引言
风险比赛的说明见:
https://dc.cloud.alipay.com/index#/topic/intro?id=9
code:https://github.com/Frank2015a/machine_learning_practice/blob/master/10_atec_risk/atec_EDA_v1.0.ipynb
数据预处理需要解决的问题:
- 原始数据中存在大量Null值影响建模分析,
- 特征的数据分布随着时间变化,造成了train与test的结果非常不一致
数据基本描述
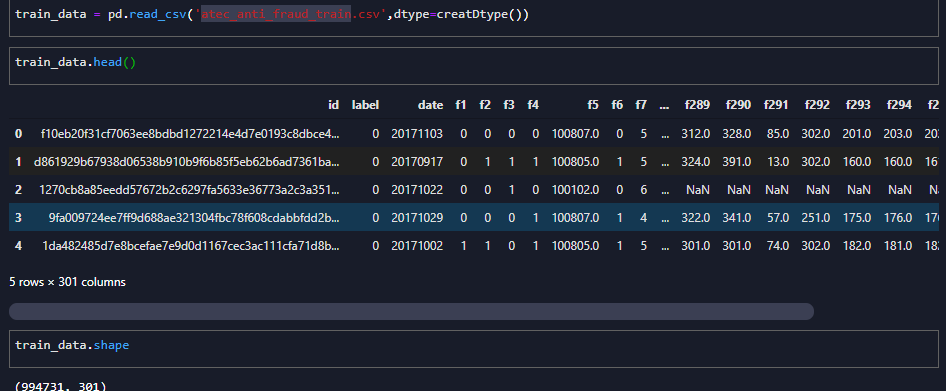
train_data = pd.read_csv('atec_anti_fraud_train.csv',dtype=creatDtype())
test_data = pd.read_csv('atec_anti_fraud_test_b.csv',dtype=creatDtype())
print(sorted(train_data['date'].unique()))
print(sorted(test_data['date'].unique()))
原始数据如:
- 99w+行,297列特征
- 训练集和测试集时间跨度不同:
- 训练集date:20170905~20171105
- 测试集date:20180206~20180306
数据缺失率分析
策略:
- 查找出训练集和测试集中null列(缺失率大于0.3的特征),去除;
- 缺失率小于0.3的列保留,通过控制填充的方式处理(lgb可以自动处理缺失值)
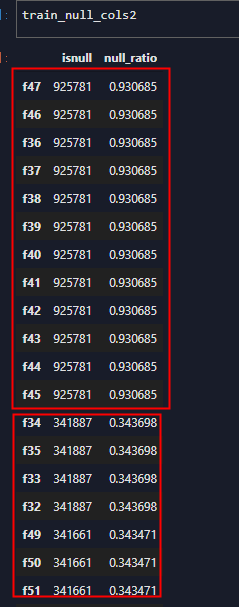
def get_col_null_rate(df, thres = 0.3):
# 计算输入的df中各col null的比例
# input -- df of data
# output -- df index and null rate
info = pd.DataFrame()
info['isnull'] = df.isnull().sum()
info['null_ratio'] = info['isnull'] / df.shape[0]
info = info.sort_values(by = 'null_ratio', ascending=False)
info = info[info['null_ratio'] > thres]
return info
# 分别统计训练和测试集的特征缺失率,阈值0.3
train_null_cols = get_col_null_rate(train_data, thres=0.3)
train_null_cols = list(train_null_cols.index)
test_null_cols = get_col_null_rate(test_data, thres=0.3)
test_null_cols = list(test_null_cols.index)
# output
train set null rate>0.3 cols: 30
test set null rate>0.3 cols: 127
输出结果,训练集30个null列,测试集127个null列,且训练集null列都在测试集null中。需要清除的null列:
['f100', 'f101', 'f102', 'f103', 'f104', 'f105', 'f106', 'f107', 'f108', 'f109', 'f110', 'f111', 'f112', 'f113', 'f114', 'f115', 'f116', 'f117', 'f118', 'f119', 'f120', 'f121', 'f122', 'f123', 'f124', 'f125', 'f126', 'f127', 'f128', 'f129', 'f130', 'f131', 'f132', 'f133', 'f134', 'f135', 'f136', 'f137', 'f138', 'f139', 'f140', 'f141', 'f142', 'f143', 'f144', 'f145', 'f146', 'f147', 'f148', 'f149', 'f150', 'f151', 'f152', 'f153', 'f154', 'f155', 'f156', 'f157', 'f158', 'f159', 'f160', 'f32', 'f33', 'f34', 'f35', 'f36', 'f37', 'f38', 'f39', 'f40', 'f41', 'f42', 'f43', 'f44', 'f45', 'f46', 'f47', 'f48', 'f49', 'f50', 'f51', 'f54', 'f55', 'f56', 'f57', 'f58', 'f59', 'f60', 'f61', 'f62', 'f63', 'f64', 'f65', 'f66', 'f67', 'f68', 'f69', 'f70', 'f71', 'f72', 'f73', 'f74', 'f75', 'f76', 'f77', 'f78', 'f79', 'f80', 'f81', 'f82', 'f83', 'f84', 'f85', 'f86', 'f87', 'f88', 'f89', 'f90', 'f91', 'f92', 'f93', 'f94', 'f95', 'f96', 'f97', 'f98', 'f99']
以前只注意处理训练集null 列,没有单独处理测试集null列,是不合适的。
从null比例的分布可以看出,null列之间是相互关联的,很多列的null比例相同,可能的原因是这些feature都是通过同样的表连接查询取得的。
数据分布稳定性分析
分析方法
对于所有的特征,分别绘制出dbeug图:
- 每day的null比例随着时间的变化
- 每day数值均值随着时间的变化
# merge 训练集和测试集,一起观察
data = train_data.append(test_data)
def draw_feature_debug(p):
# p = 'f24'
# 计算一个fe 在每天的数据缺失率
miss_rate = pd.DataFrame(data.groupby('ndays')[p].apply(lambda x: sum(pd.isnull(x))) / data.groupby('ndays')['ndays'].count()).reset_index()
miss_rate.columns = ['ndays', p]
# 一个fe在每天的分组
value_dist = pd.DataFrame(data.groupby('ndays')[p].mean()).reset_index()
plt.figure(figsize=(10,4),dpi=98)
p1 = plt.subplot(121)
p2 = plt.subplot(122)
# 特征缺失率的变化
p1.plot(miss_rate['ndays'], miss_rate[p])
p1.axvline(61, color='r')
p1.axvline(153, color='r')
p1.axhline(0.5, color='y')
p1.axis([0, 200, 0, 1])
p1.set_xlabel('ndays')
p1.set_ylabel('miss_rate_' + p)
p1.set_title('miss_rate_' + p)
# 特征数值的变化
p2.plot(value_dist['ndays'], value_dist[p])
p2.axvline(61, color='r')
p2.axvline(153, color='r')
p2.axhline(1, color='y')
p2.set_xlabel('ndays')
p2.set_ylabel('mean_of_' + p)
p2.set_title('distribution of ' + p)
plt.savefig('./debug/{}.jpg'.format(p))
# plt.show()
plt.close()
draw_feature_debug('f24')
# 绘制所有特征debug图
fe_all = [fe for fe in data.columns if 'f' in fe]
with Pool(32) as p:
list(tqdm(p.imap(draw_feature_debug, fe_all), total=len(fe_all)))
典型的debug图如:
- 0-62天的数据为训练集,150天以后的数据为测试集
- 左图为缺失率, 黄线为缺失率0.5
- 右图为数据分布,黄线为绝对值1
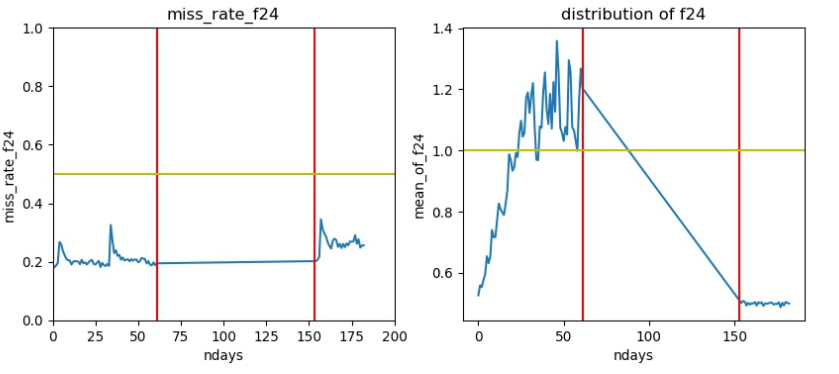
所有特征的分布分析
缺失率和分布正常的特征
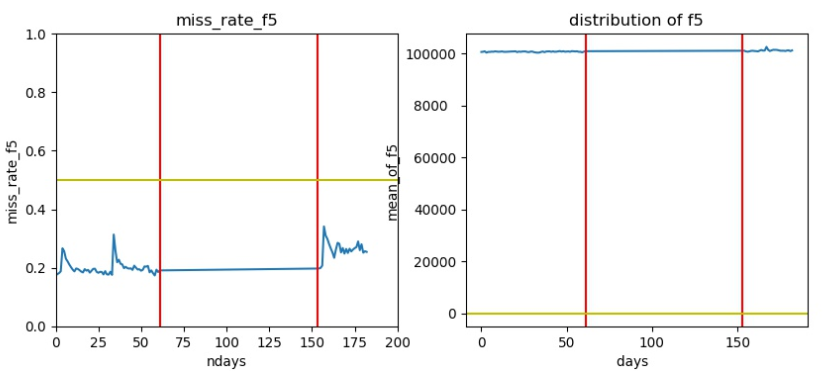
高null值数据
-
测试集null比例大于训练集
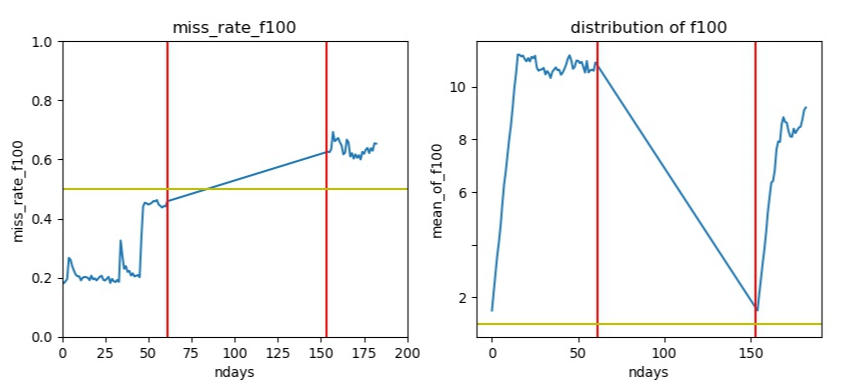 image_1d5jb1v8f1dlu17lo1dal16ku1le71g.png-108.7kB
image_1d5jb1v8f1dlu17lo1dal16ku1le71g.png-108.7kB -
几乎全部null的特征
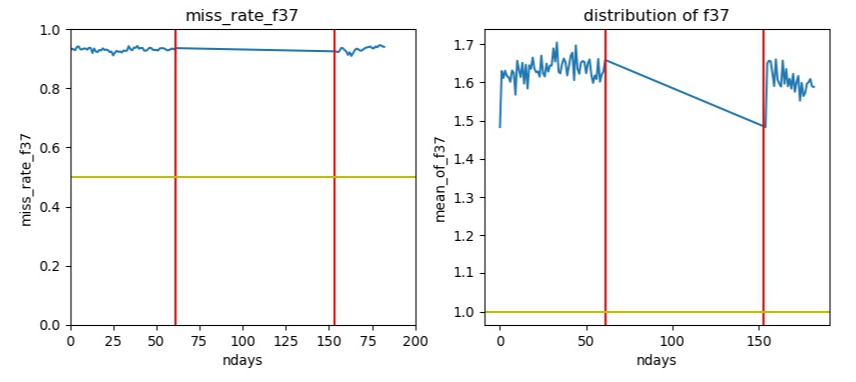 image_1d5jb306bptr1o6bv1h76q7v1t.png-93.3kB
image_1d5jb306bptr1o6bv1h76q7v1t.png-93.3kB
训练集测试集分布完全不同
- 在测试集中取值均在1以下。
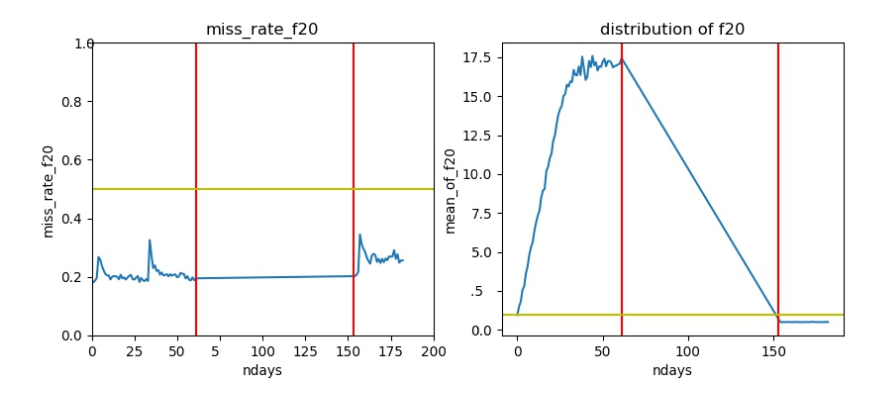
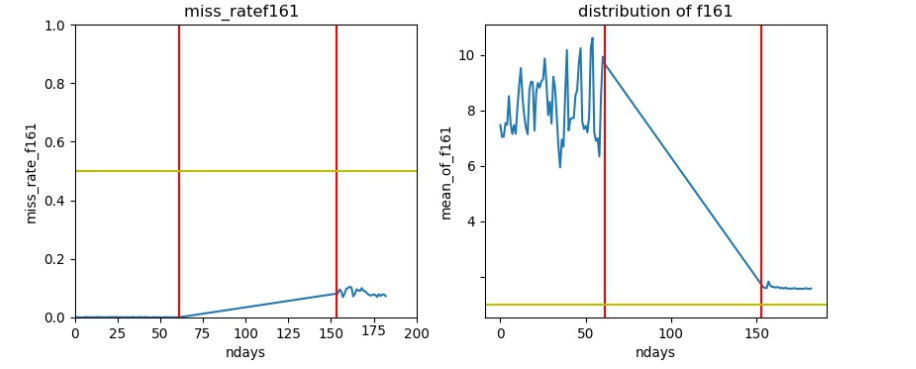
-
分布的区间完全不一致
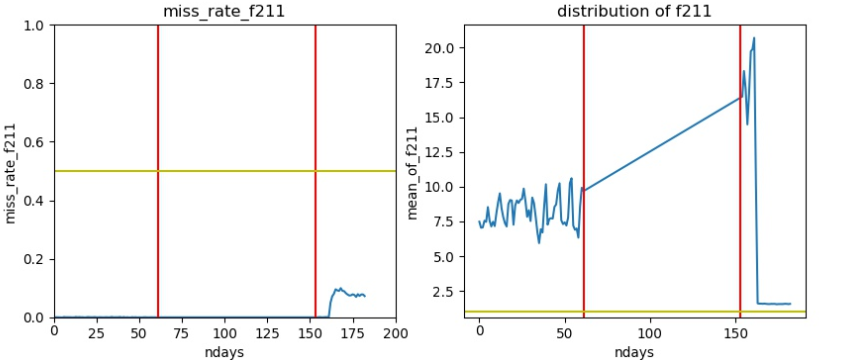 image_1d5jbe88t1hd215vf1m8h58qq7441.png-93.6kB
image_1d5jbe88t1hd215vf1m8h58qq7441.png-93.6kB
综合得到要去除的特征
fe_del = list(null_all_cols)
fe_del += ['f' + str(fe) for fe in range(20,28)]
fe_del += ['f' + str(fe) for fe in range(161,165)]
fe_del += ['f' + str(fe) for fe in range(211,234)]
print('fes to remove {} '.format(len(fe_del)))
# fes to remove 162
总结
综上,要去除的fe总数为162个。
分析和思考:
- 为什么会出现null
- 表的联合查询中,某些信息缺失造成了批量的null列
- 随着时间的推移,某些数据的意义变化,不再收集?
- 为什么特征会时变:
- 某些特征,可能与四季周期有关系,例如耍手机的频率,冬天动手,可能会更低,夏天可能更高
- 后台的数据格式转换定义变了,例如某些特征在训练集的分布在0-18,在测试集中数值均小于1
- 攻防特性,由于系统安全升级,原来可以攻击通过的参数现在无效了,或者欺诈方换了其他的攻击方式
启发:攻防模型的训练需要不断更新,更临近时期的数据有效性更强。
