概述
可迭代对象、迭代器和生成器这三个概念很容易混淆,前两者通常不会区分的很明显,只是用法上有区别。生成器在某种概念下可以看做是特殊的迭代器,它比迭代实现上更加简洁。三者关系如图: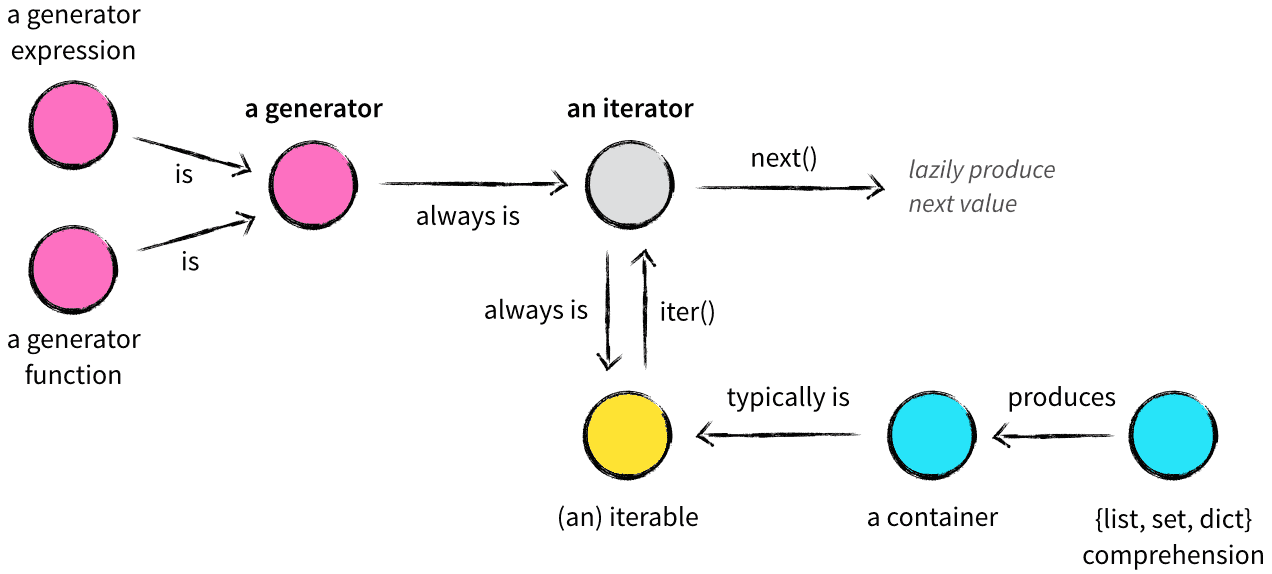
可迭代对象
先说下上面三者的基础:可迭代对象(Iterable Object),简单的来理解就是可以使用 for 来循环遍历的对象。比如常见的 list、set和dict。可以用以下方法来测试对象是否是可迭代
>>> from collections import Iterable
>>> isinstance('abc', Iterable) # str是否可迭代
True
>>> isinstance([1,2,3], Iterable) # list是否可迭代
True
>>> isinstance(123, Iterable) # 整数是否可迭代
False
迭代器
其实你对所有的可迭代对象调用 dir() 方法时,会发现他们都实现了 __iter__ 方法。这样就可以通过 iter(object) 来返回一个迭代器。
>>> x = [1, 2, 3]
>>> y = iter(x)
>>> type(x)
<class 'list'>
>>> type(y)
<class 'list_iterator'>
可以看到调用 iter() 之后,变成了一个 list_iterator 的对象。会发现增加了 __next__ 方法。所有实现了 __iter__ 和 __next__ 两个方法的对象,都是迭代器。
迭代器是带状态的对象,它会记录当前迭代所在的位置,以方便下次迭代的时候获取正确的元素。__iter__返回迭代器自身,__next__返回容器中的下一个值,如果容器中没有更多元素了,则抛出StopIteration异常。
>>> x = [1, 2, 3]
>>> y = iter(x)
>>> next(y)
1
>>> next(y)
2
>>> next(y)
3
>>> next(y)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
具体的实现我没有深入研究。但是我大胆的猜测一下...联系操作系统中 printf(fmt,...) 的实现方式,其中是定义一个 va_list 来用于保存需要打印的 ... 信息的。然后实现了va_start() va_end() va_arg() 三个方法来不停地迭代式的打印信息。感兴趣可以自己了解。
那回到Iterator ,如何判断对象是否是迭代器,和判断是否是可迭代对象的方法差不多,只要把 Iterable 换成 Iterator。
Python的for循环本质上就是通过不断调用next()函数实现的,举个栗子,下面的代码
x = [1, 2, 3]
for elem in x:
...
实际上执行时是
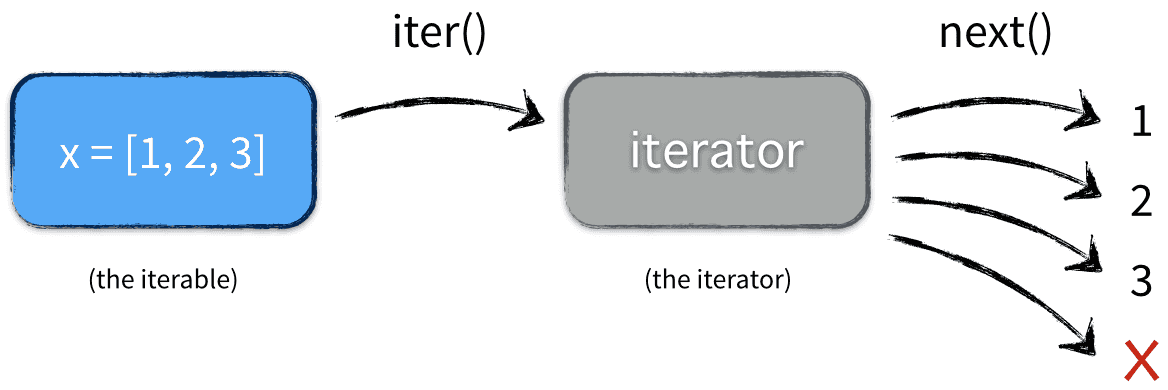
也就是先将可迭代对象转化为Iterator,再去迭代。应该是处于对内存的节省考虑。因为迭代器只有在你调用 next() 才会实际计算下一个值。
itertools 库提供了很多常见迭代器的使用
>>> from itertools import count # 计数器
>>> counter = count(start=13)
>>> next(counter)
13
>>> next(counter)
14
无限循环序列:
>>> from itertools import cycle
>>> colors = cycle(['red', 'white', 'blue'])
>>> next(colors)
'red'
>>> next(colors)
'white'
>>> next(colors)
'blue'
>>> next(colors)
'red'
生成器
生成器和装饰器是python中最吸引人的两个黑科技,生成器虽没有装饰器那么常用,但在某些针对的情境下十分有效。
我们创建列表的时候,受到内存限制,容量肯定是有限的,而且不可能全部给他一次枚举出来。这里可以使用列表生成式,但是它有一个致命的缺点就是定义即生成,非常的浪费空间和效率。
所以,如果列表元素可以按照某种算法推算出来,那我们可以在循环的过程中不断推算出后续的元素,这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个 generator ,最简单的方法是改造列表生成式
>>> [x*x for x in range(10)]
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> (x * x for x in range(10))
<generator object <genexpr> at 0x03804630>
还有一个方法是生成器函数,同样是通过 def 定义,然后通过 yield 来支持迭代器协议,所以比迭代器写起来更简单。
>>>def spam():
yield"first"
yield"second"
yield"third"
>>> spam
<function spam at 0x011F32B0>
>>> gen
<generator object spam at 0x01220B20>
>>> gen.next()
'first'
>>> gen.next()
'second'
>>> gen.next()
'third'
当然一般都是通过for来使用的,这样不用关心StopIteration的异常
>>>for x in spam():
print x
first
second
third
进行函数调用的时候,返回一个生成器对象。在使用 next() 调用的时候,遇到 yield 就返回,记录此时的函数调用位置,下次调用 next() 时,从断点处开始。
的确有时候,迭代器和生成器很难区分,如文章开头所说,generator 是比 Iterator 更加简单的实现方式。官方文档有这么一句
Python’s generators provide a convenient way to implement the iterator protocol.
你完全可以像使用 iterator 一样使用 generator ,当然除了定义。定义一个iterator,你需要分别实现 __iter__() 方法和 __next__() 方法,但 generator 只需要一个小小的yield 。
generator 还有 send() 和 close() 方法,都是只能在next()调用之后,生成器出去挂起状态时才能使用的。
生成器在Python中是一个非常强大的编程结构,可以用更少地中间变量写流式代码,此外,相比其它容器对象它更能节省内存和CPU,当然它可以用更少的代码来实现相似的功能。现在就可以动手重构你的代码了,但凡看到类似:
def something():
result = []
for ... in ...:
result.append(x)
return result
都可以用生成器函数来替换:
def iter_something():
for ... in ...:
yield x
提示:python 是支持协程的,也就是微线程,就是通过 generator 来实现的。配合 generator 我们可以自定义函数的调用层次关系从而自己来调度线程。
斐波那契数列
下面用 普通函数,迭代器和生成器来实现斐波那契数列,区分三种
输出数列的前N个数
函数方法
def fab(max):
n,a,b = 0,0,1
L = []
while n < max:
L.append(b)
a,b = b,a+b
n += 1
return L
这个不多说
Iterator方法
为了节省内存,和处于未知输出的考虑,使用迭代器来改善代码。
class fab(object):
'''
Iterator to produce Fibonacci
'''
def __init__(self,max):
self.max = max
self.n = 0
self.a = 0
self.b = 1
def __iter__(self):
return self
def __next__(self):
if self.n < self.max:
r = self.b
self.a,self.b = self.b,self.a + self.b
self.n += 1
return r
raise StopIteration('Done')
迭代器什么都好,就是写起来不简洁。所以用 yield 来改写第三版。
Generator
def fab(max):
n,a,b = 0,0,1
while n < max:
yield b
a,b = b,a+b
n += 1
使用下面来输出
for a in fab(8):
print(a)
看起来很简洁,而且有了迭代器的特性。
装饰器
装饰器(Decorator)是python中最吸引人的特性,装饰器本质上还是一个函数,它可以让已有的函数不做任何改动的情况下增加功能。
非常适合有切面需求的场景,比如权限校验,日志记录和性能测试等等。比如你想要执行某个函数前记录日志或者记录时间来统计性能,又不想改动这个函数,就可以通过装饰器来实现。
不用装饰器,我们会这样来实现在函数执行前插入日志
def foo():
print('i am foo')
def foo():
print('foo is running')
print('i am foo')
虽然这样写是满足了需求,但是改动了原有的代码,如果有其他的函数也需要插入日志的话,就需要改写所有的函数,不能复用代码。可以这么写
def use_logg(func):
logging.warn("%s is running" % func.__name__)
func()
def bar():
print('i am bar')
use_log(bar) #将函数作为参数传入
这样写的确可以复用插入的日志,缺点就是显示的封装原来的函数,我们希望透明的做这件事。用装饰器来写
bar = use_log(bar)def use_log(func):
def wrapper(*args,**kwargs):
logging.warn('%s is running' % func.__name___)
return func(*args,**kwargs)
return wrapper
def bar():
print('I am bar')
bar = use_log(bar)
bar()
use_log() 就是装饰器,它把真正我们想要执行的函数 bar() 封装在里面,返回一个封装了加入代码的新函数,看起来就像是 bar() 被装饰了一样。这个例子中的切面就是函数进入的时候,在这个时候,我们插入了一句记录日志的代码。这样写还是不够透明,通过@语法糖来起到 bar = use_log(bar) 的作用。
bar = use_log(bar)def use_log(func):
def wrapper(*args,**kwargs):
logging.warn('%s is running' % func.__name___)
return func(*args,**kwargs)
return wrapper
@use_log
def bar():
print('I am bar')
@use_log
def haha():
print('I am haha')
bar()
haha()
这样看起来就很简洁,而且代码很容易复用。可以看成是一种智能的高级封装。
装饰器也是可以带参数的,这位装饰器提供了更大的灵活性。
def use_log(level):
def decorator(func):
def wrapper(*args, **kwargs):
if level == "warn":
logging.warn("%s is running" % func.__name__)
return func(*args)
return wrapper
return decorator
@use_log(level="warn")
def foo(name='foo'):
print("i am %s" % name)
foo()
实际上是对装饰器的一个函数封装,并返回一个装饰器。这里涉及到作用域的概念,之前有一篇博客提到过。可以把它看成一个带参数的闭包。当使用 @use_log(level='warn') 时,会将 level 的值传给装饰器的环境中。它的效果相当于 use_log(level='warn')(foo) ,也就是一个三层的调用。
这里有一个美中不足,decorator 不会改变装饰的函数的功能,但会悄悄的改变一个 __name__ 的属性(还有其他一些元信息),因为 __name__ 是跟着函数命名走的。可以用 @functools.wraps(func) 来让装饰器仍然使用 func 的名字。比如
import functools
def log(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
functools.wraps 也是一个装饰器,它将原函数的元信息拷贝到装饰器环境中,从而不会被所替换的新函数覆盖掉。
有了装饰器,我们就可以剥离出大量与函数功能本身无关的代码,增加了代码的重用性。
