标签(空格分隔): 数据挖掘 数据分析 数据采集
网站数据采集、功能配置、系统实施和基本运营都是网站数据分析师的工作,一个高水平的网站数据分析师必须具备整体网站数据工作的能力。
1、网站数据采集以及系统数据的处理配置
完整的网站数据工作机制包括数据采集、数据处理和数据报告三个部分。

数据采集
数据采集分两层:
1、第一层是通过特定页面或Activity标记实现在线数据采集,在线数据是网站数据的核心组成;
2、第二层是通过外部系统或手动形式导入的外部数据源,外部数据源是在线数据的拓展。
在线数据采集根据平台可分为Web站、WAP站和APP站。Web站及以HTML 5开发的WAP站都支持JS脚本采集;较早开发的不支持JS的WAP站则采用NoScript,即一个像素的硬图片实现数据跟踪;SDK是针对APP进行数据采集的特定方法和框架。这三种方法可以实现目前所有线上数据采集的需求。
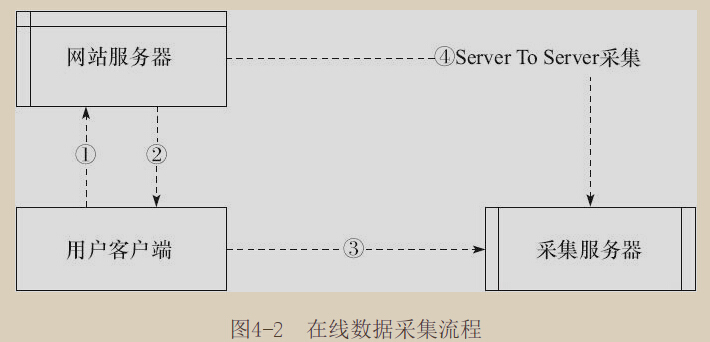
这种客户端-服务器的数据采集方法适用于大多数的数据采集需求,但在这种采集方法的前期页面标记需要在用户客户端触发才能实现,如果数据不是通过用户客户端触发,在网站外部则无法收集(比如说支付宝的支付页面)。
由于数据经历了从网站服务器->用户客户端->采集服务器三个节点,从网站服务器到用户客户端的过程可能会有数据丢失的情况,尤其在订单结算等核心信息中,这种客户端-服务器的采集方法可靠性较小。
(注意:不管采用何种采集方法,任何网站分析系统的数据都不可能与企业内部数据系统中的数据完全一致,对网站分析系统中数据准确性的要求是数据误差与企业数据系统误差率较小(通常在5%以下)且数据误差率稳定。)
针对上述情况,某些网站分析系统如Webtrekk支持Server to Server(S-S,网站服务器对采集服务器)的方法进行在线数据采集,避免数据在客户端的中转流失。
所有在线数据采集都会受到采集规则的制约,比如排除特定IP地址的流量、只采集某个域名下的数据等。数据采集规则是数据采集的重要控制节点,如果出现某些排除、隐藏或直接忽视数据的采集规则,将可能导致数据丢失。
(不明白为什么SAAS网站分析系统都不能处理历史数据,这意味着如果在数据采集阶段出现数据丢失将会产生无法挽回的后果,建议原始初级采集阶段不设定任何排除规则;如果数据中可能含有大量的内部测试数据,测试环境与生产环境应分账号采集)
外部接入数据根据接入方式的不同可分为API接入、Excel接入和Log接入。
- API是主流的大批量数据集成方法,常见的数据源系统包括Baidu和Google的SEM数据、EDM数据等营销类数据,以及企业CRM数据等用户类数据、企业订单及销售数据等。
- Excel是临时性、小数据量的导入方式。
- Log是原始服务器日志,部分网站分析系统如Webtrends支持混合页面标记数据和日志数据,共同作为网站分析系统的数据源,支持Log的网站分析系统主要采用Local,即本地服务器形式,数据直接在企业内部交换。
外部数据接入与在线数据采集是异步进行的。外部接入数据进入网站分析系统后,根据数据处理层的处理规则,在经过数据抽取、加载、转换之后,与在线采集数据整合形成完整的数据源。
外部接入数据的工作流程如下,原始的外部数据(文档、服务器日志、在线其他系统数据、离线数据)通过自动或人工整理形成符合特定规范的数据文件或带制表符分隔的数据文档,然后根据接入机制的不同完成数据的整合工作。
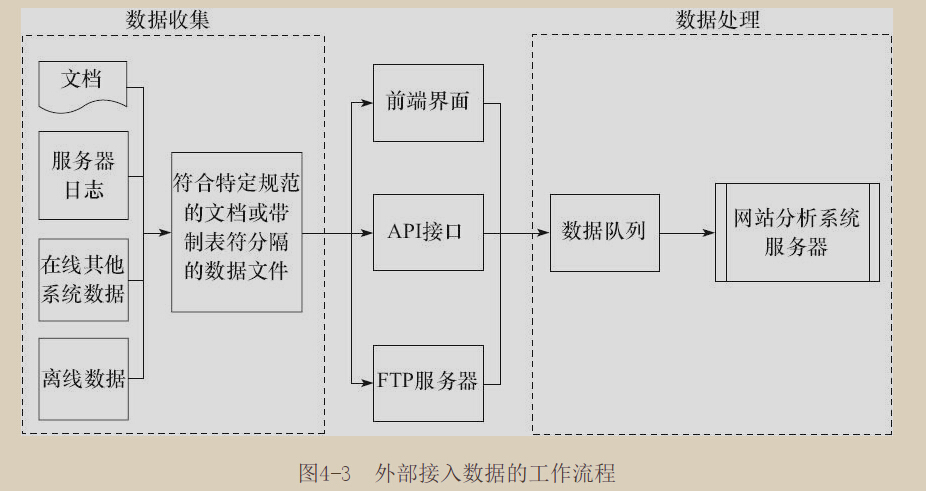
原始的外部数据(文档、服务器日志、在线其他系统数据、离线数据)通过自动或人工整理形成符合特定规范的数据文件或带制表符分隔的数据文档,然后根据接入机制的不同完成数据的整合工作。
- 文档类数据文件通常是通过前端界面手动上传实现数据导入的;
- 在线其他系统数据以及离线数据通过API进入网站分析系统;
- 服务器日志,在线其他系统数据以及离线数据也可以通过特定的FTP服务器上传数据。具体流程为:企业内部通过程序生成特定的数据文档,并按照一定时间性的特征自动上传到网站分析系统指定的FTP服务器,网站分析系统从FTP服务器采集数据,通过验证后处理数据。
(考虑到IT人力、物力和时间投入等因素考虑,通过FTP导入数据的方式更易于实现。前期可以考虑使用FTP自动上传的机制,待数据需求稳定切业务实现思路无误后再通过技术手段开发API。)
