序言
谈到统计学, 我们首先会想到的是一大堆的数据。其实对数据本身而言, 也是需要有上下文联系的数字来表示。比如,数字190本身不能代表什么, 但是我们说一个人身高190cm,我们就会说这个人好高啊。 结合数字的上下文联系和个人知识,我们就能够做出判断。 统计学就是收集,处理,分析,解释这些数据并从数据中得出结论的科学方法。
数据胜过传言
曾经民间流传长时间使用手机的人会因手机辐射而导致癌症的增加。对此国际上进行了跨13国迄今最大的调研(具体可见:http://interphone.iarc.fr/),收集数据并进行分析, 最终并未发现手机辐射会增加人体致癌机率。 但如果你在网络上看到父母在哭诉孩子因玩手机而患癌症,你会选择相信数据还是相信悲伤的父母呢?
事实上, 我们对于传言应该心存疑虑, 因为数据比传言更可靠。数据可以系统的描绘整个事件的面貌, 而不是只聚焦于某单一事件。
数据来源最重要
统计研究中, 最重要的就是数据来源。
小心潜在变量
如果有人说:“受到良好教育的人比没有受到教育的人能赚更多的钱”。 我想没有人会反对。 但仔细想想,这背后有没有更深层次的原因呢? 受教育程度高的人,平均来说父母受的教育程度也高, 也比较有钱。 他们能够在更好的环境中长大, 上更好的学校。 这些有利的条件让他们接受更多的教育。 即使他们不接受这么多教育, 这些有利的条件也会帮他们赚到更多的钱。
一个结论可能只涉及两个变量之间的关系, 并引导我们得出一个变量变化会引起另一个变量变化的结论。 这些信息是正确的, 但我们看到的相关性, 可能还可以由隐藏在背后的一些变量来解释。
变异性无处不在
人的体温平均在37度。 但如果你在一天中的不同时刻去测量体温, 你会得到不同的结果。 这就如同股市数据微小的波动并不产生实质性的变化。 所以当一些“专家”对每天股市变化进行分析, 你完全可以嗤之以鼻。
统计结论不是百分之百确定的
变化无处不在, 所以统计结论并不是绝对的。 吸烟容易得肺癌, 并不是说你抽烟就会得肺癌, 而是从统计数据来看, 吸烟得肺癌的概率比不抽烟人群的概率要大。
数据可反映社会价值
18年1月17日, 国家统计局发布2017年中国GDP数据,17年GDP同比增长6.9%。 这也充分说明了我国经济运行延续稳中向好的趋势。
第一部分: 数据的生产
第一章:数据从哪里来
学统计学, 我们需要知道统计学上一些基本的概念。
这是一门课结束后的成绩单:
image_1c5gi0pdpif4b615a2elcgu09.png-80kB
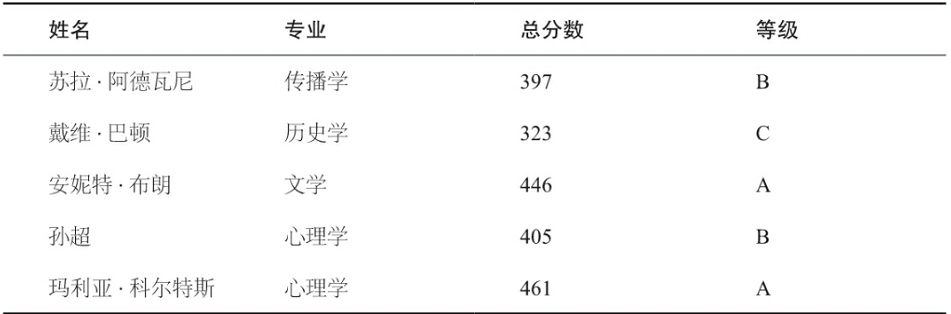
在这章表中, 个体就是各个学生, 而专业、总分数、 等级为其中的变量。 其中, 总分数用数字表示, 代表数值变量。 专业和等级都为类别变量。
选择变量时的错误判断, 可能导致在数据上浪费大量的时间和金钱却徒劳无获。
有句谚语说:“你不必吃完整头牛, 才知道肉老。” 这就是抽样调查。 即通过一部分获得全体的情况。 总体:就是那头牛身上有的肉,即我们想研究的所有目标对象。样本:牛身上的某些牛肉。即总体的一部分, 从样本中搜集信息, 以便对总体做出推断。
例如:在生活中, 我们要检验生产的一批灯泡的质量。 就需要使用抽样调查, 而不会说是对所有的灯泡一个个调查。
另一方面, 我们通过做某些实验来改变行为。 在实验中, 我们不只是观察个体或问问题, 而是刻意做了某些处理,以便观察其反应。
例如: 让一堆学生在看不到商标的情况下喝可口可乐和百事可乐, 观察哪种可乐更受欢迎。
在依靠数据信息推导出结论的过程中, 我们面临的第一个问题就是数据来自何处。统计研究结论的本质和有效性都取决于这一点。 数据来源于两个渠道:观察研究 和 实验。抽样调查就是一种观察研究。
第二章:好样本与坏样本
每年秋季,老家的乡亲把苹果装箱卖掉的时候,都要将最大最红的苹果放在最上面,因为这样做, 客户在抽取几箱进行检查的时候,会从箱中从最上面的苹果进行取样,从而对整体的苹果进行定价。
从一箱苹果的上层进行抽样, 所得的结果是有偏的, 即作为样本的苹果,质量要优于整体的苹果。
如果客户想要得到最公平的整体苹果的质量, 最好的方式应该是随机抽样,需要经过两个步骤:1. 贴标签,即把所有的苹果进行编号。 2. 软件。 通过电脑软件随机选择样本。 可以通过:www.randomizer.org 这个网址进行练习。
对于任何一个样本,我们要问的一个问题就是:样本是不是随机抽取的
第三章:样本可以告诉我们什么
在2004年,美国盖洛普公司调查2.2亿美国成年人支持宪法修正案通过的比例, 抽取了一个包含2527位成年人的样本, 这其中有1289人支持修正案, 支持率为51%, 我们能否说美国人民的对该修正案的支持率就为51%呢?
在讨论这个主题之前,必须先区分哪个数字是描述样本的, 哪个数字是描述总体的。
参数 是描述总体中提到的数字。即全美国人民对该修正案的支持率。
统计量 是描述样本的数字。 即值为51%。
如果盖洛普公司重新随机抽取了2527位成年人,样本统计量的值随之改变,为46%。 那么我们该相信哪个呢?
在这种情况下, 我们就需要对样本进行多次抽样。 而抽样样本的大小, 会决定样本变异性的大小。 这句话如何理解呢?
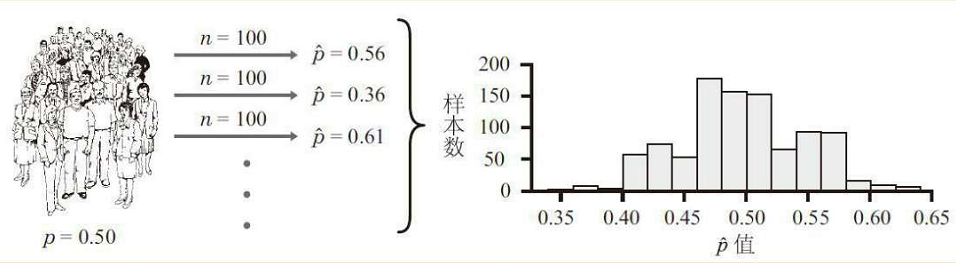
假设美国人民最终总体的支持率为50%,盖洛普公司每次只对100人进行访谈,总计抽样访谈了1000次,那么不同支持概率的次数如何分布呢?
从图中我们可以看到, 当样本大小为100时,支持概率的分布比较分散,次数最多的概率范围为40%-60%之间。
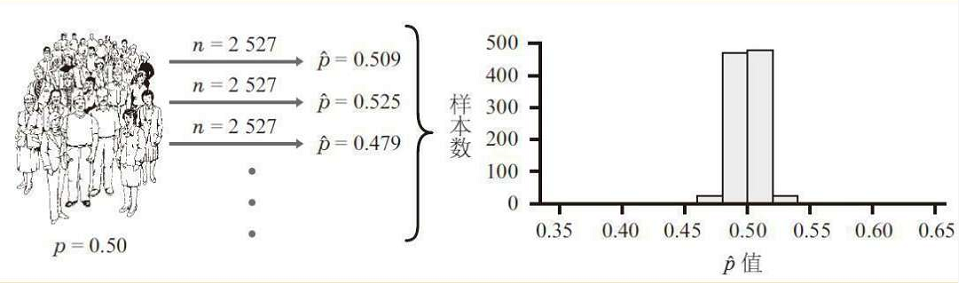
盖洛普公司每次对2527人进行访谈,总计抽样访谈了1000次,那么支持概率的分布又如何呢?
我们可以看到, 当样本大小为2527时,不同概率分布比较集中, 次数最多的概率范围为48%——52%之间。
【结论】:
- 大小为100人的概率分布比较分散。大小为2527人的概率分布比较集中。
- 大小为100人的1000个样本中,有95%的支持率分散在0.40——0.60之间。 大小为2527人的1000个样本中, 有95%的支持率分散在0.48——0.52之间。
- 大样本与准确值之间的差异在0.02之间,而小样本与准确值之间的差异在0.1之间,为大样本的5倍。 所以大样本统计量的变异性比小样本统计量的变异性小。
【注意】: 一个随机样本统计量的变异性,不受总体大小的影响,只要总体至少比样本大100倍。 并且样本统计量的变异性是由样本的大小决定。
现在,我们就清楚了两个概念:
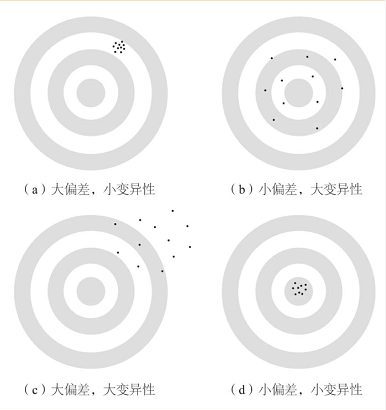
- 偏差:当我们取多个样本时, 它们的统计量朝一个方向偏离总体的参数值。
- 变异性: 当我们取多个样本时, 统计量值的离散程度。
我们可以用打靶来形象的表示:
差异与变异性.png-48.5kB
我们该如何减小偏差与变异性呢?
减小偏差: 用简单随机抽样的方法。
减小变异性: 用大点的样本。
当实际抽样调查的时候,我们不可能知道总体参数的真实值是多少(除非对总体的每个对象进行调查),因此我们只能从大的随机样本中得到估计值,因此就会存在误差范围。
误差速算法:当我们一个大小为n的简单随机样本的统计量来估计未知的总体参数,如果置信度为95%,那么误差大致为
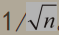
例如,在上面盖洛普的支持率调查中, 如果抽样人数为100, 误差概率为 1/10 = 0.1。 如果抽样人数为2527人, 误差概率为0.02。
(如果想要把误差范围缩小5倍,我们就需要将抽样人数扩大25倍)
置信度说明: 我们有95%的把握认为, 在所有成年人当中,有49%~53的人支持该修正案。
我们可以看到, 置信度说明包含两个部分:
- 误差范围: 样本统计量距离总体参数真实值有多远。
- 置信度: 所有样本统计量中, 满足该误差范围的样本统计量的百分比。 用置信度来表达对一个样本的结果有多大的信心。
第四章:真实世界中的抽样调查
在今天,我手机短信接到一条评分问卷,内容如下:【滴滴出行】尊敬的滴滴用户, 诚邀您参加用户调查, 以便于我们改进服务,请点击https://dc.tt/BKR9Ld6gg;点击后显示内容为——您有多大可能性推荐朋友/同事使用滴滴快车?(0-10评分,0分绝对不会推荐;10分肯定会推荐) ;
image_1c5k9i2fnamtgsfb9tc6c1j0pc.png-29.2kB
我们假设滴滴随机发送了20000条短信,最终收到了1000份评分问卷,那么滴滴是否就能认为这1000份评分问卷成绩就绝对代表了用户对滴滴的评分成绩呢?
答案当然是不能。因为在现实生活中的抽样调查,会存在很多的误差。
第一就是随机抽样误差,因为抽样调查本身不能全面涵盖所有总体,我们可以通过选择随机样本的大小,来控制随机抽样误差。
第二就是使用了糟糕的抽样方法, 比如:假设滴滴对打车体验进行调查,采取自愿回应的措施
第三就是样本会对总体内容涵盖不全, 比如滴滴进行短信调查,就会漏掉从来不看短信的人群。
第四就是非抽样误差,比如用户看到滴滴公司发的评分短信,但不对其作出回应。 无回应的偏差很容易超过误差范围所描述的随机抽样误差。
第五就是问题的措辞, 比如滴滴在这次调查中问的问题是:你有多大的可能性给朋友推荐滴滴打车 而 不是 你给滴滴打车评多少分。 我相信这两个问题的答案一定差别很大。
有诱惑倾向的问题需要避免,比如:你是否赞同禁止私人拥有枪支以降低犯罪率。
滴滴公司该如何应对调查中无回应人群的问题?
一种方法是, 用相似的用户来进行代替。 另一种方法是,当数据收集完成, 用统计方法给有回应的数据进行加权
在现实生活中的抽样调查,我们常常需要将样本进行分层处理, 进行分层抽样需要两步:1. 将抽样框架中的个体先分成若干层。 2.针对各层取随机样本, 组合起来就是我们要的总样本。 那么,分层抽样有什么优点和缺点呢,我们通过一个案例来分析:
例如:工程大学有20000名学生,其中研究生2000人。我们抽取500名学生进行调查。
如果从全校同学中随机抽取,那么每个人被抽取的概率为 500 / 20000,即20分之一。在抽取的500人中, 大约有50名为研究生。
大小为50的样本不能反映整体的研究生意见,我们选择一个研究生为200人,本科生为300人的分层样本。
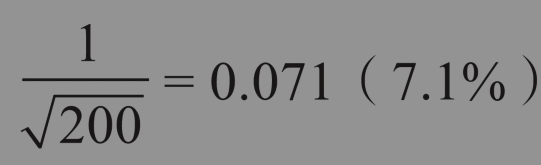
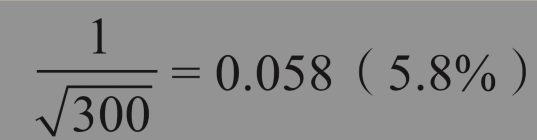
分层样本刻意加重了研究生的比例, 得出的结论还必须做出调整, 才能得到所有学生意见的无偏估计。
在现实生活中,我们要得到精确而有效的抽样调查,就需要调查者使用好的统计技术,并认真准备抽样框架,注意问题的措辞,减少无回应率。同理,当你在相信一些调查结果之前,应该先问以下问题:
- 这个调查是谁做的
- 调查的总体是什么
- 样本是如何选取的
- 样本有多大
- 回应率是多少
- 用什么方式联络的受访者
- 调查是什么时候做的
- 调查问题的措辞如何
