1. 简介
当RegionServer接收客户的write请求后,会在memstore中不断的堆积。直到达到flush阈值时,便会flush到disk上,并以store files的形式存储。
RegionServer可以有1 ~ N个region,一个region可以包含1~N store files。
当store files越来越多后,RegionServer会根据region split policy策略决定对它们进行压缩,具体表现为让一个region变的更大,还是让一个region拆分成多个子region。
RegionServer 在split之前和之后都要通知master修改.meta.表信息,一边与让client及时察觉到region的变化。并重新排列数据文件在HDFS中目录结构。
在splitting过程中,是多任务多处理的,所有的执行状态都被一个in-memory 的日志里记录 。若遇到error是可以被rollback。
2. Spilt 过程示例
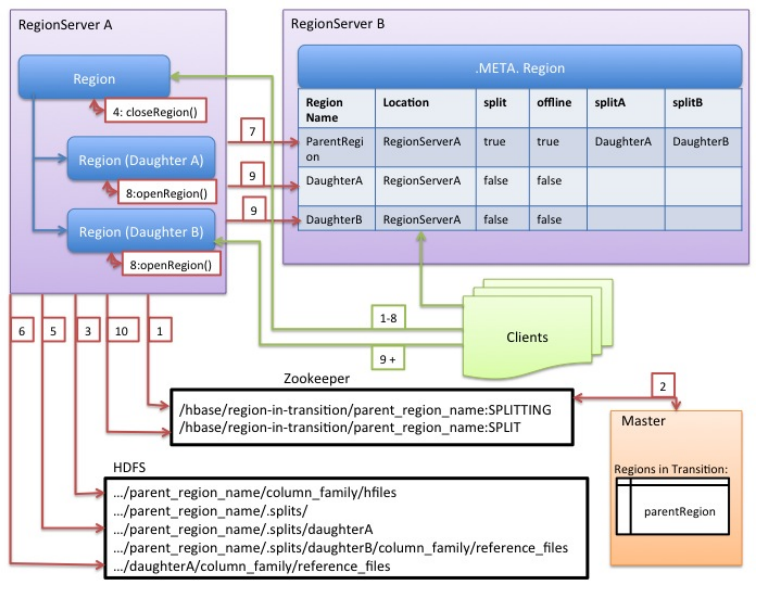
处理步骤:
RegionServer先获得一个table的read共享锁,避免schema在split处理期间发生修改。
然后在zookeeper的znone上创建一个节点/hbase/region-in-transition/region-name,状态标识为splitting 。Master节点会监听zookeeper的region-in-transition节点下所有子节点的变化。
在HDFS上的待split的region目录下创建子目录.splits。
RegionServer将region 关闭closes,同时将它标识为offline状态。
此时,若有client请求次region数据,则会抛出NotServingRegionException,并可能做一些retry操作。接着,RegionServer在.splits目录下生成子daughter A 和B,并创建必须的数据结构。然后就开始splits store files 。就某种意义而已,只是对每个store file 创建两个 Reference files 并指向parent region’s files。
6.接着,RegionServer在HDFS上创建真实的新daughter目录A 和B ,与parent平级。并将第5步中的reference files分别move到daughter A 和 region B中。
然后,RegionServer 就发送请求去更新.meta table信息,设置parent 为offline,同时增加新的子region信息 ,如图中[7]箭头指向行 splitA和splitB信息。
同时并行的打开新的 daughter A 和 daughter B region 。
接着,RegionServer 添加daughters A and B 到 .META.如图中[]箭头指向的两行。
此时,这两个region的状态是online 。这是clients可以发现新的region,同时更新自己的.meta.缓存。最后,RegionServer 更新znode节点 /hbase/region-in-transition/region-name为SPLIT。如此,master可以学习到。负载均衡时,可以指向到新的子region。
3. 垃圾回收
在split过程中, .META. and HDFS产生的 references to the parent region临时数据。
这些将会被Garbage collection tasks 回收掉。
