在给出图的定义后第一个问题就是如何遍历图的所有顶点,有两种最基础的图遍历算法。如果给图添加更多的特征和属性,将产生更多关于图的算法,例如最短路径算法。
广度/深度优先搜索算法最早是解决迷宫问题时发现的。深度优先搜索算法(DFS)算法从图的任一顶点出发,尽量在回溯到源节点之前在每个分支上走的更远。DFS算法的复杂度为O(V+E),与图的大小成线性关系;空间复杂度上最坏情况是O(V),此时需要把图的全部顶点进栈。BFS算法1950年被 Moore 发现,以寻找迷宫最短路径;BFS和DFS算法的时空复杂度一致。
深度优先搜索算法
假设节点左枝干优先级大于右枝干,搜索从A开始,且假设搜索过程能记住先前访问的节点而不再重复访问它们,所以访问的顺序是ABDFECG.

DFS伪代码
Input: 图G和顶点v
Output: 生成树(spanning tree)
递归实现
procedure DFS(G,v){
mark v as Reached;
for(Vertex w:v.getAllVertexs(){
if(w.isReached==false)
recursively call DFS(G,w);
}
}
非递归实现
procedure DFS(G,v){
let S as a stack;
S.push(v);
while(S.isEmpty()==false){
w = S.pop();
if(w.isReached==false){
mark v as Reached;
for(Edges edge:v.getAllEdges(){
S.push(w);
}
}
}
}
递归和迭代方法的区别访问子节点顺序不同,导致最终生成树不同。前者是A, B, D, F, E, C, G,后者是A, E, F, B, D, C, G.
DFS和BFS两种算法的区别在于:前者用栈,后者用队列来存储以访问过的节点;前者先出队再标记,后者先标记再出队。
广度优先搜索算法
伪代码
Input: 图G和顶点v
Output: 生成树(spanning tree)
广度优先搜索没有递归实现,只有非递归实现
BFS(Graph g,Vertex v){
let Q as a queue;
q.enqueue(v);
while(q.isEmpty()==false){
Vertex current = Q.dequeue();
for(Vertex w:current.getAllVertexs()){
if(w.isReached()==false)
w.enqueue();
}
}
}
与DFS区别在于
1.使用队列而非栈
2.监测节点是否已经访问并标记节点在入队前,而不是在入队后。
算法优劣
DFS的问题可以用下图说明
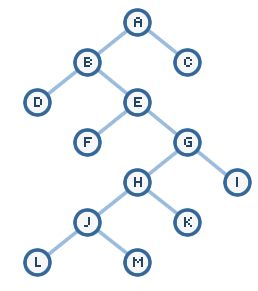
当查找
C顶点时,DFS的搜索路径是a, b, d, e, f, g, h, j, l, m, k, i, c,其不合理是显而易见的。这意味着当经常被访问的资源挂在右节点上算法将有较大的性能浪费。不过这也说明,使用这种算法,重要的资源要挂在左边。
同时DFS深度优先搜索是一个P完全问题,意味着其无缘于并行计算。
参考文献
wiki/Depth-first_search
wiki/Breadth-first_search
www.kirupa.com/developer/depth_breadth_search7.htm
wiki/Shortest_path_problem
visualization/Algorithms.html
