Record Linkage即在不同数据集中找出同一个实体的描述记录(如下所示)。主要目的是对不同数据源中的实体信息进行整合,形成更加全面的实体信息。

Data Preprocessing
原始数据集的质量会直接影响Record Linkage的结果(如下所示),不同数据集对同一信息的描述往往并不一样,比如时间描述、缩写、错误等等。对常识性的数据进行归一化处理能够极大的提高后续步骤的准确率。
| Data set | Name | Date of birth | City of residence |
|---|---|---|---|
| Data set 1 | William J. Smith | 1/2/73 | Berkeley, California |
| Data set 2 | Smith, W. J. | 1973.1.2 | Berkeley, CA |
| Data set 3 | Bill Smith | Jan 2, 1973 | Berkeley, Calif. |
Algorithm Framework
在知识图谱实体融合过程中,基本问题是判断两个实体是否可以融合。假设两个知识图谱所包含的实体数目分别为n1和n2,那么需要判断的实体对数目为n1 * n2,当两个知识图谱实体数目在千万规模时,无法对所有可能的实体对进行计算,所以基本算法框架是先对所有的实体进行Blocking操作,然后对每个Blocking内的每一对实体进行判断,是典型的MapReduce架构。类似设计见这里,这里,这里。
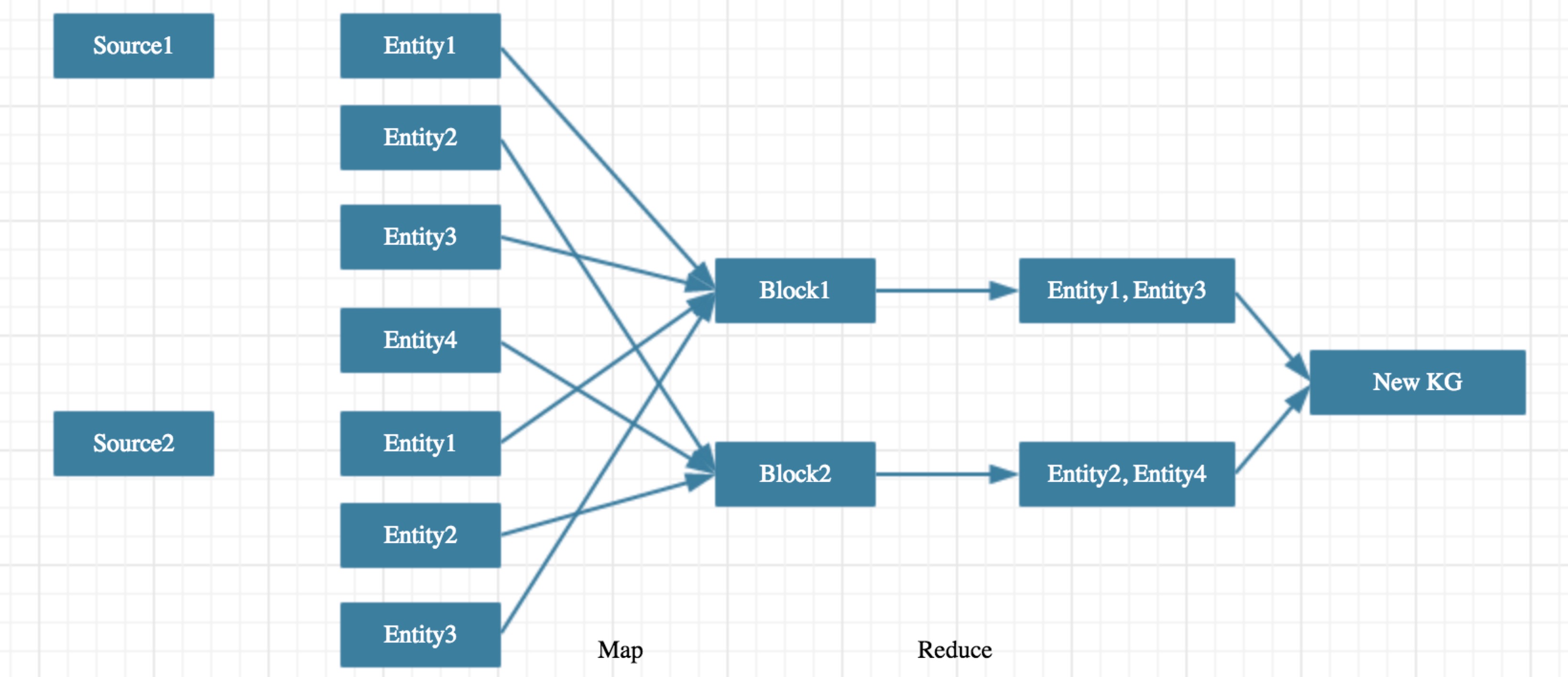
Map Stage
本阶段目标是将全部实体集合拆分成相互无关的实体子集,拆分过程中保证所有潜在可融合的实体对都分到同一子集中,后续的计算过程所有子集可以并行计算,相互之间没有依赖。
理想情况下,我们只需要设计Partition函数hash_func(entity) = block_id来得到每个实体所属的block。但在具体操作过程中可能会遇到实体分布不均的问题,即某一个block内的实体数远大于其他block,从而导致整个算法运行时间大大增加。所以需要额外进行Load Balance来保证所有block中的实体数相当,同时保证不会漏掉任何可能融合的实体对。
Partition
针对不同的任务,Partition函数的选择会有所不同。在特定领域内进行实体融合时,完全可以根据领域特定知识来设计,比如在领域内有明确区分度的字段,实际效果往往被复杂的算法更好。在通用领域主要方法有如下几种:
- Hierarchical Clustering
- Nearest Neighbor based methods
- Correlation Clustering, greeding algo
Load Balance
对于Load Balance问题,这篇文章给出了详细的策略,基本框架是两次Map-Reduce,第一次Map-Reduce统计基于Partition函数计算结果后每个block中实体数目的分布,第二次Map-Reduce再根据该分布再进行二次Partition,具体流程如下:
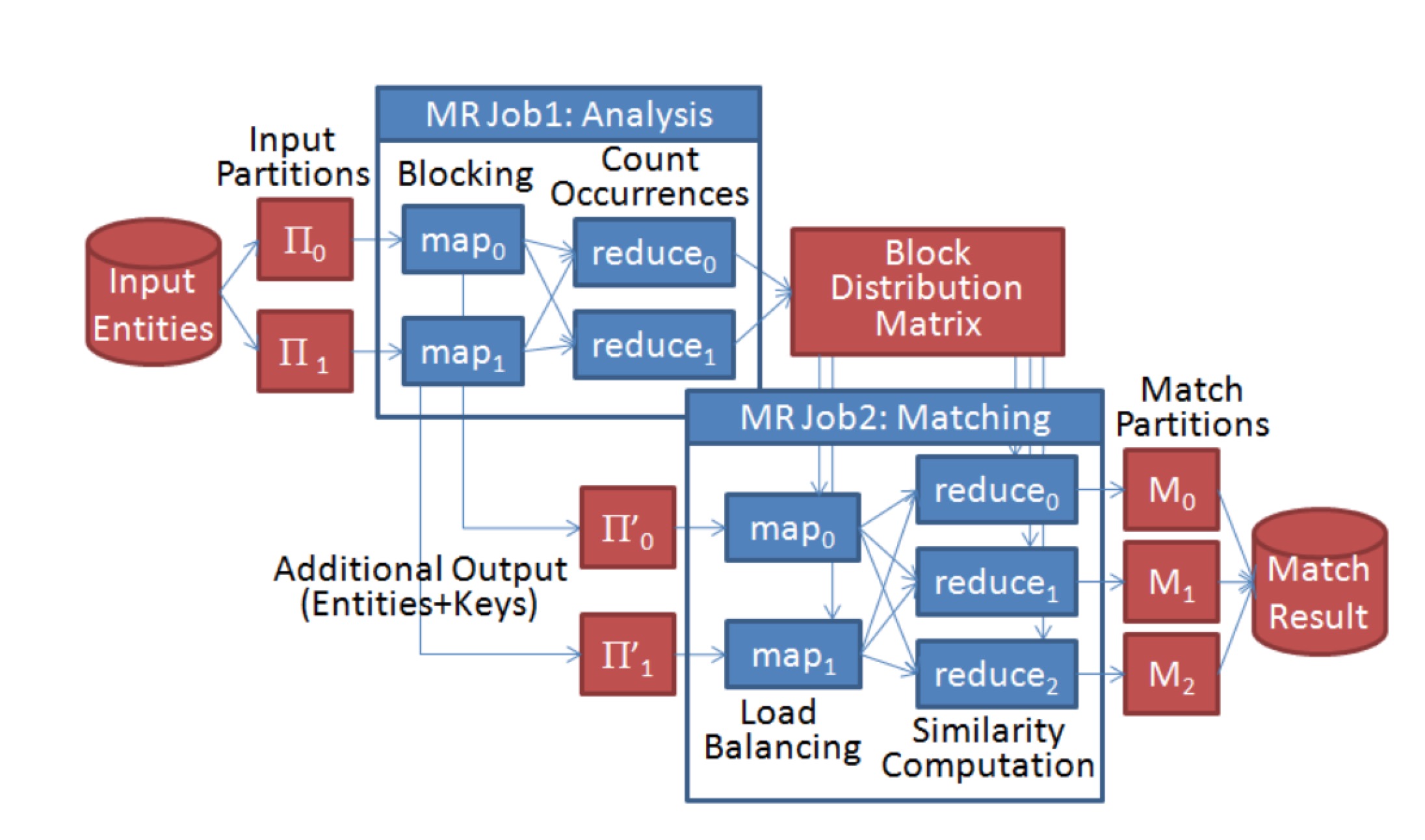
Reduce Stage
本阶段目标是对同一block内任意两个可能的实体对进行判断是否可以融合。根据不同的策略,分为Deterministic record linkage和Probabilistic record linkage。
Deterministic record linkage
Deterministic record linkage即基于规则的实体融合方法,在具体操作过程中,主要是根据一个或多个identifiers来判断是否进行融合,在特定领域内,基于规则的实体融合方法往往会得到不错的效果。
Probabilistic record linkage
Probabilistic record linkage即基于概率的实体融合方法,基本流程是先进行相似度的计算生成特征,再通过机器学习方法来进行判断。从组成模块上来看,主要分为训练模块和预测模块。
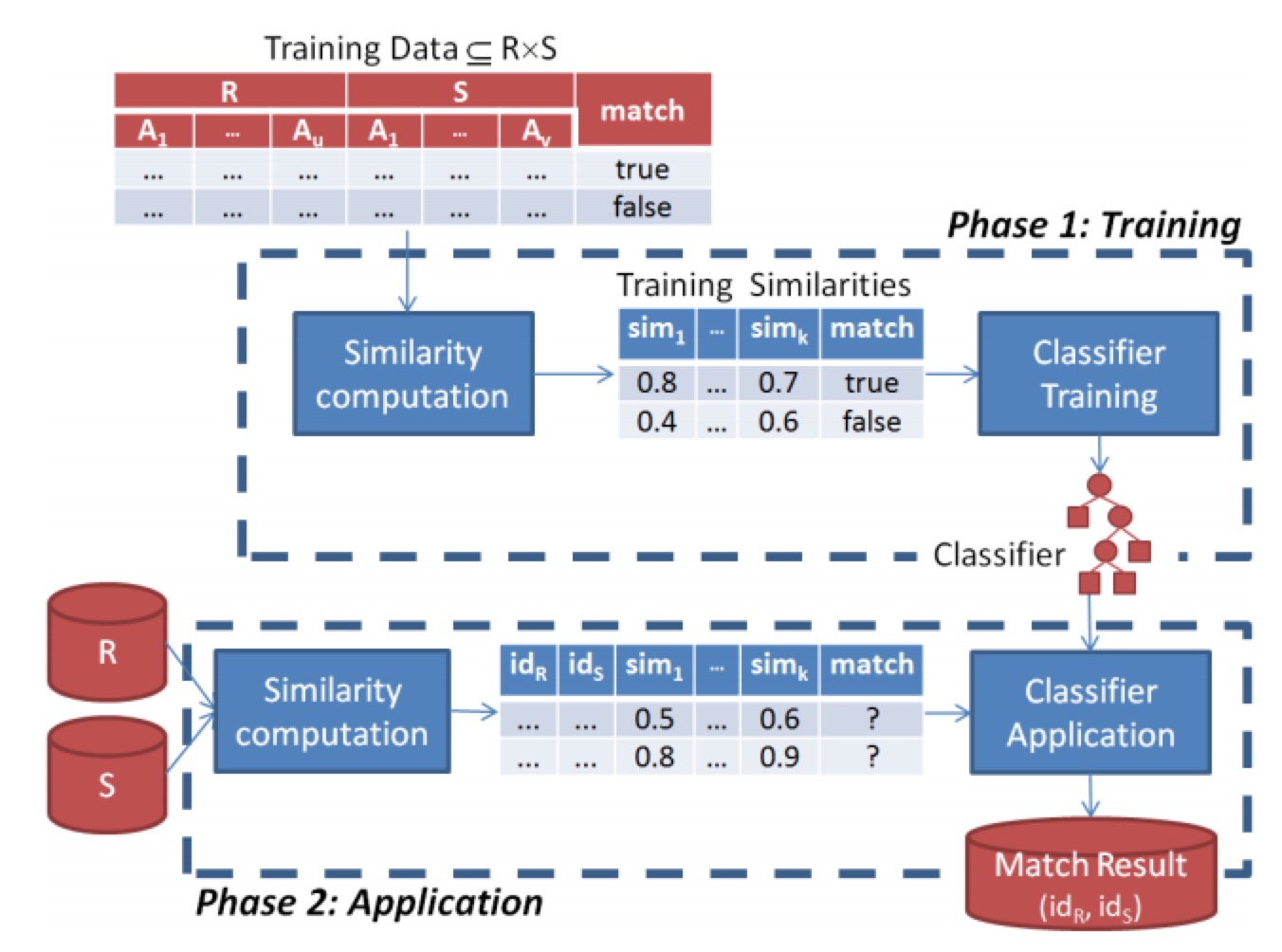
关于相似度计算,这个,这个,这个都有提到,比如基于布尔值的判断;编辑距离,Levenstein, Smith‐Waterman, Affine;基于set的相似度计算,Jaccard, Dice;基于vector的相似度计算,Cosine similarity, TFIDF;基于alignment的相似度计算,Jaro‐Winkler, Soft‐TFIDF, Monge‐Elkan;基于phonetic的相似度计算,Soundex;基于翻译模型的相似度计算;基于数值的相似度计算;领域特定相似度计算等等。而具体应用中,基于alignment的相似度适合处理名字缩写、别名,基于set、vector的相似度计算适合处理普通文本,如tweets等。
关于机器学习模型,常规的分类模型都可以使用,如朴素贝叶斯、svm、深度学习等等。在实际操作过程中,由于训练数据有限,一般会采用active learning的策略通过迭代的方式逐步提高模型的准确率。
Evaluation
整体评估指标主要还是F值以及整个算法的运行时间,具体而言值的关注的指标有:全量实体对的数目,经过Map之后需要匹配的实体对数目/召回率,最终匹配上的实体对数目/准确率/召回率,MapReduce中每一步的运行时间,整体运行时间。
Conclusion
关于实体融合的相关论文非常多,但到2012年之后基于新算法、新框架的论文逐渐变少,更多是survey、工程上性能优化。也就是说,学术界认为这个任务在一定程度上已经得到了解决。而从基本算法框架上来看,关于MapReduce算法框架的实体融合论文明显多于其他框架,在工程上甚至已经有了开源工具包如dedupe,大规模的实体融合也有相应的支持如dedoop。从技术壁垒来看,基本框架与具体算法看起来都比较简单,但当数据规模达到一定程度后,算法、工程上都会遇到瓶颈,如果在大规模数据下顺畅跑通整个流程,并得到质量足够高的知识图谱,本身就是壁垒,而在具体实现过程中,针对特定领域的融合算法优化也会是壁垒的一部分。另外,整个系统的很多子模块都是常见的机器学习问题,深度学习在整个系统中的想象空间也非常大。
References
维基百科链接,对该算法常见处理流程与算法有非常好的概述。
Dedupe, 基于Python的工具包,实现了包括fuzzy matching, deduplication, entity resolution在内的常见任务。主要处理流程是先对所有record通过Clustering/Blocking的方法进行分组,然后在组内部通过计算相似度特征和机器学习分类模型对任一一对record进行预测是否为同一实体。相关论文参考Paper。
Dedoop, 基于Hadoop的Deduplication实现,主要流程分为Blocking(对record进行分组),Similarity Computation(计算组内每一对实体的相似度),Match Classification(通过规则或机器学习算法来判断是否是同一实体)。有完善的User Interface以及高效的Map-Reduce实现机制。
http://iswc2015.semanticweb.org/sites/iswc2015.semanticweb.org/files/93660257.pdf
Effective Online Knowledge Graph Fusion,本文研究的方向是如何将搜索引擎返回结果中的实体卡片映射到维基百科上的实体。由于并非是传统意义上的两个知识库的融合,本文的思路还是走的Entity Linking的方法,即看维基百科中anchor text与实体一起出现的概率作为将卡片映射到实体的强度,并考虑了传统实体融合中用到的计算相似度的方法。同时对实体的属性名、属性值融合有比较清楚的描述。
Swoosh: a generic approach to entity resolution,斯坦福的实体融合框架,相关论文在这里。很不一样的一篇文章,其他文章主要都是在讲如何blocking/matching,输出的结果就是哪一些实体对是可以融合的。这篇文章将匹配函数和融合函数当作黑盒,主要是在讨论基于这两个函数如何能够通过更加好的算法生成新的实体库,而不仅仅输出实体对。
http://www.cs.utexas.edu/~ml/papers/marlin-dissertation-06.pdf
Learnable Similarity Functions and Their Application to Record Linkage and Clustering,Dedupe工具包就是根据这篇博士论文实现的。本文对常见的相似度算法edit distance,tf-idf等进行了详细描述,Blocking、Clustering、Matching等模块用到了svm、active learning等机器学习模型,在现在看来,一些模型选型应该有更多选择。
https://pdfs.semanticscholar.org/cf6c/8ce4ec5bbbae9be4b9076c41d49a8eaad7b3.pdf
Evaluation of entity resolution approaches on real-world match problems,本文针对不同的matching方法提出了一整套评估标准,包含match quality和runtime efficiency。并对常见的Non-learning match approaches和Learning-based match approaches进行了介绍。
Entity Resolution: Tutorial,本文对实体融合的常见技术进行整体梳理,包括数据预处理,相似度计算,pairwise匹配决策机器学习模型,active learning策略,常见的constraints以及应用方法,Clustering算法介绍,多种混合模型的尝试等。
https://pdfs.semanticscholar.org/990f/9aa328df4c3c6503d6b7815a1ea865b9bfd1.pdf
Learning-based Entity Resolution with MapReduce,本文的整体思路还是先Blocking再matching,但给出了一套基于MapReduce的详细算法流程及实现思路,分别明确了MapSide和ReduceSide具体策略。同时对Learning-based Entity Resolution的training stage和application stage,本文也给出了详细的架构设计。
Entity Resolution with Markov Logic,本文给出了基于Markov Logic的实体融合方法,大体思路是把已有的知识图谱作为强限制映射到图上,再通过图计算的方式对实体进行融合。
Load Balancing for MapReduce-based Entity Resolution,本文主要针对MapReduce中Blocking策略进行了详细分析,是大规模实体融合必须要了解的。简单的事情当数据到一定规模后也会出问题。
