实验步骤:
1.获得数据:实验只用了1000个数据,另外在celebA数据集上多加了两个标签(有无左耳/右耳)
2.生成训练和测试用的 tfrecords 文件
3.定义网络结构 (这里用的是类似于 mobilenetv2 的网络结构)
3.softmax多标签分类
PART 1
mobilenetv2:将普通卷积操作因式分解为一个深度卷积(depthwise conv)和逐点卷积(pointwise conv),深度卷积只与输入的每一个channel作卷积,逐点卷积负责将深度卷积按通道融合。

bottleneck res_block
卷积操作后进行Relu变换会丢失很多信息,可以先把特征映射到高维空间(上图中t为expand rate)再Relu,就不会丢失太多有用的信息。
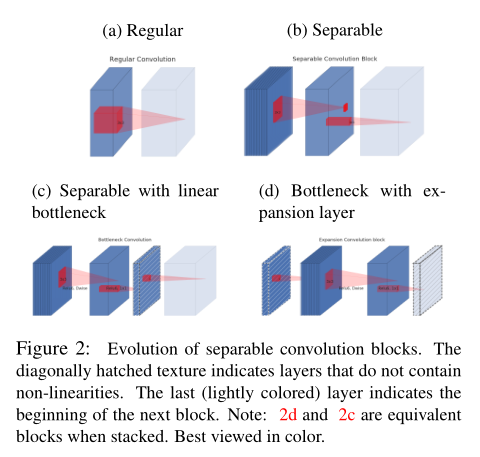
几种卷积操作的比较
实验中用的网络结构:

网络结构
PART 2
sigmoid 函数用于多标签分类时:
把每一个元素映射到 [0,1] 之间,每个标签独立,但不互斥。
logits = mobilenetv2(x, num_class, is_train) # num_class=42
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=y_))
softmax 函数用于多标签分类时:
计算每个元素的概率,每个元素的概率之和为1,要求每个标签互斥。
logits = mobilenetv2(x, num_class, is_train) # num_class=80
pre = tf.reshape(logits, [-1, 84, 2])
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pre, labels=y_))

两种交叉熵损失函数的比较
PART 3
实验只用了1000个数据,另外在celebA数据集上多加了两个标签(有无左耳/右耳),其中900个用于训练,100个用作验证,迭代2001次,训练准确率接近百分之百,应该是过拟合了吗哈哈哈哈,我在验证集上的精度也有百分之九十九~
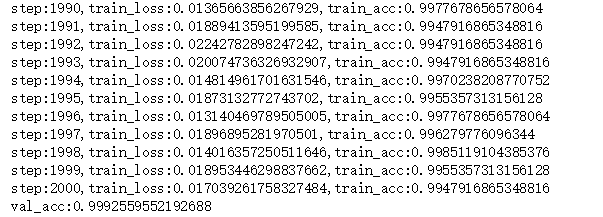
验证精度

准确率

损失函数
