数据挖掘上课没怎么好好听,反而现在想自己多学一点了。最近发现Kaggle竞赛很有意思,但是自己基础太差了,所以定计划,每天看书30页左右,把自己感觉之前不知道的东西记录在这里。
第3章 探索数据
- 众数(mode):具有最高频率的值。
- 百分位数(percentile):第p个百分位数xp是一个x值,使得x的p%的观测值小于xp
- 截断均值(trimmed mean):丢弃高端和低端(p/2)%的数据,再计算均值。
- 极差(range):
=max(x)-min(x)) - 方差(variance):
=s_x2=\frac{1}{m-1}\sum_{i=1}{m}(x_i-\bar{x})^2) - 协方差矩阵(covariance matrix):两个属性的协方差是两个属性一起变化并依赖于变量大小的度量。
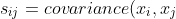 = \frac{1}{m-1}\sum_{k-1}^{m}(x_{ki}-\overline{x_i})(x_{kj}-\overline{x_j})) - 相关矩阵(correlation matrix):
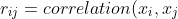 = \frac{covariance(x_i,x_j)}{s_is_j})
