介绍
我正在和一位刚刚在印度超市连锁店担任运营经理的朋友说话。在我们的讨论中,我们开始谈论在印度节日(排灯节)开始之前,连锁店需要做的准备量。
他告诉我,他们估计/预测哪个产品会像热蛋糕一样销售,哪些产品不会在购买之前是至关重要的。一个不好的决定可能会让您的客户在竞争对手商店中寻找优惠和产品。挑战并没有在这里完成 - 您需要估算不同地区的商店的不同类别的产品销售情况,消费者有不同的消费技术。
当我的朋友描述挑战时,我的数据科学家开始微笑!为什么?我刚刚想出了下一篇文章的潜在主题。在今天的文章中,我会告诉你需要知道的关于回归模型的一切,以及如何使用它们来解决像上面提到的预测问题。
花一点时间,列出所有可以考虑的因素,一个商店的销售将依赖于这些因素。对于每个因素,都会产生一个关于为什么以及如何影响各种产品销售的因素的假设。例如 - 我期望产品的销售取决于商店的位置,因为每个地区的当地居民都会有不同的生活方式。商店在艾哈迈达巴德将出售的面包量将是孟买类似商店的一小部分。
同样列出你可以想到的所有可能的因素。
您商店的位置,产品的可用性,商店的尺寸,产品的优惠,产品的广告,商店的放置可能是您的销售依赖的一些功能。
你能想出多少因素?如果不到15,再考虑一下!处理这个问题的数据科学家可能会想到数百个这样的因素。
考虑到这一想法,我为您提供了一个这样的数据集 - 大卖场销售。在数据集中,我们有一个链的多个出口的产品明智的销售。
让我们来看一下数据集的快照:

在数据集中,我们可以看到出售物品的特征(脂肪含量,可见性,类型,价格)和出口(建立年份,大小,位置,类型)的一些特征以及为该特定物品出售的物品数量。我们来看看我们可以使用这些功能来预测销售情况。
目录
预测的简单模型
线性回归
最适合的线条
梯度下降
使用线性回归进行预测
评估您的Model-R平方和R平方
使用所有功能进行预测
多项式回归
偏差和差异
正则
岭回归
拉索回归
弹性网回归
正则化技术的类型[可选]
预测的简单模型
让我们先从使用几种简单的方法开始做预测。如果我问你,什么可以是预测物品销售的最简单的方法,你会说什么?
型号1 - 平均销量:
即使没有机器学习的知识,你可以说如果你必须预测一个项目的销售量,这将是过去几天的平均水平。/月/周。
这是一个很好的想法,但它也提出了一个问题 - 这个模型有多好?
事实证明,我们有多种方式可以评估我们的模型有多好。最常见的方法是均方误差。让我们了解如何衡量它。
预测错误
为了评估模型有多好,让我们了解错误预测的影响。如果我们预测销售额高于可能的水平,那么商店将花费大量的资金进行不必要的安排,从而导致库存过剩。另一方面,如果我预测它太低,我会失去销售机会。
因此,计算误差的最简单的方法是计算预测值和实际值的差异。但是,如果我们简单地添加它们,它们可能会被取消,所以我们在添加之前就对这些错误进行排列。我们还将它们除以数据点的数量来计算平均误差,因为它不应该取决于数据点的数量。

这被称为均方误差。
这里是e1,e2 ...。,en是实际值和预测值之间的差异。
那么在第一个模型中,平均误差是多少?在预测所有数据点的平均值时,我们得到均方误差= 29,11,799。看起来像巨大的错误。简单地预测平均值可能不是很酷。
我们来看看我们是否可以想到一些东西来减少错误。
型号2-按位置平均销售:
我们知道这个位置在一个物品的销售中起着至关重要的作用。例如,让我们说,在德里,汽车的销售将比在瓦拉纳西的销售高得多。因此,我们使用列“Outlet_Location_Type”的数据。
所以基本上,让我们来计算每个位置类型的平均销售额,并进行相应的预测。
预测相同,我们得到mse = 28,75,386,低于我们以前的情况。所以我们可以注意到,通过使用特征[位置],我们减少了错误。
现在,如果销售有多个功能需要依赖什么呢?我们如何使用这些信息预测销售?线性回归来我们的救援。
线性回归
线性回归是预测建模中最简单和最广泛使用的统计技术。它基本上给了我们一个方程,我们将我们的特征作为自变量,我们的目标变量[在我们的情况下的销售]依赖于它们。
那么方程式是什么样的?线性回归方程如下:

在这里,我们有Y作为因变量(Sales),X是独立变量,所有的系数都是系数。系数基本上是基于它们的重要性分配给特征的权重。例如,如果我们认为一个项目的销售对仓库类型的依赖程度会更高,那么这意味着一级城市的销售额要比3级更小城市在一个更大的出口。因此,位置类型的系数将大于店面大小。
所以,首先让我们尝试用一个特征即只有一个独立变量来理解线性回归。因此,我们的方程式成为,

该方程被称为一个简单的线性回归方程,其表示的直线,其中“Θ0”是截距,“Θ1”是直线的斜率。看看销售和MRP之间的情节。

令人惊讶的是,我们可以看到产品的销售额随着MRP的增加而增加。因此,虚线红线代表我们的回归线或最佳拟合线。但是出现的一个问题是你会发现这一行?
最适合的线条
正如你可以在下面看到的,可以有这么多的行可以用来根据他们的MRP估计销售额。那么你如何选择最合适的线条或回归线呢?

最佳拟合线的主要目的是,我们的预测值应该更接近于实际值或观测值,因为预测与实际值相距很远的值没有意义。换句话说,我们倾向于最小化我们预测的值与观测值之间的差异,实际上被称为误差。误差的图形表示如下图所示。这些错误也称为残差。残差由垂直线表示,表示预测值和实际值之差。

好的,现在我们知道我们的主要目标是找出错误并尽量减少。但在此之前,让我们想想如何处理第一部分,也就是计算错误。我们已经知道,误差是我们预测的值与观测值的差值。让我们考虑三种方法来计算错误:
残差总和(Σ(Y-h(X)))- 它可能导致抵消正负误差。
残差绝对值(Σ| Yh(X)|)- 绝对值的总和将阻止错误的消除
残差平方和(Σ(Yh(X))2)- 这是实际使用的方法,因为这里我们比较小的惩罚更高的误差值,所以造成大的误差有很大差异和小错误,这使得容易区分和选择最适合线。
因此,这些残差的平方和表示为:

其中,H(x)是由我们预测的值,H(X)=Θ1* X +Θ0,y为实际值,m是在训练组中的行数。
成本函数
那么说,你增加了一个特定的商店的大小,在那里你预测销售额会更高。但尽管规模不断扩大,但该店的销售额并没有增加。因此,增加商店规模所需的成本给您带来负面结果。
所以,我们需要尽量减少这些成本。因此,我们引入一个成本函数,它基本上用于定义和测量模型的误差。

如果仔细观察这个方程,它只是类似于平方误差的总和,只需要1 / 2m的乘积来减轻数学。
所以为了改进我们的预测,我们需要最小化成本函数。为此,我们使用梯度下降算法。所以让我们了解它是如何工作的。
渐变下降
让我们考虑一个例子,我们需要找到这个方程的最小值,
Y = 5x + 4x ^ 2。在数学中,我们简单地将x方程的导数简单地等于零。这给出了这个方程式最小的一点。因此,取代该值可以给出该方程的最小值。
梯度血统以类似的方式工作。它迭代地更新Θ,找到成本函数最小的点。如果你想深入研究血液深度下降,我强烈建议您阅读本文。
使用线性回归预测
现在让我们考虑使用线性回归预测我们的大型市场销售问题的销售。
模型3 - 输入线性回归:
从以前的情况,我们知道通过使用正确的功能将提高我们的准确性。所以现在让我们用两个功能,MRP和店铺建立年度来估算销售。
现在,我们在python中建立一个线性回归模型,只考虑这两个特征。
# importing basic libraries
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
from sklearn.model_selection import train_test_split
import test and train file
train = pd.read_csv('Train.csv')
test = pd.read_csv('test.csv')
# importing linear regressionfrom sklearn
from sklearn.linear_model import LinearRegression
lreg = LinearRegression()
splitting into training and cv for cross validation
X = train.loc[:,['Outlet_Establishment_Year','Item_MRP']]
x_train, x_cv, y_train, y_cv = train_test_split(X,train.Item_Outlet_Sales)
training the model
lreg.fit(x_train,y_train)
predicting on cv
pred = lreg.predict(x_cv)
calculating mse
mse = np.mean((pred - y_cv)**2)
在这种情况下,我们得到mse = 19,10,586.53,比我们的模型2小得多。因此,借助两个特征预测更准确。
我们来看一下这个线性回归模型的系数。
# calculating coefficients
coeff = DataFrame(x_train.columns)
coeff['Coefficient Estimate'] = Series(lreg.coef_)
coeff

因此,我们可以看到MRP具有较高的系数,意味着价格较高的物品销售更好。
6.评估您的模型 - R平方和调整后的R平方
您认为该模型的准确度如何?我们有任何评估指标,以便我们检查一下吗?其实我们有一个数量,叫做R-Square。
R-Square:它决定了Y(因变量)的总变化的多少是由X(自变量)的变化来解释的。数学上可以写成:

R平方的值始终在0和1之间,其中0表示模型没有模型解释目标变量(Y)中的任何变异性,1表示解释目标变量的完全变异性。
现在让我们检查上述模型的r平方。
lreg.score(x_cv,y_cv)
0.3287
在这种情况下,R 2为32%,这意味着销售额的差异只有32%是由成立年份和MRP进行解释的。换句话说,如果您知道建立成立年份和MRP,您将有32%的信息来准确预测其销售。
现在如果我在我的模型中再引入一个功能,会发生什么事情,我的模型会更加逼近实际价值吗?R-Square的价值会增加吗?
让我们考虑另一个案例。
模型4 - 具有更多变量的线性回归
我们通过使用两个变量而不是一个变量了解到,我们提高了对项目销售进行准确预测的能力。
所以,我们再来介绍一下另外一个功能“重量”的情况。现在我们用这三个特征构建一个回归模型。
X = train.loc[:,['Outlet_Establishment_Year','Item_MRP','Item_Weight']]
splitting into training and cv for cross validation
x_train, x_cv, y_train, y_cv = train_test_split(X,train.Item_Outlet_Sales)
## training the model
lreg.fit(x_train,y_train)
ValueError:输入包含NaN,无穷大或对dtype('float64')太大的值。
它会产生错误,因为项目权重列有一些缺失值。所以让我们用其他非空条目的平均值来估算它。
train['Item_Weight'].fillna((train['Item_Weight'].mean()),inplace=True)
让我们再次尝试运行该模型。
training the modellreg.fit(x_train,y_train)
## splitting into training and cv for cross validation
x_train, x_cv, y_train, y_cv = train_test_split(X,train.Item_Outlet_Sales)
## training the modellreg.fit(x_train,y_train)
predicting on cvpred = lreg.predict(x_cv)
calculating mse
mse = np.mean((pred - y_cv)**2)
mse
1853431.59
## calculating coefficients
coeff = DataFrame(x_train.columns)
coeff['Coefficient Estimate'] = Series(lreg.coef_)

calculating r-square
lreg.score(x_cv,y_cv)0.32942
所以我们可以看到,mse进一步减少。R平方值有增加,是否意味着增加项目权重对我们的模型是有用的?
调整后的R平方
R2的唯一缺点是如果将新的预测因子(X)添加到我们的模型中,则R2仅增加或保持恒定,但不会降低。我们不能通过增加我们的模型的复杂性判断,我们是否更准确?
这就是为什么我们使用“调整的R方”。
调整后的R平方是R模型的修改形式,已经针对模型中的预测数量进行了调整。它结合了模型的自由度。如果新术语提高了模型精度,调整后的R-Square只会增加。
哪里

R2=样品R平方
p =预测数量
N =总样本量
7.使用所有功能进行预测
现在让我们构建一个包含所有功能的模型。在建立回归模型时,我只使用了连续的功能。这是因为我们需要在分类变量之前不同地使用线性回归模型。有不同的技术来对待它们,这里我使用了一个热编码(将每个类别的分类变量转换为一个特征)。除此之外,我还估计出口尺寸的缺失值。
回归模型的数据预处理步骤
# imputing missing values
train['Item_Visibility'] = train['Item_Visibility'].replace(0,np.mean(train['Item_Visibility']))
train['Outlet_Establishment_Year'] = 2013 - train['Outlet_Establishment_Year']
train['Outlet_Size'].fillna('Small',inplace=True)
# creating dummy variables to convert categorical into numeric values
mylist = list(train1.select_dtypes(include=['object']).columns)
dummies = pd.get_dummies(train[mylist], prefix= mylist)
train.drop(mylist, axis=1, inplace = True)
X = pd.concat([train,dummies], axis =1 )
建立模型
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
%matplotlib inline
train = pd.read_csv('training.csv')
test = pd.read_csv('testing.csv')
# importing linear regression
from sklearnfrom sklearn.linear_model import LinearRegression
lreg = LinearRegression()
# for cross validation
from sklearn.model_selection import train_test_split
X = train.drop('Item_Outlet_Sales',1)
x_train, x_cv, y_train, y_cv = train_test_split(X,train.Item_Outlet_Sales, test_size =0.3)
# training a linear regression model on train
lreg.fit(x_train,y_train)
# predicting on cv
pred_cv = lreg.predict(x_cv)
# calculating mse
mse = np.mean((pred_cv - y_cv)**2)
mse
1348171.96
# evaluation using r-square
lreg.score(x_cv,y_cv)
0.54831541460870059
显然,我们可以看到,mse和R-square都有很大的改进,这意味着我们的模型现在能够预测与实际值接近的价值观。
为您的模型选择正确的功能
当我们有一个高维数据集时,使用所有变量是非常低效的,因为它们中的一些可能会传递冗余信息。我们需要选择正确的变量集合,这些变量给出了一个准确的模型,并能很好地解释因变量。有多种方式为模型选择正确的变量集。其中首先是业务理解和领域知识。例如,在预测销售情况时,我们知道营销工作应对销售产生积极影响,并且是您的模型中的重要特征。我们还应该注意,我们选择的变量不应该在它们之间相互关联。
而不是手动选择变量,我们可以通过使用向前或向后选择来自动执行此过程。前向选择从模型中最重要的预测变量开始,并为每个步骤添加变量。反向消除从模型中的所有预测变量开始,并删除每个步骤的最不重要的变量。选择标准可以设置为任何统计测量,如R平方,t-stat等。
回归曲调解释
看看残差对拟合值图。
residual plot
x_plot = plt.scatter(pred_cv, (pred_cv - y_cv), c='b')
plt.hlines(y=0, xmin= -1000, xmax=5000)
plt.title('Residual plot')

我们可以在情节中看到一个像形状的漏斗。这种形状表示异方差。在误差项中存在非常数方差导致异方差。我们可以清楚地看到误差项(残差)的方差不是恒定的。一般来说,在出现异常值或极度杠杆值的情况下出现非恒定方差。这些值得到太多的重量,从而不成比例地影响了模型的性能。当出现这种现象时,样本预测的置信区间往往是不切实际的宽或窄。
我们可以通过查看残差对拟合值图来轻松地检查这一点。如果存在异方差性,则绘图将显示如上所示的漏斗形状图案。这表示数据中没有被模型捕获的非线性的迹象。我强烈建议您阅读本文,详细了解回归图的假设和解释。
为了捕获这种非线性效应,我们有另一种称为多项式回归的回归。所以让我们现在明白一下。
多项式回归
多项式回归是另一种形式的回归,其中自变量的最大幂大于1.在该回归技术中,最佳拟合线不是直线,而是以曲线的形式。
二次回归或二阶多项式的回归由下式给出:
Y =Θ1+Θ2* X +Θ3* X2
现在看下面给出的情节。

显然,二次方程拟合数据比简单的线性方程更好。在这种情况下,你认为二次回归的R平方值比简单的线性回归如何?肯定是的,因为二次回归拟合数据比线性回归更好。虽然二次和三次多项式是常见的,但您也可以添加更高等级的多项式。
下图显示了6度多项式方程的行为。

那么你认为使用更高阶多项式来适应数据集总是更好。可悲的是,没有。基本上,我们已经创建了一个适合我们的培训数据的模型,但没有估计超出训练集的变量之间的真实关系。因此,我们的模型在测试数据上表现不佳。这个问题被称为过拟合。我们也说模型的方差偏高,偏倚偏低。

同样,我们有一个叫做另一个问题欠拟合,它发生在我们的模型中没有适合的训练数据,也不推广上的新数据。
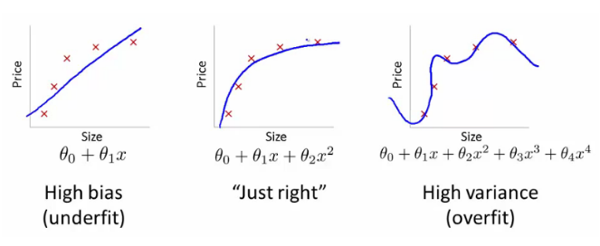
当我们有高偏差和低方差时,我们的模型是不足的。
回归模型的偏差和方差
这个偏差和方差实际上是什么意思?让我们通过射箭目标的例子来理解这一点。

假设我们的模型是非常准确的,因此我们的模型的误差将会很低,这意味着低偏差和低方差,如图所示。所有数据点都适合公牛。同样,我们可以说,如果方差增加,我们的数据点的扩展增加,这导致不太准确的预测。随着偏差的增加,我们的预测值和观测值之间的误差也增加。
现在这个偏差和方差是如何平衡的有一个完美的模型?看看下面的图片,并尝试了解。

随着我们在模型中增加越来越多的参数,其复杂性增加,导致方差增加和偏差减小,即过度拟合。因此,我们需要在我们的模型中找出一个最优点,其中偏差的减少等于方差的增加。在实践中,没有分析方法来找到这一点。那么如何处理高偏差或高偏差呢?
为了克服欠拟合或高偏差,我们基本上可以为我们的模型添加新的参数,使得模型的复杂性增加,从而减少高偏差。
现在,我们如何克服过拟合的回归模型?
基本上有两种方法来克服过拟合,
降低模型复杂度
正则
在这里,我们将详细讨论正则化,以及如何使用它来使您的模型更加一般化。
正规化
你有你的模型准备好了,你已经预测了你的输出。那你为什么要学习正规化呢?有必要吗?
假设你参加了比赛,在这个问题上你需要预测一个连续变量。所以你应用线性回归并预测你的输出。瞧!你在排行榜上。但等待你看到的排行榜上还有很多人在你身上。但是你做了一切正确的,那怎么可能呢?
“一切都应该尽可能简单,但不要简单 - 爱因斯坦爱因斯坦”
我们做的更简单,其他所有人都这样做,现在让我们看看简单。这就是为什么我们将尝试在正规化的帮助下优化我们的代码。
在正则化中,我们所做的是通常我们保持相同数量的特征,但是减小系数j的大小。减少系数如何有助于我们?
我们来看看我们上述回归模型中的特征系数。
checking the magnitude of coefficients
predictors = x_train.columns
coef = Series(lreg.coef_,predictors).sort_values()
coef.plot(kind='bar', title='Modal Coefficients')
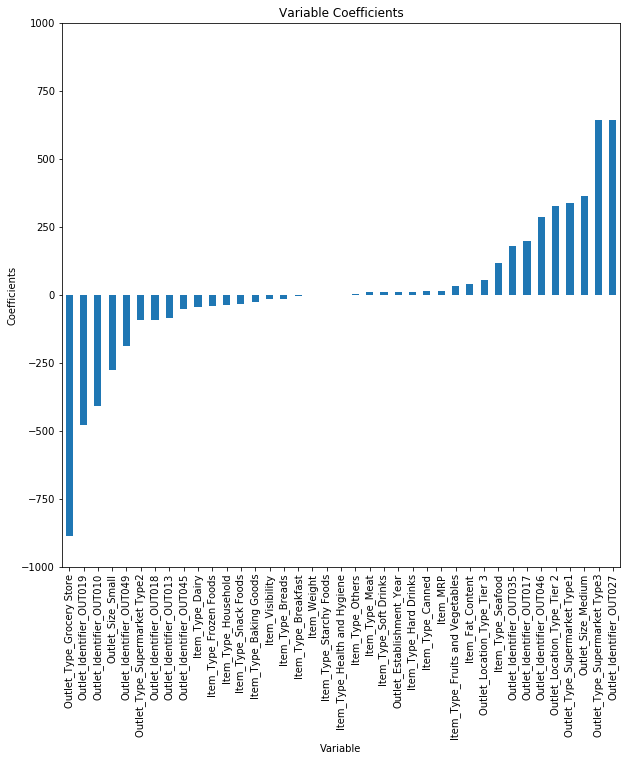
我们可以看到Outlet_Identifier_OUT027和Outlet_Type_Supermarket_Type3(最后2)的系数与其余系数相比要高得多。因此,这两个功能将更多地推动项目的总销售额。
我们如何减小我们模型中系数的大小?为此,我们有不同类型的回归技术,使用正则化来克服这个问题。所以让我们讨论一下。
岭回归
我们首先对我们的上述问题进行实施,并检查我们的结果是否比线性回归模型更好。
from sklearn.linear_modelimport Ridge
## training the model
ridgeReg = Ridge(alpha=0.05, normalize=True)
ridgeReg.fit(x_train,y_train)
pred = ridgeReg.predict(x_cv)
calculating mse
mse = np.mean((pred_cv - y_cv)**2)
mse1348171.96## calculating scoreridgeReg.score(x_cv,y_cv)0.5691
所以,我们可以看到,由于R-Square的价值增加,我们的模型略有改善。请注意,Alpha的值是Ridge的超参数,这意味着它们不会被模型自动学习,而是必须手动设置。
这里我们考虑α= 0.05。但是让我们考虑不同的α值,并绘制每种情况的系数。

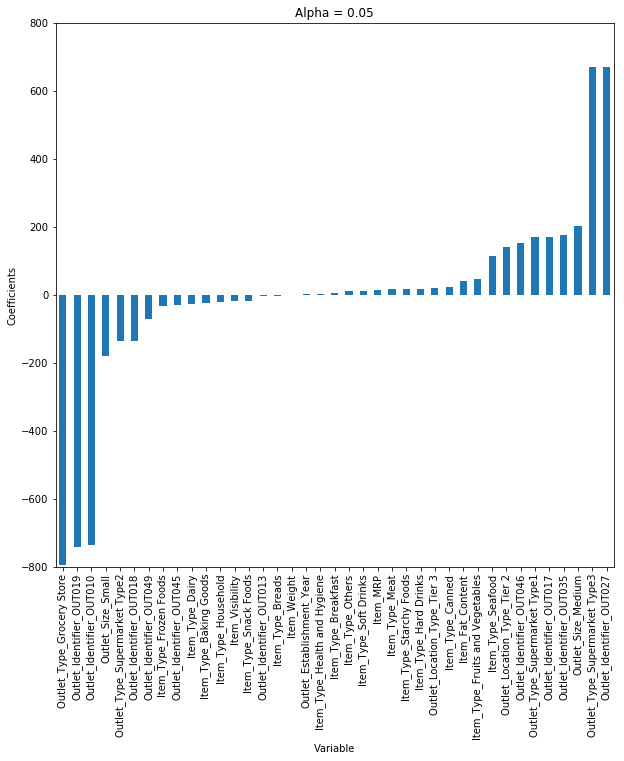
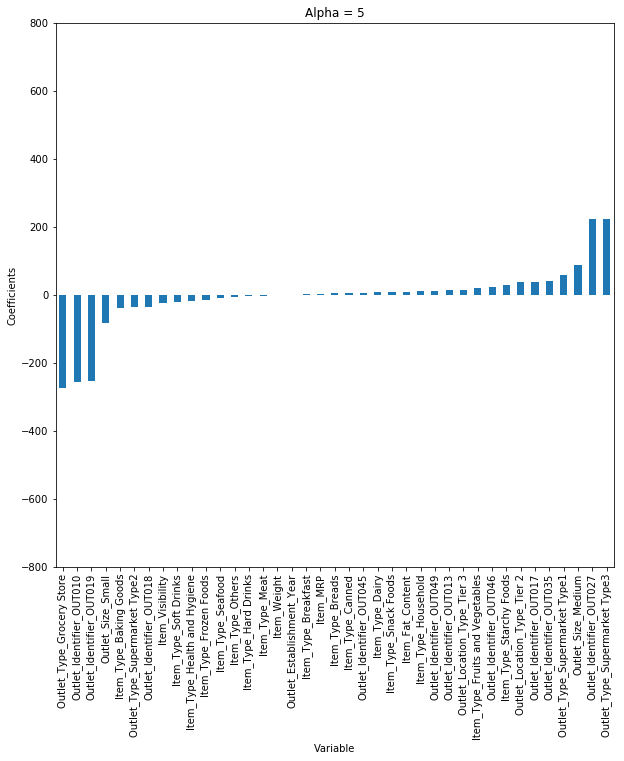

您可以看到,当我们增加α的值时,系数的幅度减小,其中值达到零但不是绝对零。
但是,如果您计算每个alpha的R平方,我们将看到在α= 0.05时R平方的值将是最大值。所以我们必须明智地选择它,通过遍历一系列值,并使用给我们最低错误的值。
所以,现在你有一个想法如何实现它,但让我们来看看数学方面。到目前为止,我们的想法是基本上最小化成本函数,使得预测的值更接近于期望的结果。
现在再次回顾一下脊线回归的成本函数。

在这里,如果你注意到,我们遇到一个额外的术语,这被称为惩罚术语。这里给出的λ实际上由脊函数中的α参数表示。所以通过改变α的值,我们基本上就是控制罚球。α值越高,惩罚越大,因此系数的幅度就越小。
重点:
它缩小了参数,因此它主要用于防止多重共线性。
它通过系数收缩降低了模型的复杂性。
它使用L2正则化技术。(我将在本文后面讨论)
现在让我们考虑另一种也利用正则化的回归技术。
拉索回归
LASSO(最小绝对收缩算子)与山脊非常相似,但我们可以通过在我们的大型市场问题中实现它们来区分它们。
from sklearn.linear_model import Lasso
lassoReg = Lasso(alpha=0.3, normalize=True)
lassoReg.fit(x_train,y_train)
pred = lassoReg.predict(x_cv)
# calculating mse
mse = np.mean((pred_cv - y_cv)**2)
mse
1346205.82
lassoReg.score(x_cv,y_cv)
0.5720
我们可以看到,我们的模型的Mse和R平方的值都增加了。因此,套索模型预测比线性和脊线都好。
再次让我们改变alpha的值,看看它是如何影响系数的。

所以,我们可以看到,即使在α值较小的情况下,系数的大小也减少了很多。通过看地块,你能看出山脊和套索之间的区别吗?
我们可以看到,随着我们增加α的值,系数接近零,但是如果你看到套索的情况,即使在较小的α,我们的系数也减少到绝对零。因此,套索选择唯一的一些特征,同时将他人的系数降低到零。这个属性被称为特征选择,在脊的情况下是不存在的。
拉索回归后的数学与山脊相似,静止不同,而不是加上theta的平方,我们将加上Θ的绝对值。
在这里,λ是超仪,其值等于拉索函数中的α。
重点:
它使用L1正则化技术(将在本文后面讨论)
当我们拥有更多的功能时,通常使用它,因为它会自动进行功能选择。
现在您已经对脊和套索回归有了基本了解,我们来看一个例子,我们有一个大的数据集,可以说它有10,000个特征。我们知道一些独立的功能与其他独立功能相关。然后想想,你会使用哪种回归,Rigde或Lasso?
让我们一一讨论一下。如果我们应用脊回归,它将保留所有的特征,但会缩小系数。但是问题是,模型仍将保持复杂,因为有10,000个功能,因此可能导致模型性能不佳。
而不是如果我们应用套索回归这个问题怎么办?套索回归的主要问题是当我们有相关变量时,它只保留一个变量,并将其他相关变量设置为零。这可能会导致信息丢失,导致我们的模型的准确性降低。
那么这个问题的解决方案是什么?实际上,我们有另一种类型的回归,称为弹性网回归,其基本上是脊和套索回归的混合。所以让我们试着去了解一下。
弹性网回归
在进入理论部分之前,让我们在大型市场销售问题上实施。它会比山脊和套索好吗?让我们检查!
from sklearn.linear_model import ElasticNet
ENreg = ElasticNet(alpha=1, l1_ratio=0.5, normalize=False)
ENreg.fit(x_train,y_train)
pred_cv = ENreg.predict(x_cv)
#calculating mse
mse = np.mean((pred_cv - y_cv)**2)
mse1773750.73
ENreg.score(x_cv,y_cv)
0.4504
所以我们得到了R-Square的价值,它比山脊和套索还要小。你能想到为什么吗这个垮台背后的原因基本上是没有一大堆功能。当我们有一个大数据集时,弹性回归通常会很好。
注意,这里我们有两个参数alpha和l1_ratio。首先让我们讨论一下,弹性网中会发生什么,以及它与脊和套索的不同之处。
弹性网基本上是L1和L2正则化的组合。所以如果你知道弹性网,你可以通过调整参数来实现Ridge和Lasso。所以它使用L1和L2的两性术语,因此它的方程式如下:

那么我们如何调整羔羊来控制L1和L2惩罚项?让我们以一个例子了解。你正在试图从池塘里捞一条鱼。你只有一个网,那么你会做什么?你会随机扔你的网吗?不,你真的会等到你看到一条鱼在游泳的时候,然后你会把网向这个方向,基本上收集整个鱼群。因此,即使相关,我们仍然想看看他们的整个团体。
弹性回归的工作方式类似。假设我们在数据集中有一堆相关的自变量,那么弹性网将简单地形成一个由这些相关变量组成的组。现在,如果这个组中的任何一个变量是一个强大的预测因子(意味着与因变量有很强的关系),那么我们将把整个组包括在模型构建中,因为省略其他变量(就像我们在套索中做的那样)导致在解释能力方面失去一些信息,导致模型表现不佳。
所以,如果你看上面的代码,我们需要在定义模型时定义alpha和l1_ratio。Alpha和l1_ratio是您可以相应设置的参数,如果您想分别控制L1和L2惩罚。其实我们有
α= a + b和l1_ratio = a /(a + b)
其中,a和b分别分配给L1和L2项。所以当我们改变alpha和l1_ratio的值时,a和b被设置为使得它们控制L1和L2之间的权衡:
a *(L1项)+ b *(L2项)
让α(或a + b)= 1,现在考虑以下情况:
如果l1_ratio = 1,那么如果我们看l1_ratio的公式,我们可以看到,如果a = 1,则l1_ratio只能等于1,这意味着b = 0。因此,这将是一个套索。
类似地,如果l1_ratio = 0,则暗示a = 0。那么惩罚将是一个山脊惩罚。
对于l1_ratio在0和1之间,惩罚是脊和套索的组合。
所以让我们来调整alpha和l1_ratio,并尝试从下面给出的系数图中理解。


现在,您对脊,套索和弹性网回归有基本的了解。但在此期间,我们遇到了两个L1和L2,这两个方面基本上是正则化的两种。总而言之,基本上来说,套索和山脊分别是L1和L2正则化的直接应用。
但如果你还想知道,下面我已经解释了他们背后的概念,这是可选的。
14.正规化技术的类型[可选]
让我们回想一下,无论是山脊还是套索,我们都添加了一个惩罚术语,但是在这两种情况下都是不同的。在脊中,我们使用theta的平方而在套索中我们使用了θ的绝对值。那么为什么这两个只有,不能有其他的可能性?
实际上,在正则化项中参数的不同选择顺序有不同的可能的正则化选择
。这通常被称为Lp正则剂。

让我们尝试通过绘制它们来可视化一些。为了使可视化变得容易,我们可以将它们绘制在2D空间中。为此,我们假设我们只有两个参数。现在,假设p = 1,我们有一个术语
。我们不能绘制这条线的方程?下面给出了p的不同值的类似图。

在上面的图中,轴表示参数(θ1和θ2)。让我们逐一检查一下。
对于p = 0.5,只有当其他参数太小时,才能获得一个参数的大值。对于p = 1,我们得到绝对值的和,其中一个参数Θ的增加被其他的减小精确地抵消。对于p = 2,我们得到一个圆,对于较大的p值,它接近圆形正方形。
两个最常用的正则化是我们有p = 1和p = 2,更常被称为L1和L2正则化。
仔细看下面给出的图。蓝色的形状是指正则化项,其他形状是指我们的最小二乘误差(或数据项)。
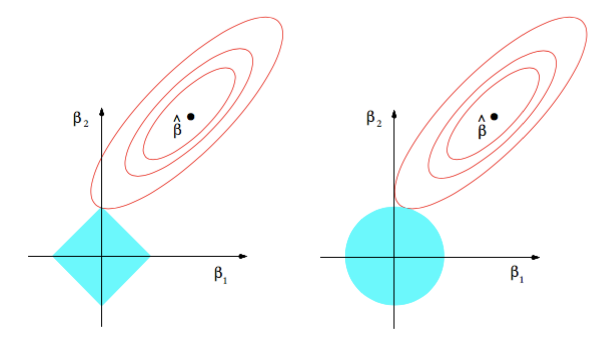
第一个数字是L1,第二个是L2正则化。黑点表示在该点处最小二乘误差最小化,并且我们可以看到它随着它的移动而二次增加,并且正则化项在所有参数为零的原点被最小化。
现在的问题是,我们的成本功能在什么时候是最小的?答案将是,因为它们是二次增加的,所以这两个术语的和将在它们首先相交的点被最小化。
看看L2正则化曲线。由于L2正则化器形成的形状是一个圆形,所以随着我们离开它,它逐渐增加。只有当最小MSE(图中的均方误差或黑点)也正好位于轴上时,L2最优(基本上是交点)才能落在轴线上。但是在L1的情况下,L1最优可以在轴线上,因为它的轮廓是锋利的,因此相互作用点的机会很大。因此,即使最小MSE不在轴上,也可以在轴线上相交。如果交点落在轴上,则称为稀疏。
因此,L1提供了一定程度的稀疏性,这使得我们的模型更有效地存储和计算,并且还可以帮助检查特征的重要性,因为不重要的特征可以精确地设置为零。
结束笔记
我希望现在你可以理解线性回归背后的科学,以及如何实现它,进一步优化它以改善模型。
“知识是宝藏,实践是关键”
因此,通过解决一些问题让你的手变脏。您也可以从Big Mart销售问题开始,并尝试通过一些功能工程来改进您的模型。如果在实施过程中面临任何困难,请随时在我们的讨论门户上写信。
你觉得这篇文章有帮助吗?请在下面的评论部分分享您的意见/想法。
