Hystrix使用学习
1. 雪崩效应
一个用户请求处理依赖多个服务,如一个用户请求依赖了服务A,P,H,I,正常情况下均能正常访问并返回
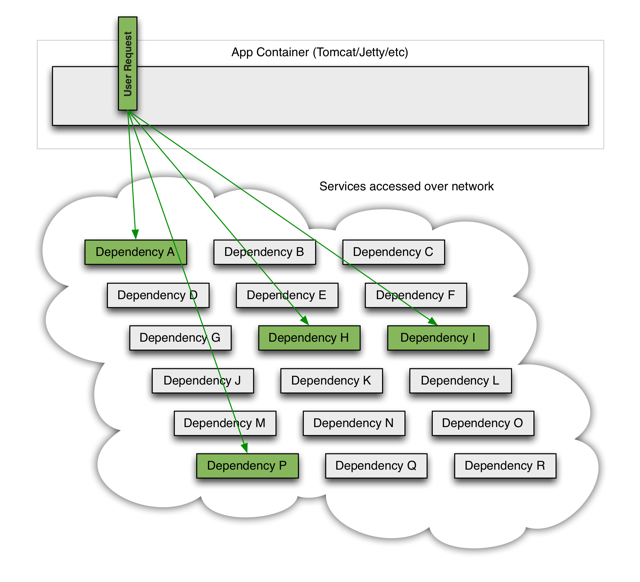
当其中一个服务(服务I)出现了问题,比如超时,异常,阻塞等,用户请求会被阻塞
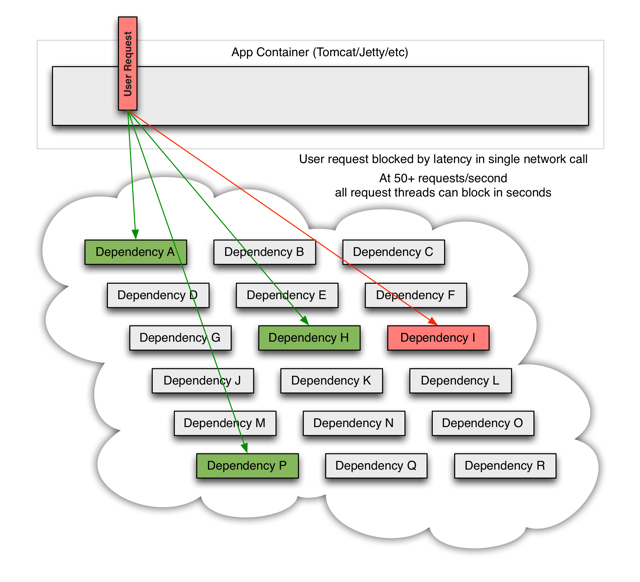
被阻塞的用户请求将会消耗系统的线程,IO等资源,当该类请求越来越多,占用的计算机资源越来越多的时候,会导致系统瓶颈出现,造成其他的请求同样不可用,最终导致业务系统崩溃,又称为雪崩。
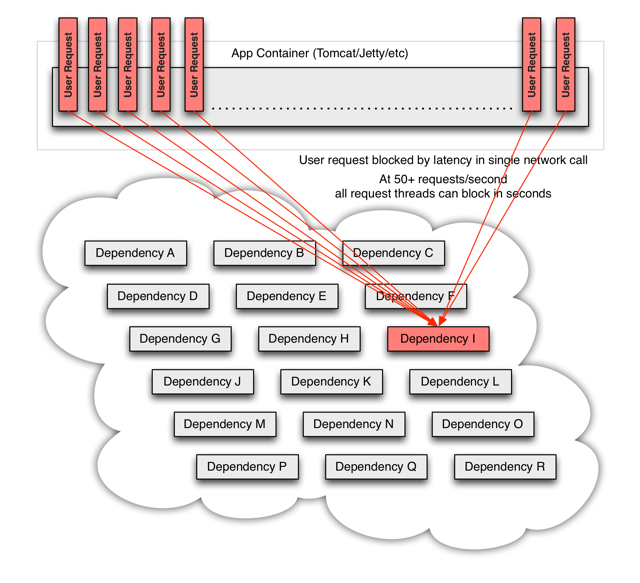
如果多个用户的请求中,都存在无法访问的服务,那么他们都将陷入阻塞的状态中。图中都是一个用户请求依赖多个服务,而多个服务中的一个服务出现了问题拖垮了整个系统。
造成雪崩的原因:
1.硬件故障
2.负载过大
3.代码有问题
Hystrix就是为了解决上述问题。
Hystrix提供了熔断模式和隔离模式来解决或者缓解雪崩效应。
这两种方案都属于阻塞发生之后的应对策略,而非预防性策略(例如限流模式)。
Hystrix是在服务访问失败时降低阻塞的影响范围,避免整个服务被拖垮。
Hystrix能做什么:
1. 对通过第三方客户端库访问(通常通过网络)的依赖关系提供保护并控制延迟和故障。
2. 停止复杂分布式系统中的级联故障。
3. 快速故障,快速恢复。
4. 回退,尽可能优雅地降级。
5. 启用近实时监控,警报和操作控制。
2. 隔离
hystrix依赖的隔离架构图
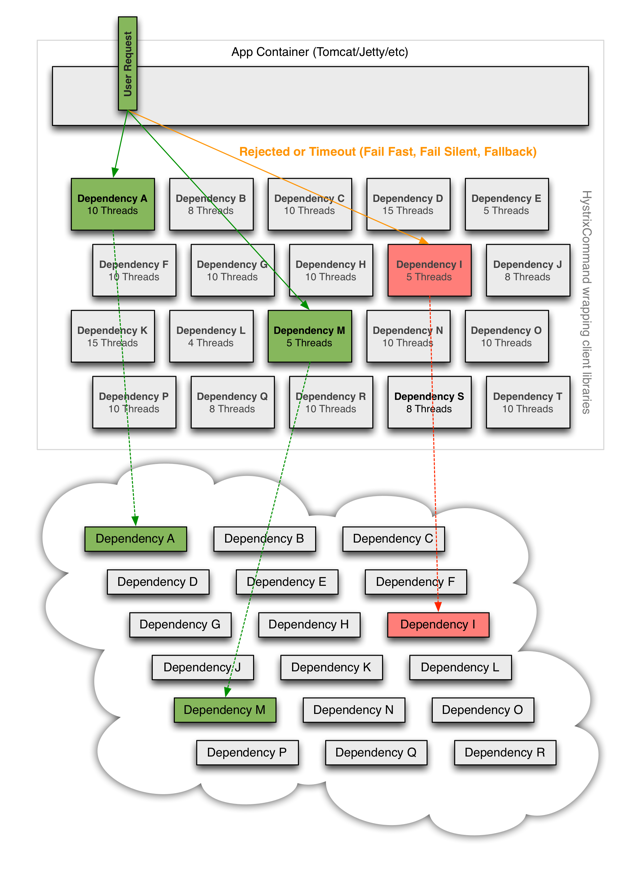
Hystrix在用户请求和服务之间加入了线程池。
Hystrix为每个依赖调用分配一个小的线程池,如果线程池已满调用将被立即拒绝,默认不采用排队,加速失败判定时间。线程数是可以被设定的。
原理:
用户的请求将不再直接访问服务,而是通过线程池中的空闲线程来访问服务,如果线程池已满,则会进行降级处理,用户的请求不会被阻塞,至少可以看到一个执行结果(例如返回友好的提示信息),而不是无休止的等待或者看到系统崩溃。
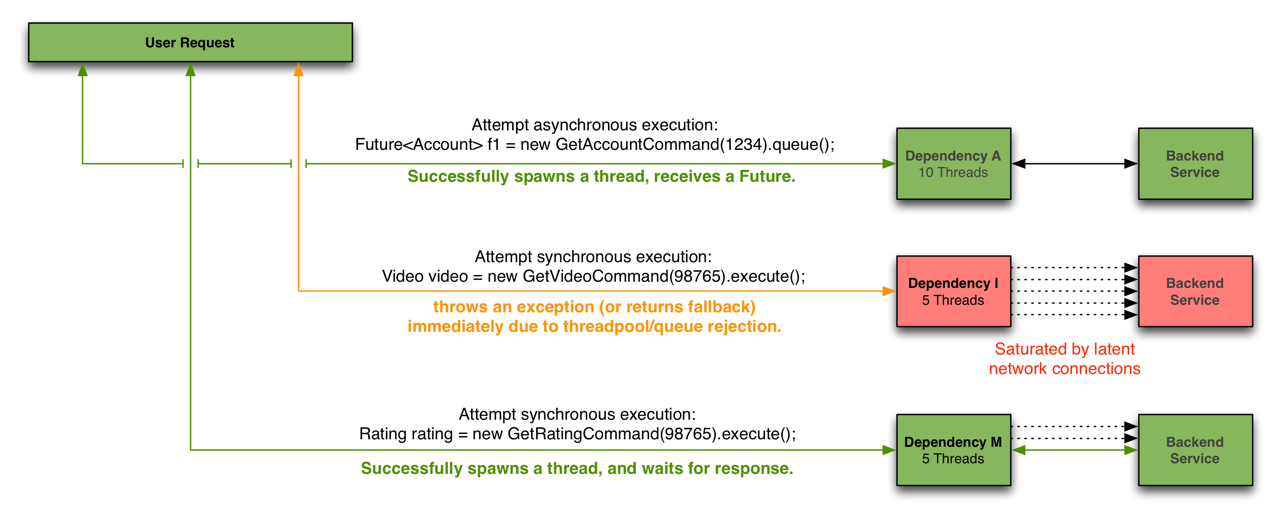
其本质是将服务视为资源**,当请求该资源的数量超过了线程池中的数量限制时则不可以再对该资源进行访问,从而保护该资源不会过载而造成阻塞。
3. 熔断
3.1 熔断模式
该模式借鉴了电路熔断的理念,如果一条线路电压过高,保险丝会熔断,防止火灾。
如果某个目标服务调用慢或者有大量超时,此时,熔断该服务的调用,对于后续调用请求,不在继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用。
3.2 熔断器
熔断器是位于线程池之前的组件。
用户请求某一服务之后,Hystrix会先经过熔断器,此时如果熔断器的状态是打开(跳起),则说明已经熔断,这时将直接进行降级处理,不会继续将请求发到线程池。熔断器相当于在线程池之前的一层屏障。
熔断器的工作原理:
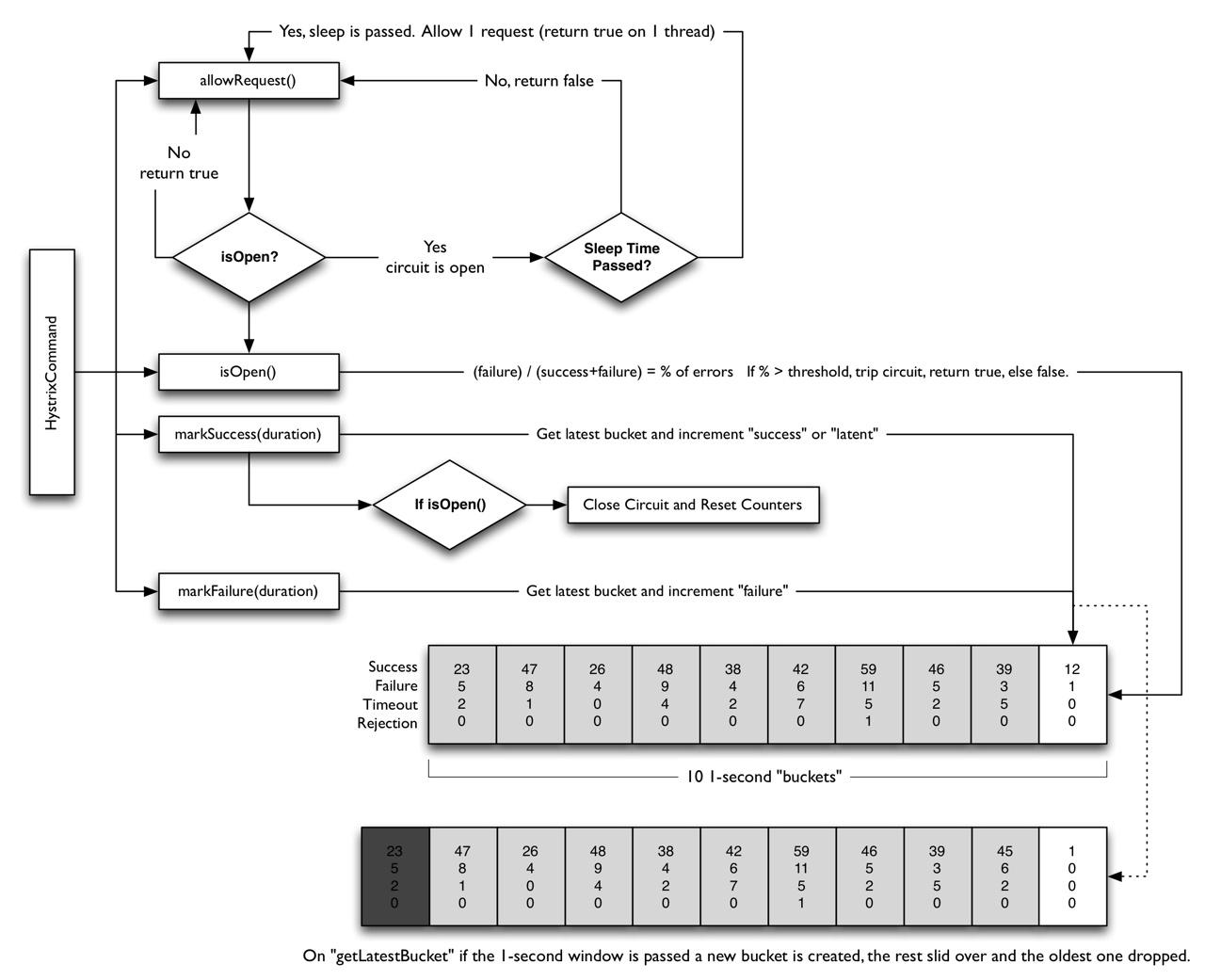
每个熔断器默认维护10个bucket;每秒创建一个bucket;每个blucket记录成功,失败,超时,拒绝的次数;
当有新的bucket被创建时,最旧的bucket会被抛弃
3.3熔断算法
判断是否进行熔断的依据是:
根据bucket中记录的次数,计算错误率。
计算算法:(failure)/(success+failure)=% of errors if %>threshold,trip circuit, return true, else false
3.4熔断恢复
对于被熔断的请求,并不是永久被切断,而是被暂停一段时间之后,允许部分请求通过,若请求都是健康的,则对请求健康恢复(取消熔断),如果不是健康的,则继续熔断。
服务调用的各种结果(成功,异常,超时,拒绝),都会上报给熔断器,计入bucket参与计算
4流程

说明:
- 每次调用创建一个新的HystrixCommand,把依赖调用封装在run()方法中
- 执行execute()/queue做同步或异步调用
- 请求接收后,会先看是否存在缓存数据,如果存在,则不会继续请求服务,直接返回缓存数据。如果不存在缓存数据,则继续进行第4步。
- 将判断熔断器是否为开启状态,如果开启(已经熔断),则调用第8步FallBack(降级)处理。如果未开启,则继续调用第5步。
- 检测当前依赖的线程池是否已满,如果已满,也会调用第8步FallBack(降级)处理,同时进行第7步将结果上报给熔断器,此时上报的状态为【拒绝】。如果未满,则继续进行第6步。
- 执行的是run方法。run方法执行过程中如果发生HystrixBadRequestException以外的异常,也将调用第8步FallBack(降级)处理,同时进行第7步将结果上报给熔断器,此时上报的状态为【失败】。如果run方法执行没有异常但是超过预设的时限也将调用第8步FallBack(降级)处理,同时进行第7步将结果上报给熔断器,此时上报的状态为【超时】。
如果没有异常也未超时,则进行第9步返回结果,同时进行第7步将结果上报给熔断器,此时上报的状态为【成功】。
在第8步的降级处理中,如果没有实现getFallback的将直接抛出异常,如果降级逻辑调用,成功直接返回
,如果降级逻辑调用,失败抛出异常。
执行过程中位于熔断器之后的处理,都会将结果上报给熔断器,熔断器根据结果计算是否进行熔断。
当服务无法正常访问时,就会进行降级处理,调用fallBack降级策略:

共有5种情况会触发降级处理:
1.run()方法抛出非HystrixBadRequestException异常。
2.run()方法调用超时。
3.熔断器开启。
4.线程池已满。
5.显示调用fallback逻辑(用于特殊业务处理)
当阻塞发生时(异常,超时等),由于采用了服务降级的处理,可以保证访问可以继续进行。
5 参数设置
| 参数 | 作用 | 备注 |
|---|---|---|
| maxQueueSize | 请求等待队列 | 默认值:-1,如果使用正数,队列将从SynchronizeQueue改为LinkedBlockingQueue |
| groupKey | 表示所属的group,一个group共用线程池 | 默认值:getClass().getSimpleName() |
| fallback.isolation.semaphore.maxConcurrentRequests | fallback最大并发度 | 默认值:10 |
| execution.timeout.enabled | 是否打开超时 | |
| execution.isolation.thread.timeoutInMilliseconds | 超时时间 | 默认值:1000;</br>在THREAD模式下,达到超时时间,可以中断;</br>在SEMAPHORE模式下,会等待执行完成后,再去判断是否超时.</br>设置标准:</br>有retry,99meantime+avg meantime; 没有retry,99.5meantime |
| execution.isolation.thread.interruptOnTimeout | 是否打开超时线程中断 | THREAD模式有效 |
| execution.isolation.strategy | 隔离策略,有THREAD和SEMAPHORE | 默认使用THREAD模式,以下几种可以使用SEMAPHORE模式:1.只想控制并发度;</br> 2.外部的方法已经做了线程隔离; </br>3.调用的是本地方法或者可靠度非常高、耗时特别小的方法(如medis)</br> |
| execution.isolation.semaphore.maxConcurrentRequests | 信号量最大并发度 | SEMAPHORE模式有效,默认值:10 |
| coreSize | 线程池coreSize | 默认值:10</br>设置标准:qps*99meantime+breathing room |
| commandKey | 默认值:当前执行方法名 | |
| circuitBreaker.sleepWindowInMilliseconds | 熔断多少秒后去尝试请求 | 默认值:5000 |
| circuitBreaker.requestVolumeThreshold | 熔断触发的最小个数/10s | 默认值:20 |
| circuitBreaker.forceClosed | 是否强制关闭熔断 | 如果是强依赖,应该设置为true |
| circuitBreaker.errorThresholdPercentage | 失败率达到多少百分比后熔断 | 默认值:50</br>主要根据依赖重要性进行调整 |
参考学习:
Hystrix wiki
Hystrix 分析与使用
