谈起闭包,它可是JavaScript两个核心技术之一(异步和闭包),在面试以及实际应用当中,我们都离不开它们,甚至可以说它们是衡量js工程师实力的一个重要指标。下面我们就罗列闭包的几个常见问题,从回答问题的角度来理解和定义你们心中的闭包。
问题如下:
1.什么是闭包?
2.闭包的原理可不可以说一下?
3.你是怎样使用闭包的?
闭包的介绍
我们先看看几本书中的大致介绍:
1.闭包是指有权访问另一个函数作用域中的变量的函数
2.函数对象可以通过作用域关联起来,函数体内的变量都可以保存在函数作用域内,这在计算机科学文献中称为“闭包”,所有的javascirpt函数都是闭包
3.闭包是基于词法作用域书写代码时所产生的必然结果。
4.. 函数可以通过作用域链相互关联起来,函数内部的变量可以保存在其他函数作用域内,这种特性在计算机科学文献中称为闭包。
可见,它们各有各自的定义,但要说明的意思大同小异。笔者在这之前对它是知其然而不知其所以然,最后用了一天的时间从词法作用域到作用域链的概念再到闭包的形成做了一次总的梳理,发现做人好清晰了...。
下面让我们抛开这些抽象而又晦涩难懂的表述,从头开始理解,内化最后总结出自己的一段关于闭包的句子。我想这对面试以及充实开发者自身的理论知识非常有帮助。
闭包的构成
词法作用域
要理解词法作用域,我们不得不说起JS的编译阶段,大家都知道JS是弱类型语言,所谓弱类型是指不用预定义变量的储存类型,并不能完全概括JS或与其他语言的区别,在这里我们引用黄皮书(《你不知道的javascript》)上的给出的解释编译语言。
编译语言
编译语言在执行之前必须要经历三个阶段,这三个阶段就像过滤器一样,把我们写的代码转换成语言内部特定的可执行代码。就比如我们写的代码是var a = 1;,而JS引擎内部定义的格式是var,a,=,1 那在编译阶段就需要把它们进行转换。这只是一个比喻,而事实上这只是在编译阶段的第一个阶段所做的事情。下面我们概括一下,三个阶段分别做了些什么。
- 分词/词法分析(Tokenizing/Lexing)
这就是我们上面讲的一样,其实我们写的代码就是字符串,在编译的第一个阶段里,把这些字符串转成词法单元(toekn),词法单元我们可以想象成我们上面分解的表达式那样。(注意这个步骤有两种可能性,当前这属于分词,而词法分析,会在下面和词法作用域一起说。)
- 解析/语法分析(Parsing)
在有了词法单元之后,JS还需要继续分解代码中的语法以便为JS引擎减轻负担(总不能在引擎运行的过程中让它承受这么多轮的转换规则吧?) ,通过词法单元生成了一个抽象语法树(Abstract Syntax Tree),它的作用是为JS引擎构造出一份程序语法树,我们简称为AST。这时我们不禁联想到Dom树(扯得有点远),没错它们都是树,以var,a,=,1为例,它会以层为单元划分他们,例如: 顶层有一个 stepA 里面包含着 "v",stepA下面有一个stepB,stepB中含有 "a",就这样一层一层嵌套下去....
- 代码生成(raw code)
这个阶段主要做的就是拿AST来生成一份JS语言内部认可的代码(这是语言内部制定的,并不是二进制哦),在生成的过程中,编译器还会询问作用域的问题,还是以 var a = 1;为例,编译器首先会询问作用域,当前有没有变量a,如果有则忽略,否则在当前作用域下创建一个名叫a的变量.
词法阶段
哈哈,终于到了词法阶段,是不是看了上面的三大阶段,甚是懵逼,没想到js还会有这样繁琐的经历? 其实,上面的概括只是所有编译语言的最基本的流程,对于我们的JS而言,它在编译阶段做的事情可不仅仅是那些,它会提前为js引擎做一些性能优化等工作,总之,编译器把所有脏活累活全干遍了。
要说到词法阶段这个概念,我们还要结合上面未结的分词/词法分析阶段.来说...
词法作用域是发生在编译阶段的第一个步骤当中,也就是分词/词法分析阶段。它有两种可能,分词和词法分析,分词是无状态的,而词法分析是有状态的。
那我们如何判断有无状态呢?以 var a = 1为例,如果词法单元生成器在判断a是否为一个独立的词法单元时,调用的是有状态的解析规则(生成器不清楚它是否依赖于其他词法单元,所以要进一步解析)。反之,如果它不用生成器判断,是一条不用被赋予语意的代码(暂时可以理解为不涉及作用域的代码,因为js内部定义什么样的规则我们并不清楚),那就被列入分词中了。
这下我们知道,如果词法单元生成器拿不准当前词法单元是否为独立的,就进入词法分析,否则就进入分词阶段。
没错,这就是理解词法作用域及其名称来历的基础。
简单的说,词法作用域就是定义在词法阶段的作用域。词法作用域就是你编写代码时,变量和块级作用域写在哪里决定的。当词法解析器(这里只当作是解析词法的解析器,后续会有介绍)处理代码时,会保持作用域不变(除动态作用域)。
在这一小节中,我们只需要了解:
- 词法作用域是什么?
- 词法阶段中 分词/词法分析的概念?
- 它们对词法作用域的形成有哪些影响?
这节有两个个忽略掉的知识点(词法解析器,动态作用域),因主题限制没有写出来,以后有机会为大家介绍。下面开始作用域。
作用域链
1. 执行环境
执行环境定义了变量或函数有权访问的其他数据。
环境栈可以暂时理解为一个数组(JS引擎的一个储存栈)。
在web浏览器中,全局环境即window是最外层的执行环境,而每个函数也都有自己的执行环境,当调用一个函数的时候,函数会被推入到一个环境栈中,当他以及依赖成员都执行完毕之后,栈就将其环境弹出,
先看一个图 !

环境栈也有人称做它为函数调用栈(都是一回事,只不过后者的命名方式更倾向于函数),这里我们统称为栈。位于环境栈中最外层是 window , 它只有在关闭浏览器时才会从栈中销毁。而每个函数都有自己的执行环境,
到这里我们应该知道:
- 每个函数都有一个与之对应的执行环境。
- 当函数执行时,会把当前函数的环境押入环境栈中,把当前函数执行完毕,则摧毁这个环境。
- window 全局对象时栈中对外层的(相对于图片来说,就是最下面的)。
- 函数调用栈与环境栈的区别 。 这两者就好像是 JS中原始类型和基础类型 | 引用类型与对象类型与复合类型 汗!
2. 变量对象与活动对象
执行环境,所谓环境我们不难联想到房子这一概念。没错,它就像是一个大房子,它不是独立的,它会为了完成更多的任务而携带或关联其他的概念。
每个执行环境都有一个表示变量的对象-------变量对象,这个对象里储存着在当前环境中所有的变量和函数。
变量对象对于执行环境来说很重要,它在函数执行之前被创建。它包含着当前函数中所有的参数,变量,函数。这个创建变量对象的过程实际就是函数内数据(函数参数、内部变量、内部函数)初始化的过程。
在没有执行当前环境之前,变量对象中的属性都不能访问!但是进入执行阶段之后,变量对象转变为了活动对象,里面的属性都能被访问了,然后开始进行执行阶段的操作。所以活动对象实际就是变量对象在真正执行时的另一种形式。
function fun (a){
var n = 12;
function toStr(a){
return String(a);
}
}
在 fun 函数的环境中,有三个变量对象(压入环境栈之前),首先是arguments,变量n 与 函数 toStr ,压入环境栈之后(在执行阶段),他们都属于fun的活动对象。 活动对象在最开始时,只包含一个变量,即argumens对象。
到这里我们应该知道:
- 每个执行环境有一个与之对应的变量对象。
- 环境中定义的所有变量和函数都保存在这个对象里。
- 对于函数,执行前的初始化阶段叫变量对象,执行中就变成了活动对象。
3. 作用域链
当代码在一个环境中执行时,会创建变量对象的一个作用域链。用数据格式表达作用域链的结构如下。
[{当前环境的变量对象},{外层变量对象},{外层的外层的变量对象}, {window全局变量对象}] 每个数组单元就是作用域链的一块,这个块就是我们的变量对象。
作用于链的前端,始终都是当前执行的代码所在环境的变量对象。全局执行环境的变量对象也始终都是链的最后一个对象。
function foo(){
var a = 12;
fun(a);
function fun(a){
var b = 8;
console.log(a + b);
}
}
foo(); // 20
再来看上面这个简单的例子,我们可以先思考一下,每个执行环境下的变量对象都是什么? 这两个函数它们的变量对象分别都是什么?
我们以fun为例,当我们调用它时,会创建一个包含 arguments,a,b的活动对象,对于函数而言,在执行的最开始阶段它的活动对象里只包含一个变量,即arguments(当执行流进入,再创建其他的活动对象)。
在活动对象中,它依然表示当前参数集合。对于函数的活动对象,我们可以想象成两部分,一个是固定的arguments对象,另一部分是函数中的局部变量。而在此例中,a和b都被算入是局部变量中,即便a已经包含在了arguments中,但他还是属于。
有没有发现在环境栈中,所有的执行环境都可以组成相对应的作用域链。我们可以在环境栈中非常直观的拼接成一个相对作用域链。
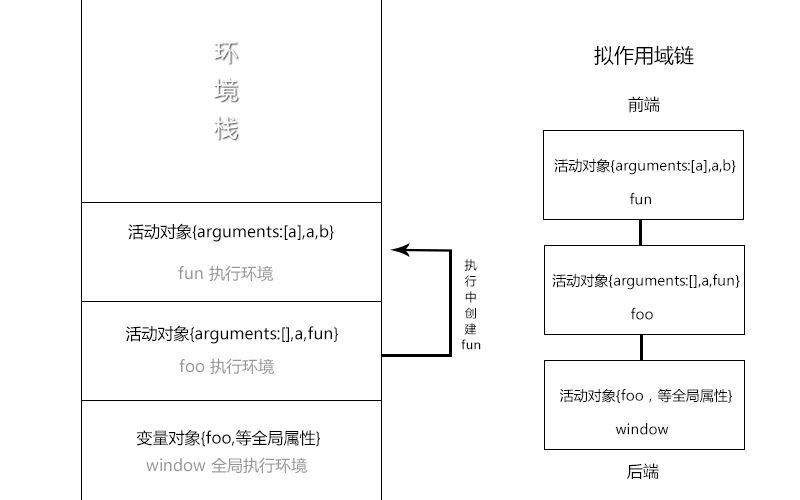
下面我们大致说下这段代码的执行流程:
- 在创建foo的时候,作用域链已经预先包含了一个全局对象,并保存在内部属性[[ Scope ]]当中。
- 执行foo函数,创建执行环境与活动对象后,取出函数的内部属性[[Scope]]构建当前环境的作用域链(取出后,只有全局变量对象,然后此时追加了一个它自己的活动对象)。
- 执行过程中遇到了fun,从而继续对fun使用上一步的操作。
- fun执行结束,移出环境栈。foo因此也执行完毕,继续移出。
- javscript 监听到foo没有被任何变量所引用,开始实施垃圾回收机制,清空占用内存。
作用域链其实就是引用了当前执行环境的变量对象的指针列表,它只是引用,但不是包含。,因为它的形状像链条,它的执行过程也非常符合,所以我们都称之为作用域链,而当我们弄懂了这其中的奥秘,就可以抛开这种形式上的束缚,从原理上出发。
到这里我们应该知道:
- 什么是作用域链。
- 作用域链的形成流程。
- 内部属性 [[Scope]] 的概念。
使用闭包
从头到尾,我们把涉及到的技术点都过了一遍,写的不太详细也有些不准确,因为没有经过事实的论证,我们只大概了解了这个过程概念。
涉及的理论充实了,那么现在我们就要使用它了。 先上几个最简单的计数器例子:
var counter = (!function(){
var num = 0;
return function(){ return ++num; }
}())
function counter(){
var num = 0;
return {
reset:function(){
num = 0;
},
count:function(){
return num++;
}
}
}
var a = counter();
a.count() // 0
a.count() // 1
a.count() // 2 累加
a.reset() // 重置num = 0;
function counter_get (n){
return {
get:counte(){
return ++n;
},
set:counte(m){
if(m<n){ throw Error("error: param less than value"); }
else {
n = m; return n;
}
}
}
}
相信看到这里,很多同学都预测出它们执行的结果。它们都有一个小特点,就是实现的过程都返回一个函数对象,返回的函数中带有对外部变量的引用。
为什么非要返回一个函数呢 ?
因为函数可以提供一个执行环境,在这个环境中引用其它环境的变量对象时,后者不会被js内部回收机制清除掉。从而当你在当前执行环境中访问它时,它还是在内存当中的。这里千万不要把环境栈和垃圾回收这两个很重要的过程搞混了,环境栈通俗点就是调用栈,调用移入,调用后移出,垃圾回收则是监听引用。
为什么可以一直递增呢 ?
上面已经说了,返回的匿名函数构成了一个执行环境,这个执行环境的作用域链下的变量对象并不是它自己的,而是其他环境中的。正因为它引用了别人,js才不会对它进行垃圾回收。所以这个值一直存在,每次执行都会对他进行递增。
性能会不会有损耗 ?
就拿这个功能来说,我们为了实现它使用了闭包,但是当我们使用结束之后呢? 不要忘了还有一个变量对其他变量对象的引用。这个时候我们为了让js可以正常回收它,可以手动赋值为null;
以第一个为例:
var counter = (!function(){
var num = 0;
return function(){ return ++num; }
}())
var n = couter();
n(); n(); // 累➕
n = null; // 清空引用,等待回收
我们再来看上面的代码,第一个是返回了一个函数,后两个类似于方法,他们都能非常直接的表明闭包的实现,其实更值得我们注意的是闭包实现的多样性。
闭包面试题
一. 用属性的存取器实现一个闭包计时器
见上例;
二. 看代码,猜输出
function fun(n,o) {
console.log(o);
return {
fun:function(m){
return fun(m,n);
}
};
}
var a = fun(0); a.fun(1); a.fun(2); a.fun(3);//undefined,?,?,?
var b = fun(0).fun(1).fun(2).fun(3);//undefined,?,?,?
var c = fun(0).fun(1); c.fun(2); c.fun(3);//undefined,?,?,?
这道题的难点除了闭包,还有递归等过程,笔者当时答这道题的时候也答错了,真是恶心。下面我们来分析一下。
首先说闭包部分,fun返回了一个可用.操作符访问的fun方法(这样说比较好理解)。在返回的方法中它的活动对象可以分为 [arguments[m],m,n,fun]。在问题中,使用了变量引用(接收了返回的函数)了这些活动对象。
在返回的函数中,有一个来自外部的实参m,拿到实参后再次调用并返回fun函数。这次执行fun时附带了两个参数,第一个是刚才的外部实参(也就是调用时自己赋的),注意第二个是上一次的fun第一个参数。
第一个,把返回的fun赋给了变量a,然后再单独调用返回的fun,在返回的fun函数中第二个参数n正好把我们上一次通过调用外层fun的参数又拿回来了,然而它并不是链式的,可见我们调用了四次,但这四次,只有第一次调用外部的fun时传进去的,后面通过a调用的内部fun并不会影响到o的输出,所以仔细琢磨一下不难看出最后结果是undefine 0,0,0。
第二个是链式调用,乍一看,和第一个没有区别啊,只不过第一个是多了一个a的中间变量,可千万不要被眼前的所迷惑呀!!!
// 第一个的调用方式 a.fun(1) a.fun(2) a.fun(3)
{
fun:function(){
return fun() // 外层的fun
}
}
//第二个的调用方式 fun(1).fun(2).fun(3)
//第一次调用返回和上面的一模一样
//第二次以后有所不同
return fun() //直接返回外部的fun
看上面的返回,第二的不同在于,第二次调用它再次接收了{fun:return fun}的返回值,然而在第三次调用时候它就是外部的fun函数了。理解了第一个和第二个我相信就知道了第三个。最后的结果就不说了,可以自己测一下。
三. 看代码,猜输出
for (var i = 1; i <= 5; i++) {
setTimeout( function timer() {
console.log(i);
}, 1000 );
}
for (var i = 1; i <= 5; i++) {
(function(i){
setTimeout( function () {
console.log(i);
}, 1000 );
})(i);
}
上例中两段代码,第一个我们在面试过程中一定碰到过,这是一个异步的问题,它不是一个闭包,但我们可以通过闭包的方式解决。
第二段代码会输出 1- 5 ,因为每循环一次回调中都引用了参数i(也就是活动对象),而在上一个循环中,每个回调引用的都是一个变量i,其实我们还可以用其他更简便的方法来解决。
for (let i = 1; i <= 5; i++) {
setTimeout( function timer() {
console.log(i);
}, 1000 );
}
let为我们创建局部作用域,它和我们刚才使用的闭包解决方案是一样的,只不过这是js内部创建临时变量,我们不用担心它引用过多造成内存溢出问题。
总结
我们知道了
本章涉及的范围稍广,主要是想让大家更全面的认识闭包,那么到现在你知道了什么呢?我想每个人心中都有了答案。
1.什么是闭包?
闭包是依据词法作用域产生的必然结果。通过变相引用函数的活动对象导致其不能被回收,然而形成了依然可以用引用访问其作用域链的结果。
(function(w,d){
var s = "javascript";
}(window,document))
有些说法把这种方式称之为闭包,并说闭包可以避免全局污染,首先大家在这里应该有一个自己的答案,以上这个例子是一个闭包吗?
避免全局污染不假,但闭包谈不上,它最多算是在全局执行环境之上新建了一个二级作用域,从而避免了在全局上定义其他变量。切记它不是真正意义的闭包。
2.闭包的原理可不可以说一下?
结合我们上面讲过的,它的根源起始于词法阶段,在这个阶段中形成了词法作用域。最终根据调用环境产生的环境栈来形成了一个由变量对象组成的作用域链,当一个环境没有被js正常垃圾回收时,我们依然可以通过引用来访问它原始的作用域链。
3.你是怎样使用闭包的?
使用闭包的场景有很多,笔者最近在看函数式编程,可以说在js中闭包其实就是函数式的一个重要基础,举个不完全函数的栗子.
function calculate(a,b){
return a + b;
}
function fun(){
var ars = Array.from(arguments);
return function(){
var arguNum = ars.concat(Array.from(arguments))
return arguNum.reduce(calculate)
}
}
var n = fun(1,2,3,4,5,6,7);
var k = n(8,9,10);
delete n;
上面这个栗子,就是保留对 fun函数的活动对象(arguments[]),当然在我们日常开发中还有更复杂的情况,这需要很多函数块,到那个时候,才能显出我们闭包的真正威力.
文章到这里大概讲完了,都是我自己的薄见和书上的一些内容,希望能对大家有点影响吧,当然这是正面的...如果哪里文中有描述不恰当或大家有更好的见解还望指出,谢谢。
文章地址https://segmentfault.com/a/1190000009886713#articleHeader0
