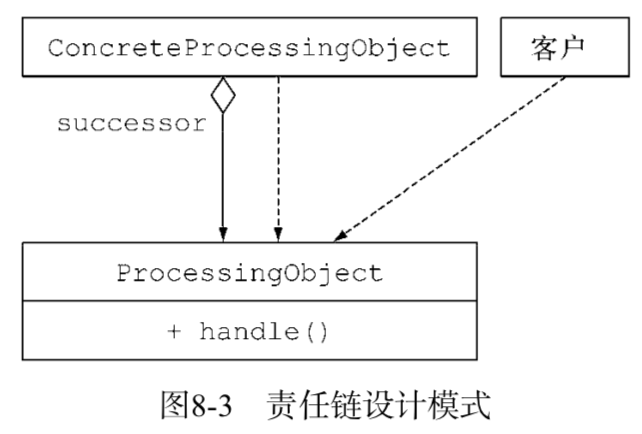
public abstract class ProcessingObject<T> {
protected ProcessingObject<T> successor;
public void setSuccessor(ProcessingObject<T> successor) {
this.successor = successor;
}
public T handle(T input) {
T r = handleWork(input);
if (successor != null) {
return successor.handle(r);
}
return r;
}
abstract protected T handleWork(T input);
}
public class HeaderTextProcessing extends ProcessingObject<String> {
@Override
protected String handleWork(String input) {
return "From Raoul, Mario and Alan: " + input;
}
}
public class SpellCheckerProcessing extends ProcessingObject<String> {
@Override
protected String handleWork(String input) {
return input.replaceAll("labda", "lambda");
}
}
public class ChainOfResponsibilityDemo {
public static void main(String[] args) {
ProcessingObject<String> p1 = new HeaderTextProcessing();
ProcessingObject<String> p2 = new SpellCheckerProcessing();
p1.setSuccessor(p2);
String result = p1.handle("Aren't labdas really sexy?!!");
System.out.println(result);
UnaryOperator<String> headerProcessing = (String text) -> "From Raoul, Mario and Alan: " + text;
UnaryOperator<String> spellCheckerProcessing = (String text) -> text.replaceAll("labda", "lambda");
Function<String, String> pipeline = headerProcessing.andThen(spellCheckerProcessing);
String result1 = pipeline.apply("Aren't labdas really sexy?!!");
System.out.println(result1);
}
}
2.5 工厂模式
使用工厂模式,你无需向客户暴露实例化的逻辑就能完成对象的创建。
public interface Product {}
@Data
public class Loan implements Product {}
@Data
public class Stock implements Product {}
@Data
public class Bond implements Product {}
public class ProductFactory {
public static Product createProduct(String name) {
switch (name) {
case "loan":
return new Loan();
case "stock":
return new Stock();
case "bond":
return new Bond();
default:
throw new RuntimeException("No such product " + name);
}
}
public static void main(String[] args) {
Product p = ProductFactory.createProduct("loan");
System.out.println(p);
}
}
public class ProductFactoryLambda {
private final static Map<String, Supplier<Product>> map = new HashMap<>();
static {
map.put("loan", Loan::new);
map.put("stock", Stock::new);
map.put("bond", Bond::new);
}
public static Product createProduct(String name) {
Supplier<Product> p = map.get(name);
if (p != null) {
return p.get();
}
throw new IllegalArgumentException("No such product " + name);
}
public static void main(String[] args) {
Product p = ProductFactoryLambda.createProduct("loan");
System.out.println(p);
}
}
3. 测试Lambda表达式
略
4. 调试Lambda表达式
4.1 查看栈跟踪
public class Debugging{ 11 public static void main(String[] args) {
List<Point> points = Arrays.asList(new Point(12, 2), null);
points.stream().map(p -> p.getX()).forEach(System.out::println); }
}
运行这段代码会产生下面的栈跟踪:
Exception in thread "main" java.lang.NullPointerException
at Debugging.lambda$main$0(Debugging.java:6)
at Debugging$$Lambda$5/284720968.apply(Unknown Source)
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline
.java:193)
at java.util.Spliterators$ArraySpliterator.forEachRemaining(Spliterators
.java:948)
我们需要特别注意,涉及Lambda表达式的栈可能非常难理解。这是Java编译器未来版本可以改进的一个方面。
4.2 使用日志调试
peek的设计初衷就是在流的每个元素恢复运行之前,插入执行一个动作。但是它不像forEach那样恢复整个流的运行,而是在一个元素上完成操作之后,它只会将操作顺承到流水线中的下一个操作。图8-4解释了peek的操作流程。
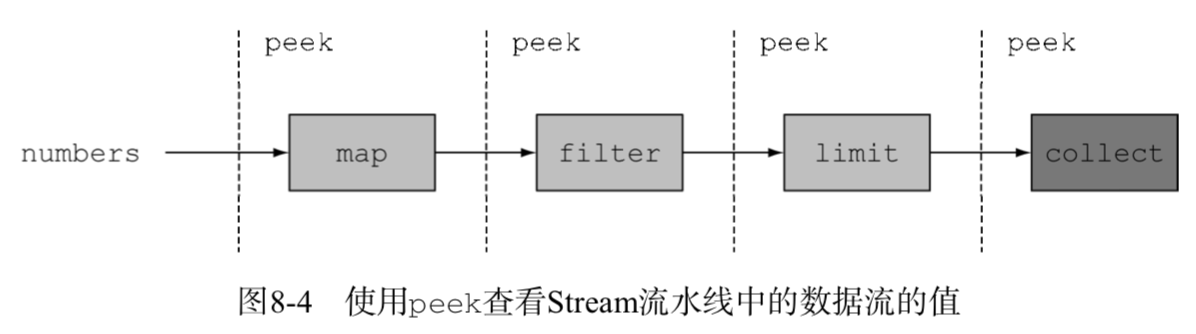
List<Integer> result = numbers.stream()
.peek(x -> System.out.println("from stream: " + x))
.map(x -> x + 17)
.peek(x -> System.out.println("after map: " + x))
.filter(x -> x % 2 == 0)
.peek(x -> System.out.println("after filter: " + x))
.limit(3)
.peek(x -> System.out.println("after limit: " + x))
.collect(toList());
输出结果:
from stream: 2
after map: 19
from stream: 3
after map: 20
after filter: 20
after limit: 20
from stream: 4
after map: 21
from stream: 5
after map: 22
after filter: 22
after limit: 22
5. 小结
- Lambda表达式能提升代码的可读性和灵活性。
- 如果你的代码中使用了匿名类,尽量用Lambda表达式替换它们,但是要注意二者间语义的微妙差别,比如关键字this,以及变量隐藏。
- Lambda表达式比起来,方法引用的可读性更好。
- 尽量使用Stream API替换迭代式的集合处理。
- Lambda表达式有助于避免使用面向对象设计模式时容易出现的化的模板代码,典型的比如策略模式、模板方法、观察者模式、责任链模式,以及工厂模式。
- 即使采用了Lambda表达式,也同样可以进行单元测试,但是通常你应该关注使用了Lambda表达式的方法的行为。
- 尽量将复杂的Lambda表达式抽象到普通方法中。
- Lambda表达式会让栈跟踪的分析变得更为复杂。
- 流提供的peek方法在分析Stream流水线时,能将中间变量的值输出到日志中,是非常有用的工具。
Tips
本文同步发表在公众号,欢迎大家关注!😁
后续笔记欢迎关注获取第一时间更新!

