java nio
- Java的IO体系:
- 旧IO
- 新IO:nio,用ByteBuffer和FileChannel读写
- nio通道管理:Selector
- Okio:io的封装,好像不关nio的事
- Netty:目的是快速的实现任何协议的server和client端
- 所以说你可以用netty通过channel等实现一个httpclient,和URLConnection平级
- 这个课题太大了,应该分层次学:
- 第一层是官方的文档,写几个helloworld
- 第二层就是官方的example,研究server和client
- 第三层是权威指南,研究TCP,UDP等的常见问题,谷歌的protobuf,自己实现http服务器等
- github:https://github.com/netty/netty
- 其他:
- Gzip
- 大文件读写,如2G
- 文件锁
- 主题:
- 通道和缓冲器:提高读写速度,Channel,ByteBuffer,速度怎么提高的
- ByteBuffer的操作是很底层的,底层就快,底层怎么就快
- ByteBuffer倾向于大块的操作字节流,大块就快
- 异步IO:提高线程的利用率,增加系统吞吐量,selector,key等,但以牺牲实时性为代价(折衷是永恒不变的主题)
- channel管理:向Selector注册Channel,然后调用它的select()方法。这个方法会一直阻塞到某个注册的通道有事件就绪
- Selector允许单线程处理多个 Channel。如果你的应用打开了多个连接(通道),但每个连接的流量都很低,使用Selector就会很方便。例如,在一个聊天服务器中
- 怎么就牺牲实时性了,一组IO,轮询看有没有可读信息,所以一个IO来消息了,不会立刻就轮询到它
- 所以负责轮询IO的线程,读到消息就得立刻分发出去,尽量不能有耗时操作
- 特别注意:
- Channel和Selector配合时,必须channel.configureBlocking(false)切换到非阻塞模式
- 而FileChannel没有非阻塞模式,只有Socket相关的Channel才有
- channel管理:向Selector注册Channel,然后调用它的select()方法。这个方法会一直阻塞到某个注册的通道有事件就绪
- 通道和缓冲器:提高读写速度,Channel,ByteBuffer,速度怎么提高的
1 通道和缓冲器
1.1 简介
java.nio.*包的引入是为了提高速度,并且旧的IO包已经用nio重新实现过,所以即使你不用nio,也已经收益了
下面的格式可能比较乱,需要配合GetChannel例子来理解
- 如何理解:
- 你要读数据的地方,可能说的是IO流,可以看做一个煤矿,煤就是数据
- 通道:Channel,包含煤层的矿藏,就是一个煤矿里有煤的地方
- 缓冲器:ByteBuffer,可以看做运煤的车,注意这里装车和卸车也是有意义的动作
- 我们能做的就是派运煤的车去通道,也就是将缓冲器ByteBuffer和Channel连起来,往里送煤(写),往外运煤(读)
- -------缓一缓-------
- ByteBuffer是很底层的类,直接存储未加工的字节
- 初始化:
- 要写数据时,已经有数据了,所以可以得到byte[]
- ByteBuffer.wrap(byte[]) //相当于wrap(array, 0, array.length);
- ByteBuffer.wrap(byte[], offset, length) //offset + length不能超出byte数组的长度
- 要读数据时,最多只能拿到ByteBuffer可能需要大小
- ByteBuffer buff = ByteBuffer.allocate((int) fc.size());
- 接口:byte的读写,不支持对象,连String也不支持
- 将数据放到ByteBuffer里:装车
- 上面的wrap方法
- 一系列put方法,只支持基本类型
- 将数据从ByteBuffer中转出来:卸车
- 一系列get方法,只支持基本类型,注意flip
- String str = new String(buff.array(), "utf-8"),buff.array(),跟ByteBuffer指针无关
- ByteBuffer内部指针:
- ByteBuffer里有个指针
- fc.read(buff)会从往ByteBuffer里写(装车),从哪儿写,总有个起始位置,就是ByteBuffer指针的位置
- 写完,指针直到最后,也就是第一个空白可写区域
- 读取里面的信息(卸车),就需要回到起始位置
- flip一下
- positon操作可以跳到任意位置
- 初始化:
- FileChannel:FileInputStream, FileOutputStream, RandomAccessFile这三个旧类被修改了,以支持channel
- Reader和Writer不直接支持Channel,但Channel里提供了便利方法来支持他们
- 获得FileChannel:
- FileChannel fc = new FileOutputStream("data.txt").getChannel(); //写
- FileChannel fc = new FileInputStream("cl1024.json").getChannel(); //读
- FileChannel fc = new RandomAccessFile("data.txt", "rw").getChannel(); //可读可写
- 移动文件指针:append写时,断点续传时能用
- fc.position(fc.size()); // Move to the end
- 写,将一个ByteBuffer写到Channel里:
- fc.write(ByteBuffer.wrap("Some text ".getBytes()));
- 读,将一个channel里的内容,读到ByteBuffer里,读多少,由ByteBuffer的长度决定
- fc.read(buff);
- buff.flip(); 读出来的ByteBuffer一般需要再次解析出来,通过getInt,getFloat等操作,读写切换时,需要flip一下
- flip怎么理解:fc.read(buff),ByteBuffer里有个指针
- fc.read(buff)会从往ByteBuffer里写,从哪儿写,总有个起始位置,就是ByteBuffer指针的位置
- 写完,指针直到最后,也就是第一个空白可写区域
- 所以现在就好理解了,读完文件,也就是往ByteBuffer写完,指针指向ByteBuffer最后,你再读取里面的信息,就需要回到起始位置
- 总结:
- FileInputStream,FileOutputStream,这相当于煤矿
- 以前你直接操作stream的read,write,参数是byte[]
- read,write直接操作煤矿
- 直接通过byte[]读写,相当于用铁锨铲煤
- 在new io里,你不能直接操作煤矿了,而是获取一个通道:FileChannel
- 通过channel的read,write来操作数据,position,seek等,就是移动指针(文件指针)
- read,write的参数是ByteBuffer
- 通过ByteBuffer来包装数据,相当于用车拉煤
- 由于把byte[]用ByteBuffer包装起来,又面临一个装车和卸车的问题
- 装车:写文件(wrap, put等方法),读文件(channel.read(buff))
- 卸车:读文件(get各种基本类型),写文件(channel.write(buff))
- 全车操作:array
- 注意flip的问题,读写切换时,需要flip一下,而且这还不确定就是指针操作
- 注意rewind的问题,读着读着,想回头从头再读,就得rewind,这个肯定是指针操作
- buff.hasRemaining(),指针是否到头了
- 可以看出,Channel和ByteBuffer提供的接口都比较低级,直接和操作系统契合,说是这就是快的原因
- FileInputStream,FileOutputStream,这相当于煤矿
- 关于Channel:
- FileChannel
- DatagramChannel:通过UDP读写网络,无连接的
- SocketChannel:通过TCP读写网络
- ServerSocketChannel:监听新来的TCP连接,每个新进来的连接都会创建一个SocketChannel
例子,代码比较短,直接贴过来
package com.cowthan.nio;
import java.nio.*;
import java.nio.channels.*;
import java.io.*;
public class GetChannel {
private static final int BSIZE = 1024;
public static void main(String[] args) throws Exception {
// 写文件
FileChannel fc = new FileOutputStream("data.txt").getChannel();
fc.write(ByteBuffer.wrap("Some text ".getBytes())); //
fc.close();
// 写文件:append
fc = new RandomAccessFile("data.txt", "rw").getChannel();
fc.position(fc.size()); // Move to the end
fc.write(ByteBuffer.wrap("Some more".getBytes()));
fc.close();
// 读文件
fc = new FileInputStream("data.txt").getChannel();
ByteBuffer buff = ByteBuffer.allocate((int) fc.size());
fc.read(buff);
buff.flip();
System.out.println("读取:");
String str = new String(buff.array(), "utf-8");
System.out.println(str);
System.out.println("读取2:");
while (buff.hasRemaining()){
System.out.print((char) buff.get());
}
}
} /*
* Output: Some text Some more
*/// :~
1.2 更多:flip, clear,compact和mark,reset操作
- flip,clear,compact和mark,reset
- 这里说的读写都是相对于ByteBuffer
- 由写转读:flip
- 由写转读:clear清空缓冲区,compact清空缓冲区的已读数据(结果就是再装车,就是从未读数据后面开始)
- 随机读写:mark和reset,如果要一会写一会读,mark会记录当前position,position就是读写的起点,reset会回滚
- ByteBuffer.allocate(len)的大小问题,大块的移动数据是快的关键,所以长度很重要,但没啥标准,根据情况定吧,1024(1K)小了
- ByteBuffer.wrap(byte[]),不会再复制数组,而是直接以参数为底层数组,快
- 复制文件时,一个ByteBuffer对象会不断从src的channel来read,并写入dest的channel,注意:
- src.read(buff); buff.flip(); dest.write(buff); buff.clear()
- ByteBuffer必须clear了,才能重新从Channel读
- ByteBuffer.flip(), clear()比较拙劣,但这正是为了最大速度付出的代价
///复制文件的部分代码(更优化的复制文件是用transfer接口,直接通道相连)
ByteBuffer buff = ByteBuffer.allocate(1024); //1K
while(src.read(buff) != -1){
buff.flip(); //准备卸车
dest.write(buff); //卸车了
buff.clear(); //其实这才是真正的卸车,并送回通道那头(可以再次read(buff)了)
}
缓冲器细节:四大索引
看图:
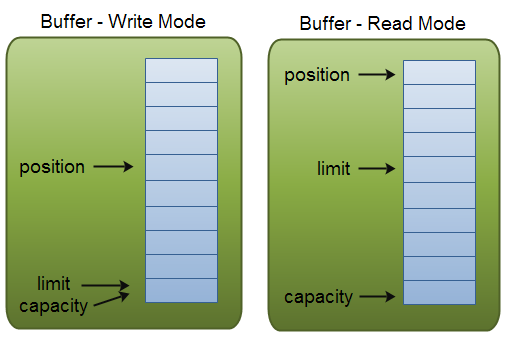
- 四大索引:
- mark:标记,mark方法记录当前位置,reset方法回滚到上次mark的位置
- position:位置,当前位置,读和写都是在这个位置操作,并且会影响这个位置,position方法可以seek
- limit:界限,
- 作为读的界限时:指到buffer当前被填入了多少数据,get方法以此为界限,
- flip一下,limit才有值,指向postion,才能有个读的界限
- 作为写的界限时:
- allocate或者clear时,直接可写,limit指向capacity,表示最多写到这
- wrap时,直接可读,所以position是0,limit是指到之后,capacity也是指到最后,直接进入可读状态
- 作为读的界限时:指到buffer当前被填入了多少数据,get方法以此为界限,
- capacity:容量,指到buffer的最后,这不是字节数,而是能写入的个数,对于ByteBuffer,就是byte个数,对于IntBuffer,就是int个数
- allocate方法的参数就是capacity
- 所以,可以推断一下,ByteBuffer.capacity = 5时,如果转成IntBuffer,capacity是1,不会指向最后,而是留出了最后一个字节,被忽略了,没法通过Int读写
- allocate方法的参数就是capacity
对应的方法:

public final Buffer flip() {
limit = position;
position = 0;
mark = UNSET_MARK;
return this;
}
public final Buffer rewind() {
position = 0;
mark = UNSET_MARK;
return this;
}
public final boolean hasRemaining() {
return position < limit;
}
public final Buffer clear() {
position = 0;
mark = UNSET_MARK;
limit = capacity;
return this;
}
public final Buffer mark() {
mark = position;
return this;
}
public final Buffer reset() {
if (mark == UNSET_MARK) {
throw new InvalidMarkException("Mark not set");
}
position = mark;
return this;
}
例子:交换相邻的两个字符
/**
* 给一个字符串,交换相邻的两个字符
*/
private static void symmetricScramble(CharBuffer buffer) {
while (buffer.hasRemaining()) {
buffer.mark();
char c1 = buffer.get();
char c2 = buffer.get();
buffer.reset();
buffer.put(c2).put(c1);
}
}
/*
思考:如果没有mark和reset功能,你怎么做?用postion方法记录和恢复刚才位置
*/
private static void symmetricScramble2(CharBuffer buffer) {
while (buffer.hasRemaining()) {
int position = buffer.position();
char c1 = buffer.get();
char c2 = buffer.get();
buffer.position(position);
buffer.put(c2).put(c1);
}
}
- 总结:
- flip:一般用于由写转读,flip之后可以:
- 读:是从头读,能读到刚才写的长度
- 写:是从头写,会覆盖刚才写入的内容
- clear:一般用于读转写,clear之后可以:
- 读:但是读不到什么了
- 写:是从头写
- mark和reset:一般用于读写交替
- mark:相当于int postion = buffer.postion(),记下当前位置
- reset:相当于buffer.postion(position),回到刚才记录的位置
- flip:一般用于由写转读,flip之后可以:
1.3 连接通道
上面说过,nio通过大块数据的移动来加快读写速度,前面这个大小都由ByteBuffer来控制,
其实还有方法可以直接将读写两个Channel相连
这也是实现文件复制的更好的方法
public class TransferTo {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.out.println("arguments: sourcefile destfile");
System.exit(1);
}
FileChannel in = new FileInputStream(args[0]).getChannel(), out = new FileOutputStream(
args[1]).getChannel();
in.transferTo(0, in.size(), out);
// 或者:
// out.transferFrom(in, 0, in.size());
}
} // /:~
1.4 字符流:CharBuffer和Charset,其实就是byte[]和编码问题
ByteBuffer是最原始的,其实就是字节流,适用于二进制数据的读写,图片文件等
但我们更常用的,其实是字符串
-
字符串涉及到的类:
- CharBuffer:注意,Channel是直接和ByteBuffer交流,所以CharBuffer只能算是上层封装
- Charset:编码相关,字节流到字符串,肯定会有编码相关的问题
- CharBuffer.toString():得到字符串
-
怎么得到CharBuffer
- 方法1:ByteBuffer.asCharBuffer(),局限在于使用系统默认编码
- 方法2:Charset.forName("utf-8").decode(buff),相当于new String(buff.array(), "utf-8")的高级版
- 相对的,Charset.forName("utf-8").encode(cbuff),返回个ByteBuffer,就相当于String.getBytes("utf-8)
-
CharBuffer读写
- put(String):写
- toString():读,就拿到了字符串
====先休息一下,说说怎么得到编码相关的一些信息吧====
//打印系统支持的所有编码,及其别名
import java.nio.charset.*;
import java.util.*;
public class AvailableCharSets {
public static void main(String[] args) {
SortedMap<String, Charset> charSets = Charset.availableCharsets();
Iterator<String> it = charSets.keySet().iterator();
while (it.hasNext()) {
String csName = it.next();
System.out.print(csName);
Iterator aliases = charSets.get(csName).aliases().iterator();
if (aliases.hasNext())
System.out.print(": ");
while (aliases.hasNext()) {
System.out.print(aliases.next());
if (aliases.hasNext())
System.out.print(", ");
}
System.out.println();
}
}
}
/*
部分输出:
KOI8-U: koi8_u
Shift_JIS: shift_jis, x-sjis, sjis, shift-jis, ms_kanji, csShiftJIS
TIS-620: tis620, tis620.2533
US-ASCII: ANSI_X3.4-1968, cp367, csASCII, iso-ir-6, ASCII, iso_646.irv:1983, ANSI_X3.4-1986, ascii7, default, ISO_646.irv:1991, ISO646-US, IBM367, 646, us
UTF-16: UTF_16, unicode, utf16, UnicodeBig
UTF-16BE: X-UTF-16BE, UTF_16BE, ISO-10646-UCS-2, UnicodeBigUnmarked
UTF-16LE: UnicodeLittleUnmarked, UTF_16LE, X-UTF-16LE
UTF-32: UTF_32, UTF32
UTF-32BE: X-UTF-32BE, UTF_32BE
UTF-32LE: X-UTF-32LE, UTF_32LE
UTF-8: unicode-1-1-utf-8, UTF8
windows-1250: cp1250, cp5346
windows-1251: cp5347, ansi-1251, cp1251
windows-1252: cp5348, cp1252
windows-1253: cp1253, cp5349
*/
=====ByteBuffer.asCharBuffer()的局限:没指定编码,容易乱码=====
- 这个一般情况下不能用,为何:
- asCharBuffer()会把ByteBuffer转为CharBuffer,但用的是系统默认编码
1.5 视图缓冲器:ShortBuffer,IntBuffer, LongBuffer,FloatBuffer,DoubleBuffer,CharBuffer
- Buffer类型:
- ByteBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
- CharBuffer 字符串的缓冲区
- MappedByteBuffer 大文件的缓冲区
ByteBuffer系列的类继承关系挺有意思,可以研究研究
ByteArrayBuffer是其最通用子类,一般操作的都是ByteArrayBuffer
ByteBuffer.asLongBuffer(), asIntBuffer(), asDoubleBuffer()等一系列
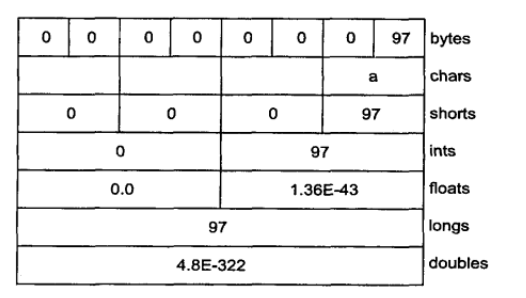
- 不多说:
- ByteBuffer底层是一个byte[],get()方法返回一个byte,1字节,8bit,10字节可以get几次?10次
- ByteBuffer.asIntBuffer()得到IntBuffer,底层是一个int[],get()方法返回一个int,还是10字节,可以get几次?
- 同理,还有ShortBuffer, LongBuffer, FloatBuffer, DoubleBuffer,这些就是ByteBuffer的一个视图,所以叫视图缓冲器
- asIntBuffer时,如果ByteBuffer本身有5个byte,则其中前4个会变成IntBuffer的第0个元素,第5个被忽略了,但并未被丢弃
- 往新的IntBuffer放数据(put(int)),默认时会从头开始写,写入的数据会反映到原来的ByteBuffer上
- 总结:
具体也说不明白了,其实就是你有什么类型的数据,就用什么类型的Buffer- 但直接往通道读写的,肯定是ByteBuffer,所以首先得有个ByteBuffer,其他视图Buffer,就得从ByteBuffer来
- 怎么从ByteBuffer来呢,ByteBuffer.asIntBuffer()等方法
例子:ViewBuffers.java
1.6 字节序
- 简介:
- 高位优先,Big Endian,最重要的字节放地址最低的存储单元,ByteBuffer默认以高位优先,网络传输大部分也以高位优先
- 低位优先,Little Endian
- ByteBuffer.order()方法切换字节序
- ByteOrderr.BIG_ENDIAN
- ByteOrderr.LITTLE_ENDIAN
- 对于00000000 01100001,按short来读,如果是big endian,就是97, 以little endian,就是24832
1.7 Scatter/Gather
一个Channel,多个Buffer,相当于多个运煤车在一个通道工作
读到多个Buffer里:
ByteBuffer header = ByteBuffer.allocate(128);
ByteBuffer body = ByteBuffer.allocate(1024);
ByteBuffer[] bufferArray = { header, body };
channel.read(bufferArray);
多个Buffer往channel写:
//注意,Buffer的长度是100,但只有50个数据,就只会写入50,换句话说,只有position和limit之间的内容会被写入(put完先flip一下,才能往channel写???)
ByteBuffer header = ByteBuffer.allocate(128);
ByteBuffer body = ByteBuffer.allocate(1024);
ByteBuffer[] bufferArray = { header, body };
channel.write(bufferArray);
1.8 内存映射文件:大文件的读写
大文件,如2G的文件,没法一下加载到内存中读写
MappedByteBuffer提供了一个映射功能,可以将文件部分载入到内存中,但你使用时,
感觉文件都在内存中了
MappedByteBuffer继承了ByteBuffer,所以可以像上面那样使用
MappedByteBuffer性能很高,远高于FileInputStream,FileOutputStream,RandomAccessFile的原始方式的读写,百倍速度
public static void main(String[] args) throws Exception {
//创建个文件,大小是128M
MappedByteBuffer out = new RandomAccessFile("test.dat", "rw")
.getChannel().map(FileChannel.MapMode.READ_WRITE, 0, length);
//写入
for (int i = 0; i < length; i++)
out.put((byte) 'x');
System.out.println("写入完毕");
//读取
for (int i = length / 2; i < length / 2 + 6; i++)
System.out.println((char) out.get(i));
}
1.9 文件加锁
- 简介
- 有时我们需要对文件加锁,以同步访问某个文件
- FileLock是使用了操作系统提供的文件加锁功能,所以可以影响到其他系统进程,其他普通进程,即使不是java写的
- FileLock.lock()会阻塞,tryLock不会阻塞
- lock系列方法可以带参数:
- 加锁文件的某一部分,多个进程可以分别加锁文件的一部分,数据库就是这样
- 参数3可以决定是否共享锁,这里又出现个共享锁和独占锁,共享锁需要操作系统支持
用法:
public static void main(String[] args) throws Exception {
FileOutputStream fos = new FileOutputStream("file.txt");
FileLock fl = fos.getChannel().tryLock();//---------
if (fl != null) {
System.out.println("Locked File");
TimeUnit.MILLISECONDS.sleep(100);
fl.release();//---------------------------------
System.out.println("Released Lock");
}
fos.close();
}
更多例子
package com.cowthan.nio;
//: io/LockingMappedFiles.java
// Locking portions of a mapped file.
// {RunByHand}
import java.nio.*;
import java.nio.channels.*;
import java.io.*;
public class LockingMappedFiles {
static final int LENGTH = 0x8FFFFFF; // 128 MB
static FileChannel fc;
public static void main(String[] args) throws Exception {
fc = new RandomAccessFile("test.dat", "rw").getChannel();
MappedByteBuffer out = fc
.map(FileChannel.MapMode.READ_WRITE, 0, LENGTH);
for (int i = 0; i < LENGTH; i++)
out.put((byte) 'x');
new LockAndModify(out, 0, 0 + LENGTH / 3);
new LockAndModify(out, LENGTH / 2, LENGTH / 2 + LENGTH / 4);
}
private static class LockAndModify extends Thread {
private ByteBuffer buff;
private int start, end;
LockAndModify(ByteBuffer mbb, int start, int end) {
this.start = start;
this.end = end;
mbb.limit(end);
mbb.position(start);
buff = mbb.slice();
start();
}
public void run() {
try {
// Exclusive lock with no overlap:
FileLock fl = fc.lock(start, end, false);
System.out.println("Locked: " + start + " to " + end);
// Perform modification:
while (buff.position() < buff.limit() - 1)
buff.put((byte) (buff.get() + 1));
fl.release();
System.out.println("Released: " + start + " to " + end);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
} // /:~
2 异步IO
-
关于Channel:
- FileChannel:永远都是阻塞模式,当然读本地文件也不会阻塞多久,没法和Selector配合
- DatagramChannel:通过UDP读写网络,无连接的
- SocketChannel:通过TCP读写网络
- ServerSocketChannel:监听新来的TCP连接,每个新进来的连接都会创建一个SocketChannel
-
简介:
- Selector提供了一个线程管理多个Channel的功能,与之相比,旧的Socket处理方式是每个Socket连接都在一个线程上阻塞
- Channel和Selector配合时,必须channel.configureBlocking(false)切换到非阻塞模式
- 而FileChannel没有非阻塞模式,只有Socket相关的Channel才有
- 概括:
- SocketServerChannel和SocketChannel的基本用法,参考socket.nio.NioXXServer和Client
- 可能会阻塞,可以通过channel.configureBlocking(false)设置非阻塞的地方:
- SocketChannel.connect(new InetSocketAddress(hostname, port)), 配合sc.finishConnect()判断是否连接成功
- SocketChannel sc = ssc.accept(),在非阻塞模式下,无新连接进来时返回值会是null
2.1 旧IO处理Socket的方式
要读取Socket上的Stream,就得在read时阻塞,所以每一个Socket都得一个线程管理,对于服务器来说,能开的线程数是有限的
2.2 不使用Selector,自己想法管理SocketChannel
@Override
public void run() {
while(!isClosed && !Thread.interrupted()){
for(String key: map.keySet()){
SocketChannel sc = map.get(key);
ByteBuffer buf = ByteBuffer.allocate(1024);
try {
int bytesRead = sc.read(buf);
buf.flip();
if(bytesRead <= 0){
}else{
System.out.println("收到消息(来自" + key + "):" + Charset.forName("utf-8").decode(buf));
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
-
弊端分析:
- 不断循环读取所有Channel,有数据则读出来
- 问题1:在while里,你sleep还是不sleep,sleep就损失太多实时性,不sleep就导致CPU大量空转
- 问题2:对于ServerSocketChannel,如果accept非阻塞,则需要while(true)不断判断是否有新连接,也浪费CPU
- 问题3:对于ServerSocket.connect(),如果非阻塞,则需要while(true)不断判断是否连接服务器成功,也浪费CPU
-
所以现在我们知道需要什么了
- 需要SocketChannel的read方法不阻塞
- 或者需要一个东西,可以在所有SocketChannel上等待,任何一个有了消息,就可以唤醒,这里面就有个监听的概念
- 并且可读,可写,accept(), connect()都应该对应不同的事件
- 这就引出了Selector,Selector就是java从语言层面和系统层面对这个问题的解决方案
2.3 Selector
使用Selector的完整示例:
Selector selector = Selector.open();
channel.configureBlocking(false);
SelectionKey key = channel.register(selector, SelectionKey.OP_READ);
while(true) {
int readyChannels = selector.select(); //就在这阻塞,但已经实现了一个线程管理多个Channel(SocketChannel-读写,connect事件,DatagramChannel-读写事件,SocketServerChannel-accept事件)
if(readyChannels == 0) continue;
Set selectedKeys = selector.selectedKeys();
Iterator keyIterator = selectedKeys.iterator();
while(keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if(key.isAcceptable()) {
// a connection was accepted by a ServerSocketChannel.
} else if (key.isConnectable()) {
// a connection was established with a remote server.
} else if (key.isReadable()) {
// a channel is ready for reading
} else if (key.isWritable()) {
// a channel is ready for writing
}
keyIterator.remove();
}
}
Selector selector = Selector.open();
SelectionKey selectionKey = sc.register(selector, SelectionKey.OP_READ);
//看Selector对哪些事件感兴趣
int interestSet = selectionKey.interestOps();
boolean isInterestedInAccept = (interestSet & SelectionKey.OP_ACCEPT) == SelectionKey.OP_ACCEPT;
boolean isInterestedInConnect = interestSet & SelectionKey.OP_CONNECT) == SelectionKey.OP_CONNECT;
boolean isInterestedInRead = interestSet & SelectionKey.OP_READ) == SelectionKey.OP_READ;
boolean isInterestedInWrite = interestSet & SelectionKey.OP_WRITE) == SelectionKey.OP_WRITE;
//通道中已经就绪的集合,每一次selection都得先访问这个,知道是因为哪些事件被唤醒的
int readySet = selectionKey.readyOps();
//或者:
selectionKey.isAcceptable();
selectionKey.isConnectable();
selectionKey.isReadable();
selectionKey.isWritable();
//拿到Channel和Selector
Channel channel = selectionKey.channel();
Selector selector = selectionKey.selector();
//对应关系是:1个Selector,多个Channel,多个SelectionKey,一个Channel对应一个SelectionKey,而且一个SelectionKey可以添加一个extra数据,以满足特定需求
//select方法:这才是会阻塞的地方,注意,在这里阻塞,是性能最佳的表现
int readyCount = selector.select() //select()阻塞到至少有一个通道在你注册的事件上就绪了
int readyCount = selector.select(long timeout) //最长会阻塞timeout毫秒(参数)
int readyCount = selector.selectNow() //不会阻塞,无则0
//返回值:有几个通道就绪
/*
select()方法返回的int值表示有多少通道已经就绪。亦即,自上次调用select()方法后有多少通
道变成就绪状态。如果调用select()方法,因为有一个通道变成就绪状态,返回了1,若再次调用select()方法,
如果另一个通道就绪了,它会再次返回1。如果对第一个就绪的channel没有做任何操作,现在就有两个就绪的通
道,但在每次select()方法调用之间,只有一个通道就绪了
*/
//有通道就绪了,就得得到这个Channel,通道存在SelectionKey里,而selector可以获得一个SelectionKey集合
Set selectedKeys = selector.selectedKeys();
Iterator keyIterator = selectedKeys.iterator();
while(keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if(key.isAcceptable()) {
// a connection was accepted by a ServerSocketChannel.
} else if (key.isConnectable()) {
// a connection was established with a remote server.
} else if (key.isReadable()) {
// a channel is ready for reading
Channel channel = key.channel();
} else if (key.isWritable()) {
// a channel is ready for writing
}
keyIterator.remove();
}
-
register方法参数:Channel事件
- 参数表示Selector对Channel的什么事件感兴趣
- Connect:SelectionKey.OP_CONNECT
- Accept:SelectionKey.OP_ACCEPT
- Read:SelectionKey.OP_READ
- Write:SelectionKey.OP_WRITE
- 可以组合:int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
-
SelectionKey都有啥信息:
- interest集合:对哪些事件感兴趣
- ready集合:感兴趣的事件集中,哪些事件准备就绪了
- Channel:监听的哪个Channel
- Selector:谁在监听
- 可选的extra
- 唤醒阻塞的Selector:在select方法的阻塞
- 情况1:有感兴趣的事件来了
- 情况2:手动调用Selector.wakeup(),只要让其它线程在第一个线程调用select()方法的那个对象上调用Selector.wakeup()方法即可
- 如果有其它线程调用了wakeup()方法,但当前没有线程阻塞在select()方法上,下个调用select()方法的线程会立即“醒来(wake up)”。
- 关闭Selector
- close()方法,关闭该Selector,且使注册到该Selector上的所有SelectionKey实例无效
- 通道本身并不会关闭
3 DatagramChannel:UDP通信
略过
4 Pipe
- 简介:
- Pipe用于线程通信,两个Thread由一个Pipe连接
- pipe的两端,一端是SinkChannel,负责写入,一端是SourceChannel,负责读取
- 所以pipe是单向通信
- 两个Pipe就可以实现双向通信
看图:
Pipe pipe = Pipe.open();
//写入
Pipe.SinkChannel sinkChannel = pipe.sink();
String newData = "New String to write to file..." + System.currentTimeMillis();
ByteBuffer buf = ByteBuffer.allocate(48);
buf.clear();
buf.put(newData.getBytes());
buf.flip();
while(buf.hasRemaining()) {
sinkChannel.write(buf);
}
//读取
Pipe.SourceChannel sourceChannel = pipe.source();
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = sourceChannel.read(buf);
5 Okio
github: https://github.com/square/okio
只是对旧IO的封装,没用到Channel,也没用到ByteBuffer
5.1 简介:
- 基本接口
- Source:接口,like InputStream
- 输入流,输入到内存,从Source读
- long read(Buffer sink, long byteCount) throws IOException
- 返回-1表示EOF,写到sink里
- Timeout timeout()
- 返回这个source的超时信息
- void close() throws IOException
- Sink:接口,like OutputStream
- 输出流,从内存输出,往Sink写
- void write(Buffer source, long byteCount) throws IOException
- 从source读到sink
- Timeout timeout();
- void close() throws IOException;
- BufferedSource:接口,extends Source
- 输出缓冲流
- 提供了一系列读方法
- 实现类:RealBufferedSource,需要传入一个Source,所以这是一个包装类
- BufferedSink:接口,extends sink
- 输入缓冲流
- 提供了一系列写方法
- 实现类:RealBufferedSink,需要传入一个Sink,所以这是一个包装类
- Sink和Source只有3个接口,实现方便,而BufferedSource和BufferedSink提供了一堆便利方法
- Timeout:读写时有Timeout,主要给Socket用
- byte stream和char stream的读写没有什么区别,当做byte[], utf8 String,big-endian,little-endian都行,不再用InputStreamReader了
- Easy to test. The Buffer class implements both BufferedSource and BufferedSink so your test code is simple and clear.
- 互操作:Source和InputStream可以互换,Sink和OutputStream可以互换,无缝兼容
- Source:接口,like InputStream
-
实用类:
- DeflaterSink,InflaterSource
- ForwardingSink,ForwardingSource
- GzipSink,GzipSource
- HashingSink,HashingSource
-
ByteString和Buffer
- ByteString:处理字符串
- 一个不可变的byte序列,immutable sequence of bytes
- String是基本的,ByteString是String的long lost brother
- 提供便利方法处理byte
- 能decode和encode,处理hex, base64, and UTF-8
- Buffer:处理byte流
- 一个可变的byte序列,mutable sequence of bytes,像个ArrayList
- 读写时行为像Queue,write to end,read from front
- 不需要考虑大小,屏蔽了ByteBuffer的capacity,limit,position等
- 缓存:把一个utf-8 String decode成ByteString,会缓存,下次再decode,就快了
- Buffer是一个Segment的LinkedList,所以拷贝不是真的拷贝,只是移动,所以更快
- 多线程工作时就有优势了,连接network的线程可以迅速的把数据发给work线程(without any copying or ceremony)
- ByteString:处理字符串
-
工具
- AsyncTimeout
- Base64
- Options
- Timeout
- Util
- Okio
-
Segment相关
- Segment
- SegmentPool
- SegmentedByteString
5.2 使用
构造BufferedSink和BufferedSource
//创建Source
Source source = Okio.source(final InputStream in, final Timeout timeout);
source(InputStream in); //new Timeout()
source(File file);
source(Path path, OpenOption... options); //java7
source(Socket socket);
//创建Sink
Sink sink = Okio.sink(OutputStream out);
sink(final OutputStream out, final Timeout timeout);
sink(File file)
appendingSink(File file)
sink(Path path, OpenOption... options)
sink(Socket socket)
//创建BufferedSource:
BufferedSource pngSource = Okio.buffer(Source source); //返回RealBufferedSource对象
BufferedSink pngSink = Okio.buffer(Sink sink); //返回RealBufferedSink对象
//从BufferedSource读取
看例子吧
//往BufferedSink写入
看例子吧
//ByteString
看例子吧
//Buffer
看例子吧
5.3 例子:来自官网
package com.cowthan.nio.okio;
import java.io.IOException;
import java.io.InputStream;
import okio.Buffer;
import okio.BufferedSource;
import okio.ByteString;
import okio.Okio;
public class Test1_png {
public static void main(String[] args) throws IOException {
InputStream in = Test1_png.class.getResourceAsStream("/com/demo/1.png");
decodePng(in);
}
private static final ByteString PNG_HEADER = ByteString
.decodeHex("89504e470d0a1a0a");
public static void decodePng(InputStream in) throws IOException {
BufferedSource pngSource = Okio.buffer(Okio.source(in));
ByteString header = pngSource.readByteString(PNG_HEADER.size());
if (!header.equals(PNG_HEADER)) {
throw new IOException("Not a PNG.");
}
while (true) {
Buffer chunk = new Buffer();
// Each chunk is a length, type, data, and CRC offset.
int length = pngSource.readInt();
String type = pngSource.readUtf8(4);
pngSource.readFully(chunk, length);
int crc = pngSource.readInt();
decodeChunk(type, chunk);
if (type.equals("IEND"))
break;
}
pngSource.close();
}
private static void decodeChunk(String type, Buffer chunk) {
if (type.equals("IHDR")) {
int width = chunk.readInt();
int height = chunk.readInt();
System.out.printf("%08x: %s %d x %d%n", chunk.size(), type, width,
height);
} else {
System.out.printf("%08x: %s%n", chunk.size(), type);
}
}
}
