注:该文最初发布在开放知识基金会中国博客, 如果你想了解更多,请关注官方微博
注意:本文是对开放知识基金会创始人 Dr. Rufus Pollock 的一系列「小数据」的文章进行翻译整理后编写而成,文中图示未注明的均来自原文,具体参考的原文列表如下:
1. Forget Big Data, Small Data is the Real Revolution http://blog.okfn.org/2013/04/22/forget-big-data-small-data-is-the-real-revolution/
2. What Do We Mean By Small Data http://blog.okfn.org/2013/04/26/what-do-we-mean-by-small-data/
3. Frictionless Data: making it radically easier to get stuff done with data http://blog.okfn.org/2013/04/24/frictionless-data-making-it-radically-easier-to-get-stuff-done-with-data/
4. Git (and Github) for Data http://blog.okfn.org/2013/07/02/git-and-github-for-data/
「大数据」v.s. 「小数据」[1]
「大数据」已然成为2013最火热的词,不论是不是身在技术圈,你或多或少都会听到「大数据」如何如何神奇,是解决医疗、交通、贫穷等等各种大小问题的关键。但事实上而言,关于大数据的讨论往往忽略了更为重要的一点:真正的机会其实根本不在所谓的「大数据」,而恰恰是在「小数据」。我们要意识到,这个时代需要的不是建立起一个个新的数据寡头来支配一切「大数据」,而是要重视去中心化的数据生态来使流动的「小数据」得以整合协作。
事实上,如果我们回顾一下计算机历史,所谓的「大数据」从不是我们感到陌生的事物。自计算机诞生起,我们就一直面临着数据量超越计算处理能力的挑战,而这一挑战目前却因为商业利益的需求被粉饰成一个全新的机遇。
与此同时,我们却没能意识到什么才是真正的革命性挑战:在这个数据日益丰富的时代,如何构建大型的、去中心化的系统来访问、存储以及处理数据。你可能会觉得这个描述和目前所宣传的「大数据」挑战并没有什么两样,但请注意这里我们并不是在谈论一个大型企业如何利用并行技术在大规模计算平台上处理数据。让我们真正兴奋的是,如何在这个数据时代去建设去中心化的系统使得更多的普通人能够在这个由丰富的「小数据」构成的数据生态中更有效地协同合作。
在未来的某一天,我们会发现谈论「大数据」是很可笑的,因为正如我们不会谈论「大型软件」一样,数据的尺寸大小并不是其价值之所在,真正的价值在于数据其本身是否能够为我们的问题提供解决的方案。
事实上,对于很多问题而言我们根本不需要所谓的「大数据」,「小数据」已经足以为我们提供足够的信息。比如说,我们本地的公交时刻表,政府的支出数据,家庭的用电量等等,这些其实都只算得上「小数据」。再想想平时我们常用的 Excel,它所能处理的数据也只是「小数据」。著名的 TED 演讲者 Hans Rosling 也仅是用「小数据」让我们通过世界人口变化来更好了解这个世界。
因此当我们去解决问题的时候,中心化的巨型「大数据」系统并非是我们所需,我们应当将一个大问题分解为子问题,从而使得不同的组织和个人得以参与进来用「小数据」去解决一个个子问题。

什么是小数据?[2]
上面说了很多,那究竟「小数据」是如何定义的?开放知识基金会认为「小数据指的是可以在单个机器(特别是高性能的笔记本与单个服务器)上就能操作的数据」。为什么我们要特别说笔记本呢?因为在这个数据极其丰富的时代,我们的数据不再是来自于一个单一的提供商,这就使得任何人得以方便地去从不同源取回数据,和其他人协同处理和使用数据。而这里很重要的一点便是,对于每一个参与者,数据都应当能被他们自己的电脑或笔记本来处理。
如果我们能再回顾下计算机的发展历史,我们会进一步意识到,数据的「小」和「大」从来都是相对的,所谓的「大数据」可能随着计算机技术的发展随时就变为明日的「小数据」。我们今时今日所面对的所谓「大数据」的机遇和我们过往面对的「微型计算机」的机遇,「互联网」的机遇都有一个共通点:随着技术的发展,所谓的「大」(比如大型计算机)都会变为「小」(比如微型计算机),但所有的革命性变化都来自「小」。
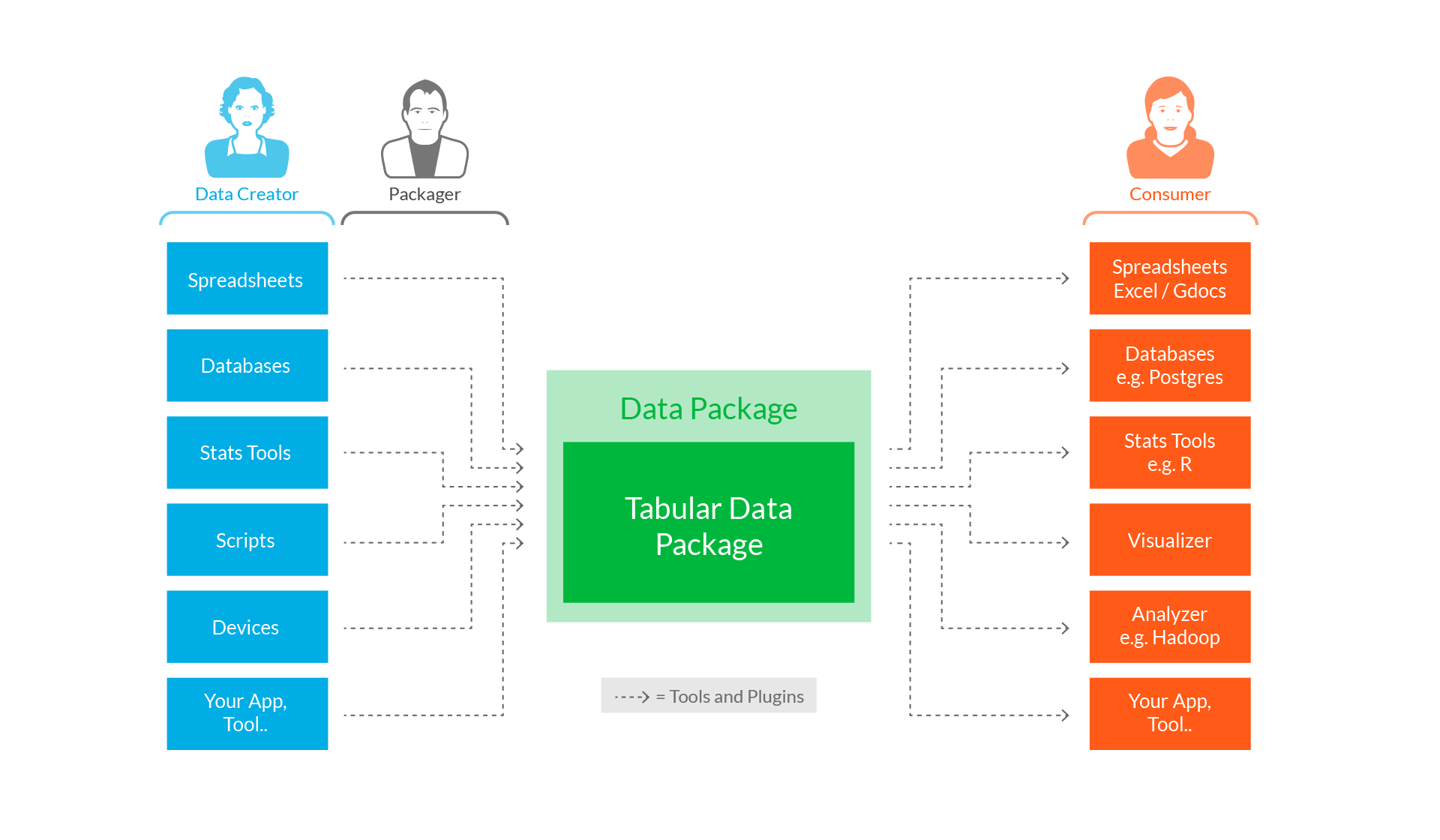
一个畅通无阻的数据世界 [3]
「小数据」的革命才刚刚开始。我们要意识到支持「小数据」有效协作的工作和基础平台都还未成熟。其中一个重要的问题在于,每当你想要开始一个新的数据项目时,你都要重新去网上搜寻相关的数据,重新清洗,重新打包,从而得以开始真正的分析和使用工作。
这样的体验实在是令人不能满意。让我们假象一下,如果我们做数据工作能像我们今时今日做菜一样该多好:你不用自己去农场种地或是饲养家禽,你只要去菜市场或超市便能买回所有需要的「材料」(数据)。这一切都得益于整个标准化的农业生态系统,那么如果我们有一套这样成熟的数据生态系统,岂不是很不错?当我们可以将注意力完全放在我们的数据分析和使用上,而不用担心数据的搜集和清洗,那么我们将能用数据创造更大的价值。
开放知识基金会在这一问题上设想建立起一套数据「物流」的标准:即类似于食材,我们需要有一整套系统的秤量、包装、运输的标准化流程和协议。而有了这样的标准后,
事实上建立这样一个「物流」标准,我们是有很大优势的,因为与真实世界的「物流」不同,数据从一台电脑传输到另一台电脑的成本是极其低廉的!这就意味着我们只需要关心如何将将数据从一个应用送进另一个应用的过程标准化以及简单化。开放知识基金会为此提出三个重要领域的工作:
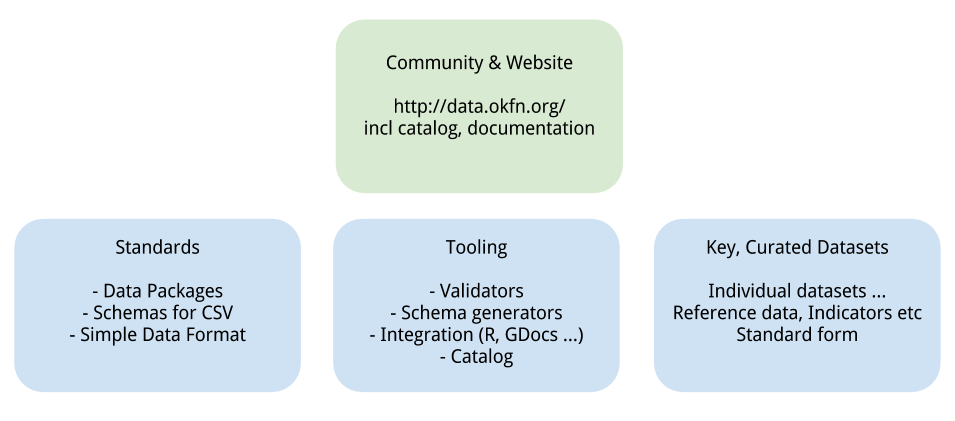
** 简单的数据标准 **
对于标准而言,我们提出了一个RFC形式的超轻量型数据标准:data package。它参考了大量的既有标准例如 JSON, 并遵循简单实用的设计理念。它被设计为对任意数据的最小化封装格式,并且具备可扩展性。更多的详情,可以阅读完整的标准文档。基于 data package,我们为表格型数据特别定制了 Simple Data Format 这一封装格式, 它使用一个基于 JSON 的 「JSON Table Schema」来描述表格数据的结构定义信息。更多信息,可以阅读它的完整文档。
** 简单的工具和整合 **
对于工具而言,我们制作了简单的 data package 生成器,验证器,显示器,从而你可以以此为开端,基于我们的 data package 来开发更多有意思的应用。 在开放知识基金会,我们也正在实验新一代的数据版本控制系统 dat (由 Max Ogden 正在开发)以及类似于 npm 的数据包管理工具 dpm。 如果你有兴趣,请参与进我们开放知识基金会实验室讨论与开发工作。
** 数据集的雪球效应 **
对于初始的数据集而言,我们过去已经收集了大量的参考性以及指标性数据,并将它们按照 data package 的规范进行封装,再存放在 GitHub 上 (github.com/datasets)。使用 GitHub 有着许多好处,首先我们能够对数据进行版本控制,对于每一项修改进行跟踪记录。其次,我们能够在 GitHub 上直接预览所有的 CSV 数据。最后, GitHub 最为天然的协作性平台让去中心化的数据项目协作更为容易。当然,我们也意识到我们仍旧需要一个统一的平台来展示我们以及社区中其他成员所发布的遵循 data pacakge 标准的数据。为此,我们搭建了 data.okfn.org 平台 (中国的朋友们,请访问中文版 datachina.heroku.com), 它作为一个轻量级的门户将分布在不同 GitHub 库中的 data package 索引后罗列在一处,但其本身并不存储任何数据,做到了去中心化。我们欢迎任何对数据感兴趣的朋友,向我们的平台继续建议好的数据,让好数据能更畅通无阻得流动。
