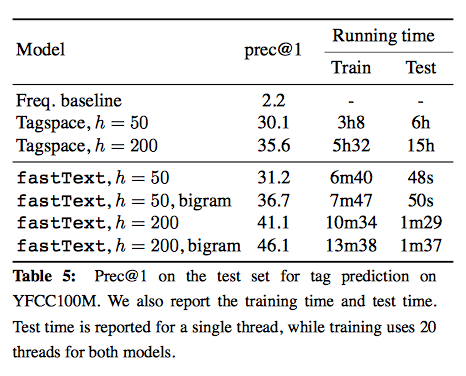
该算法由facebook在2016年开源,典型应用场景是“带监督的文本分类问题”。

模型
模型的优化目标如下:
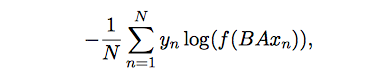
其中,$<x_n,y_n>$是一条训练样本,$y_n$是训练目标,$x_n$是normalized bag of features。矩阵参数A是基于word的look-up table,也就是A是词的embedding向量。$Ax_n$矩阵运算的数学意义是将word的embedding向量找到后相加或者取平均,得到hidden向量。矩阵参数B是函数f的参数,函数f是一个多分类问题,所以$f(BAx_n)$是一个多分类的线性函数。优化目标是使的这个多分类问题的似然越大越好。
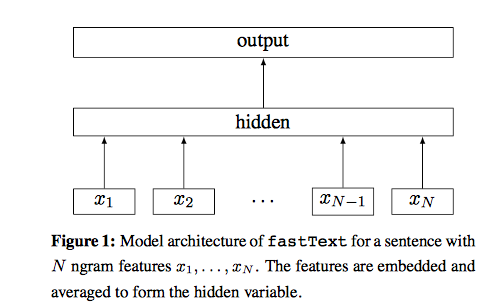
将优化目标表示为图模型如下:
与word2vec的区别
这个模型与word2vec有很多相似的地方,也有很多不相似的地方。相似地方让这两种算法不同的地方让这两
相似的地方:
- 图模型结构很像,都是采用embedding向量的形式,得到word的隐向量表达。
- 都采用很多相似的优化方法,比如使用Hierarchical softmax优化训练和预测中的打分速度。
不同的地方:
- word2vec是一个无监督算法,而fasttext是一个有监督算法。word2vec的学习目标是skip的word,而fasttext的学习目标是人工标注的分类结果。
- word2vec要求训练样本带有“序”的属性,而fasttext使用的是bag of words的思想,使用的是n-gram的无序属性。
V.S. 深度神经网络
fasttext只有1层神经网络,属于所谓的shallow learning,但是fasttext的效果并不差,而且具备学习和预测速度快的优势,在工业界这点非常重要。
- 比一般的神经网络模型的精确度还要高。
- 训练和评估速度快几百倍。10分钟内就可以在一台多核CPU训练10亿词汇。1分种内完成100万句子在31万中类型中的分类。