# Mongodb是什么?
Mongodb是一个非关系性数据库,是c++编写而成的,其主要作用是给WEB应用提供可扩展的高性能的分布式数据存储解决方案,当然,mongodb是属于面向文档性的免费数据库,比较多用于数据采集和分散处理,在大数据方面应用比较广泛
Mongodb的特点:
优点特性:高可用,可水平扩展,先来讲讲水平扩展,可扩展的方式是可用通过廉价的服务器对系统进行扩展,在这种环境下每单台服务器配置不会很高,相对比与单台高配置的服务器来承载系统,用廉价服务器组成的集群会比单台服务器提供更高,更强大的系统容载量
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Xu9pnCK5-1574675152442)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1574653919792.png)]
## Mongodb的复制集:
他的复制集是从传统的**主从结构**演变而来的,是由一组相同数据集的mongodb实例组成的集群。
> 读写分离的主从结构:读写分离的基本原理是让主数据库进行:增、删(写)、改操作操作,而从数据库则做查询、读取操作,就以sql为例子,猪库负责写数据,读数据,度库则仅负责读数据,每次有写库操作,同步更新到读库,写库只有一个,读库有多个,采用日志同步的方式就可以实现主库和多个读库之间的数据同步了
# MongoDB复制集节点角色类型:
primary:主要的
second :次要的
1、标准节点:参与primary选举,当主节点宕机,或者停止服务的时候会自动让入primary。
2、被动节点:只能成为second不能参与选举,被设置伟被动节点这不能参与成为主服务器的选举。
3、仲裁节点:复制投票选举,不妨数据库,保证标准节点的投票数不会相同
测试环境:
> 系统:centos6.8
>
> mongo版本:mongodb-linux-x86_64-rhe162-4.0.6.tgz
>
> 机器ip环境:192.168.57.201、192.168.57.202、192.168.57.203
安装成功后创建Mongodb的配置文件(文件名: mongo.conf)
在配置文件里面有
fork :进程
dbpath:存放数据的目录
part:绑定的端口
bind:绑定的ip
logpath:绑定的日志文件路径
logappend:日志是否可读
replSet:复制集的名子,可自己起名字,几台复制集的名字一定要一样,不然会出问题
smalltiles:是否当做小文件来存储,一般文件比较多的话用小文件比较合适
配置完成3台服务器的配置文件和对应的数据日志目录后,我们来启动mongo服务器
`./mongo --config /opt/mongo/mongo.conf`
启动后用这行命令来检查下是否启动成功:
`netstat -ntlp`
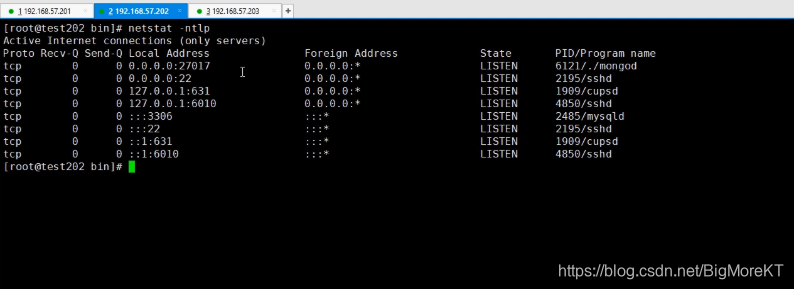
启动成功后我们来进入mongo里面进行配置下复制集:
直接用 ./mongo 就可以进入mongo里面设置了,把下面定义的直接复制进去
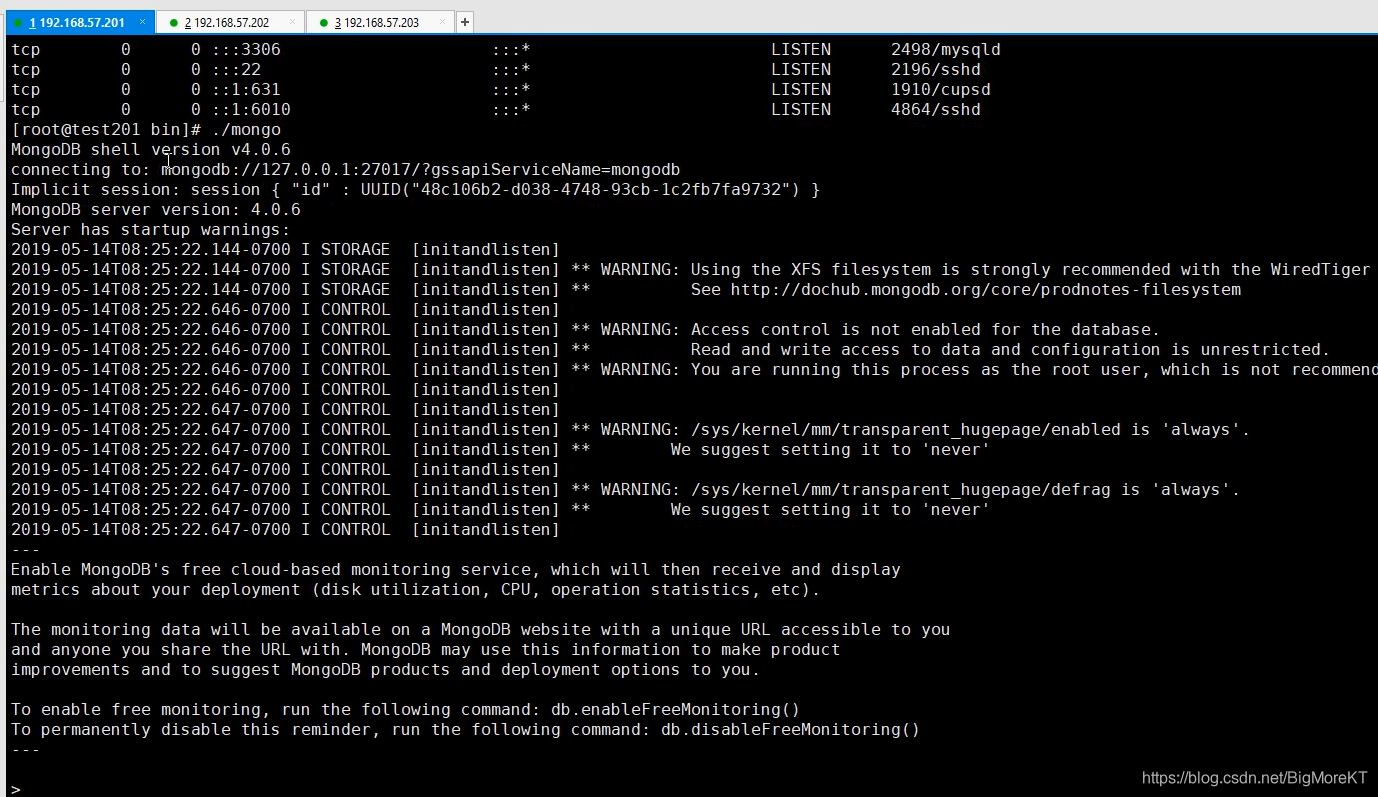
```java
var rsconf={
_id:'yidian_repl',
members:[
{
_id:1, //成员的id
host:'192.168.57.201:27017'//成员所属节点的ip以及改成员启动服务时所占用端口
},
{
_id:2,
host:'192.168.57.202:27017'
},
{
_id:3,
host:'19+2.168.57.203:27017'
},
]
}
```
```java
//然后开始初始化配置文件(加载rsconf配置文件)
rs.initiate(reconf)
//状态查看
rs.status();
```
通过查看状态可以看到我们一些复制集的节点信息
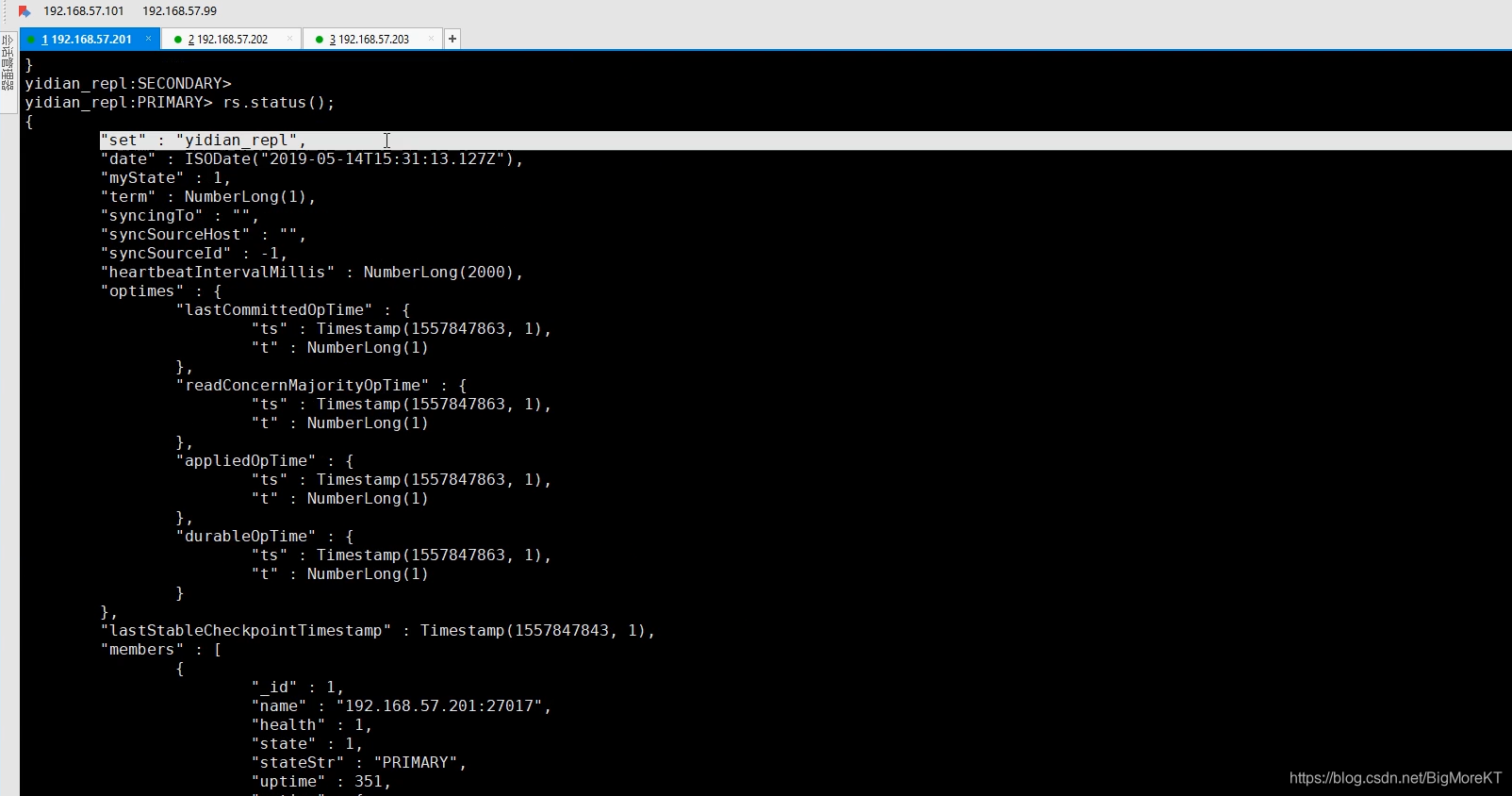
查看成功后来插入几条数据测试测试下
```shell
#添加数据命令
db.movies.insert([{"title":,"fzzlm","year":1975,"imdb_rating":8.4},
{"title":,"fzzlm","year":1989,"imdb_rating:"7.6}]);
#由于mongodb是非结构化数据库,我们可以直接用json格式来插入数据
#查看数据命令
db.movies.find().pretty();
```
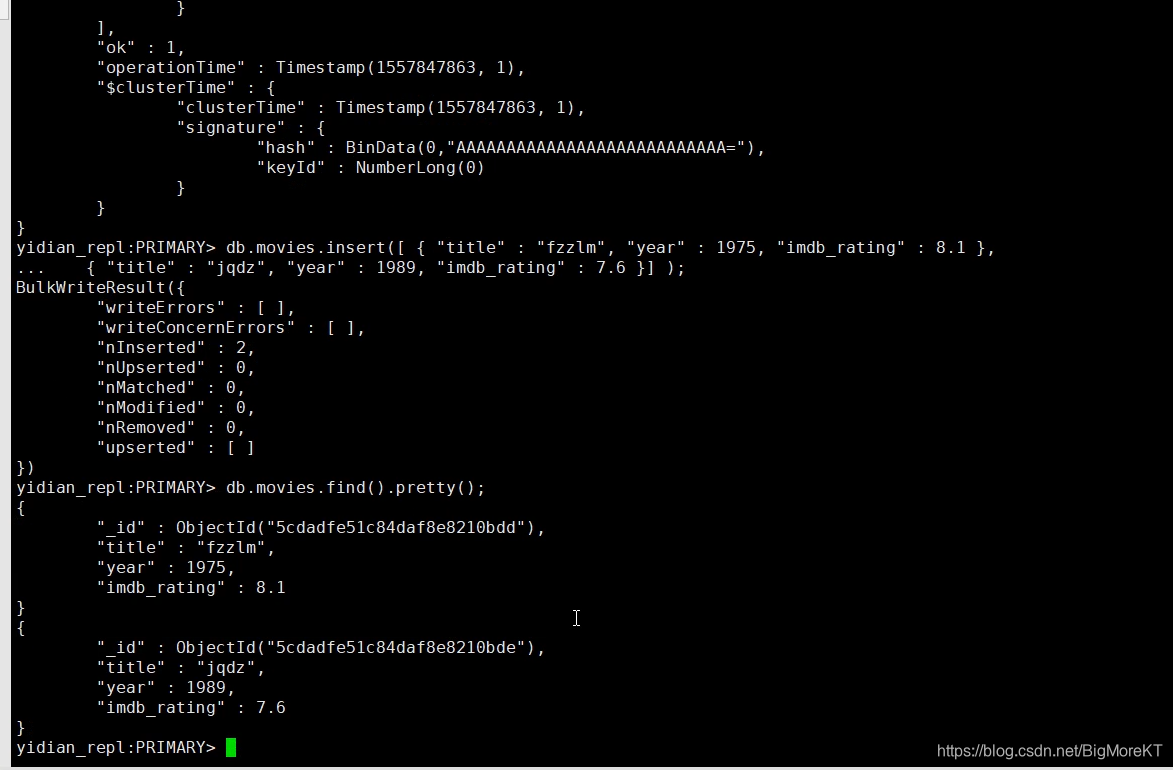
从这里可以看到我们的数据插入成功了,id号是自动生成的。
然后我们到另外的从服务器上面查看下是否同步成功
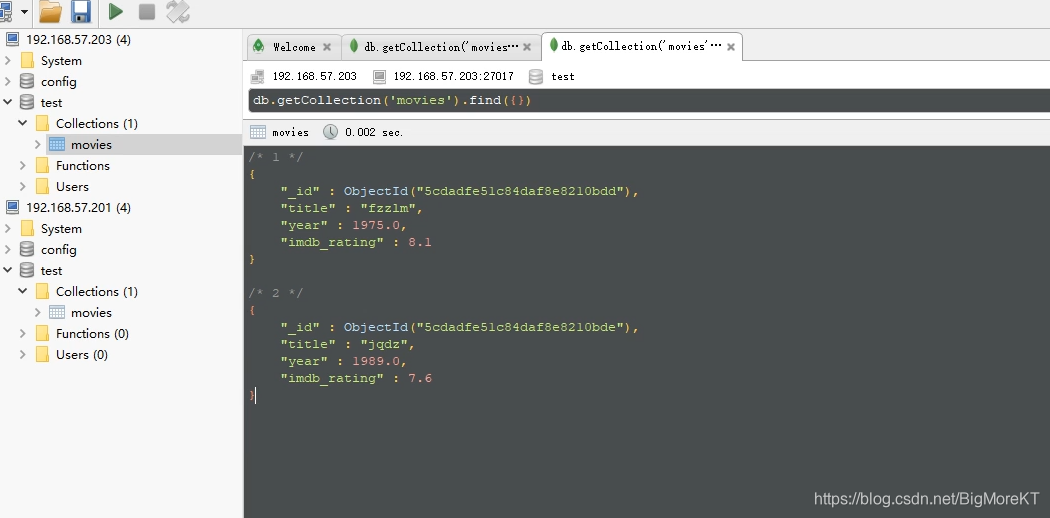
从这里可以明显看得出已经数据同步过来了,那么数据复制集的环境是已经成功了,数据成功的同步到从服务器里面了
当然,一开始复制集的从节点默认禁止查询,这个时候我们需要去设置下
```shell
rs.slaveOk();#设置允许从节点查询
```
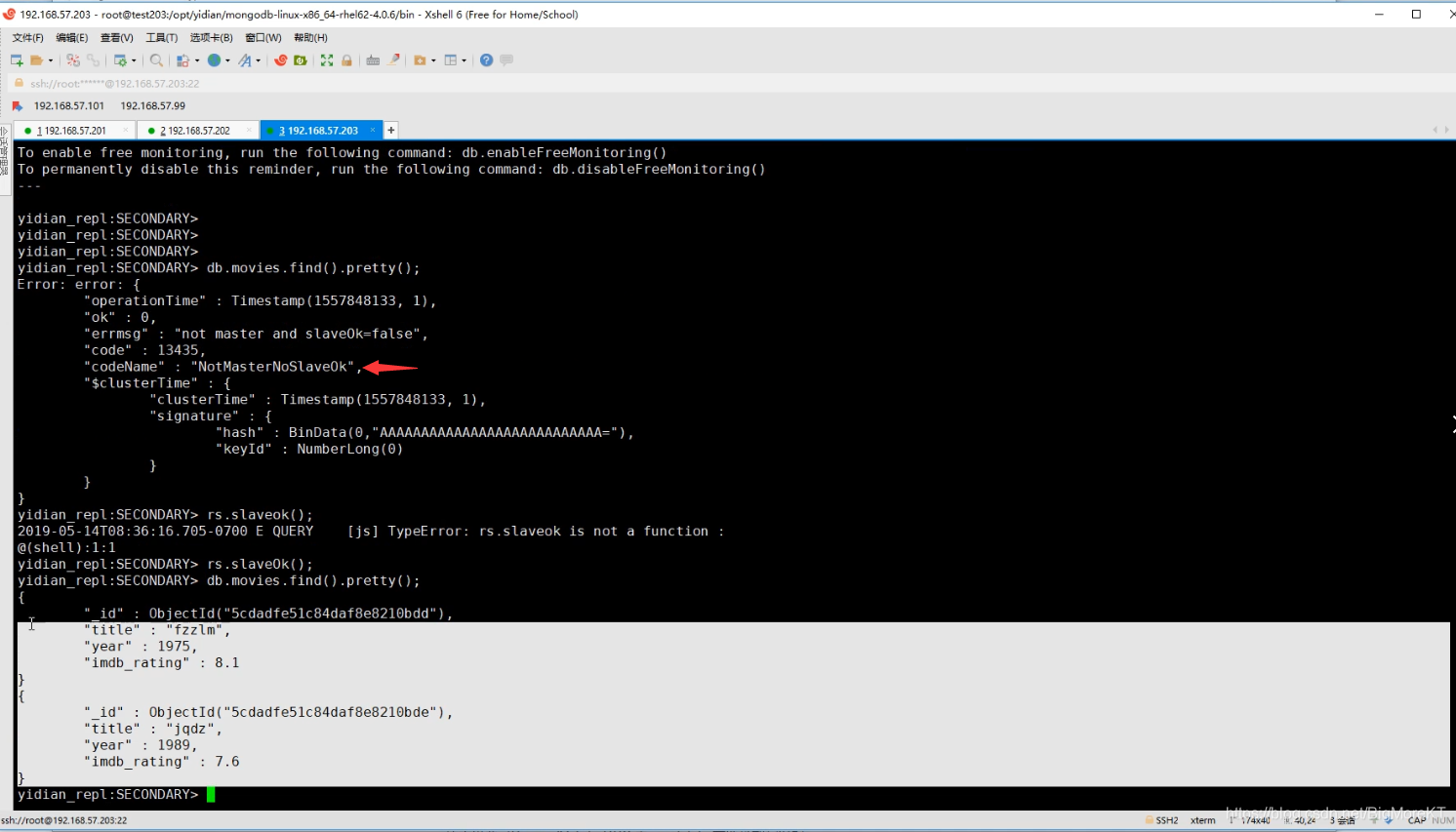
允许后就能成功查询到数据了
```shell
#添加节点
rs.add("ip:port");#ip地址和端口
rs.remove("ip:port")
#查看配置信息
rs.config();
```
mongodDB复制集的使用总结,文章是自己学习日记,有错误的地方大牛看到了还请及时告诉我下,谢谢
