[只是大框架介绍,实际使用中的不容易注意的细节太多了,需要经验的积累,才能运用娴熟]
以下的架构都是在假设已经优化过linux内核的情况下进行
**初级篇:(单机模式)
**假设配置:(Dual core 2.0GHz,4GB ram,SSD)
基础框架:apache(PHP) + Mysql / IIS + MSSQL(最基础框架,处理一般访问请求)
进阶1:替换Apache为Nginx,并在数据库前加上cache层【数据库的速度是最大的瓶颈】
Nginx(PHP) + Memcache + Mysql(此时已经具备处理小型访问量的能力)
进阶2:随着访问量的上涨,最先面临的问题就来了:CGI无法匹配上Nginx的高IO性能,这时候可以通过写扩展来替代脚本程序来提升性能,C扩展是个好办法,但是大家更喜欢用简单的脚本语言完成任务,Taobao团队开源了一个Nginx_lua模块,可以用lua写Nginx扩展,这时候可处理的并发已经超越进阶1 一个档次了。
Nginx(nginx_lua or C) + Memcache + Mysql(此时处理个同时在线三四千人没有问题了)
进阶3:随着用户的增多,Mysql的写入速度成了又一大瓶颈,读取有memcache做缓存,但写入是直接面对Mysql,性能受到了很大阻碍,这时候,要在Nginx和Mysql中间加入一层写缓存,队列系统就出场了,就以RabbitMQ为例,所有写入操作全部丢到这只兔子的胃里面,然后屁股后面写个接应程序,一条条的拉出来再写入mysql。而RabbitMQ的写入效率是Mysql的N倍,此时架构的处理能力又上一阶层。
|----write------>RabbitMQ--------
Nginx(lua or c)----- |--------->Mysql
|----read------>Memcache--------
(此时的并发吞吐能力已经可以处理万人左右在线)
中级篇:(分而治之)
此时我们在单机优化上已经算是达到极限,接下来就要集群来显示作用了。
数据库篇:
数据库总是在整个环节中是吞吐能力最弱的,最常见的方法就是sharding。sharding可以按多种方法来分,没有定式,看情况。可以按用户ID区段分,按读写分等等,可用参考软件:mysql proxy(工作原理类似lvs)
缓存篇:
memcache一般采用的是构建memcache pool,将缓存分散到多台memcache节点上,如何将缓存数据均匀分散在各节点,一般采用将各节点顺序编号,然后hash取余对应到各个节点上去。这样可以做到比较均匀的分散,但是有一个致命点就是,如果节点数增加或减少,将会带来几乎80%的数据迁移,解决方案我们在高级篇再提。
**WEB服务器篇: **
web服务器集群的建设,最常见的就是lvs方式(memcache pool同样可以如此组建),lvs的核心就是调度节点,调度节点负责将流量通过算法分散到各个节点上,因调度所耗资源很少,所以可以产生很高的吞吐率,后台节点数量可以任意增删,但此法弊病就是如果调度节点挂了,则整个集群都挂了,解决方案我们在高级篇提。方法2:参见 HAProxy - The Reliable, High Performance TCP/HTTP Load Balancer**
**高级篇:(高可用性+高可扩展性的集群)
****单点调度故障解决:**
集群的好处显而易见,但是有一个弊端就是单节点进行调度,如果节点出现故障,则整个集群全部都无法服务,对此的解决方案,我们使用keepalived来解决。Keepalived for Linux**keepalived是基于VRRP协议(VRRP协议介绍**)的,请一定先了解VRRP协议后再进行配置。keepalived可以把多台设备虚拟出一个IP,并自动在故障节点与备用节点之间实现failover切换。这样我们配置两台货多台lvs调度节点,然后配置好keepalived就可以做到lvs调度节点出现故障后,自动切换到备用调度节点。(同样适用于mysql)
memcache集群扩展解决:
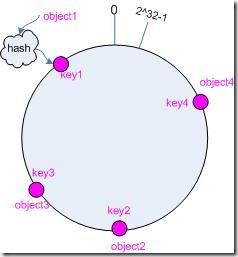
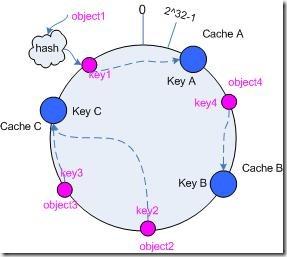
memcache因为我们一般采用的都是hash后除以节点数取余,然后分配到对应节点上,如果节点数出现变化,以前的缓存数据将基本都不能命中。解决方法:consistent hashing 简介:一致性哈希**consistent hashing大概的思路就是,把hash后的值保证在 0 ~ (2^32)-1 的数值上,然后把这一连串数字对应映射到一个想象的圆上。
作者:牛浩帆链接:https://www.zhihu.com/question/20657269/answer/15763722来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
