之前介绍过Apache Spark的基本概念以及环境准备,本篇以分类算法为入口,主要熟悉下Spark的Python API,重点不在算法,而是API的熟悉,具体的分类算法会给出相应的Wiki链接,感兴趣的可以一起交流下。
分类模型种类
我们将讨论Spark中常见的三种分类模型:线性模型、决策树和朴素贝叶斯模型。线性模型, 简单而且相对容易扩展到非常大的数据集;决策树是一个强大的非线性技术,训练过程计算量大 并且较难扩展(幸运的是,MLlib会替我们考虑扩展性的问题),但是在很多情况下性能很好;朴 素贝叶斯模型简单、易训练,并且具有高效和并行的优点(实际中,模型训练只需要遍历所有数 据集一次)。而且,朴素 贝叶斯模型可以作为一个很好的模型测试基准,用于比较其他模型的性能。
线性模型
线性模型的核心思想是对样本的预测结果(通常称为目标或者因变量)进行建模,即对输入变量(特征或者自变量)应用简单的线性预测函数,具体

给定输入数据的特征向量和相关的目标值,存在一个权重向量能够最好对数据进行拟合,拟 合的过程即最小化模型输出与实际值的误差。这个过程称为模型的拟合、训练或者优化。本文主要关注的线性模型包括逻辑回归和线性支持向量机。需要进一步了解线性模型和损失函数的细节,可参考[Spark二分类部分](http://spark.apache.org/docs/latest/mllib-linear- methods.html#binary-classification).
朴素贝叶斯模型
朴素贝叶斯是一个概率模型,通过计算给定数据点在某个类别的概率来进行预测。朴素贝叶斯模型假定每个特征分配到某个类别的概率是独立分布的(假定各个特征之间条件独立)。
基于这个假设,属于某个类别的概率表示为若干概率乘积的函数,其中这些概率包括某个特 2 征在给定某个类别的条件下出现的概率(条件概率),以及该类别的概率(先验概率)。这样使得 模型训练非常直接且易于处理。类别的先验概率和特征的条件概率可以通过数据的频率估计得 到。分类过程就是在给定特征和类别概率的情况下选择最可能的类别。
另外还有一个关于特征分布的假设,即参数的估计来自数据。MLlib实现了多项朴素贝叶斯 (multinomial naïve Bayes),其中假设特征分布是多项分布,用以表示特征的非负频率统计。具体请参考Spark文档中对应的关于[朴素贝叶斯的介绍](http://spark.apache.org/do cs/latest/mllib-naive-bayes.html), 如果想了解模型的数学公司,可参考[维基百科](http://en.wi kipedia. org/wiki/Naive_Bayes_classifier)。
决策树
决策树是一个强大的非概率模型,它可以表达复杂的非线性模式和特征相互关系。决策树在 很多任务上表现出的性能很好,相对容易理解和解释,可以处理类属或者数值特征,同时不要求 输入数据归一化或者标准化。决策树非常适合应用集成方法(ensemble method),比如多个决策 树的集成,称为决策树森林。
下图截图了其他博客的一张决策树的图,比如新来一个用户:无房产,单身,年收入55K,那么根据上面的决策树,可以预测他无法偿还债务(蓝色虚线路径)。
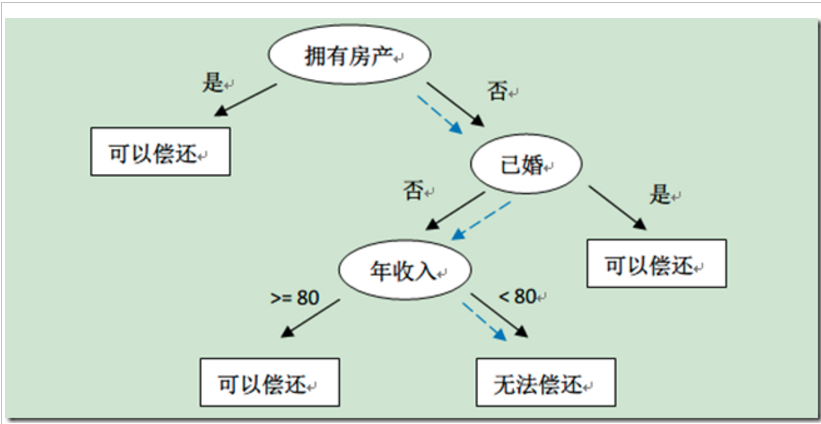
决策树算法是一种自上而下始于根节点(或特征)的方法,在每一个步骤中通过评估特征分裂的信息增益,最后选出分割数据集最优的特征。信息增益通过计算节点不纯度(即节点标签不相似或不同质的程度)减去分割后的两个子节点不纯度的加权和。对于分类任务,这里有两个评估方法用于选择最好分割:基尼不纯和熵。要进一步了解决策树算法和不纯度估计,请参考[Spark官方文档](http://spark.apache.org/docs/latest/mllib-decision-
tree.html)
分类模型实例
上面讲了关于分类的一些概念,都是点到为止,本文的重点在于Spark的Python API熟悉,如想了解具体分类模型,还需要进一步Google对应的算法介绍,本文最后也会给出一些相关的链接。
接下来我们就按照做数据的一般流程来演示这个分类模型是如何构建的,主要包括数据准备(特征提取)、模型训练、模型使用、模型评估以及模型改进等。
数据准备
本文使用的数据集来自Kaggle比赛,由StumbleUpon提供,比赛的问题涉及网页中推荐的页面是短暂(短暂 存在,很快就不流行了)还是长久(长时间流行)。
开始之前,为了让Spark更好地操作数据,我们需要删除文件第一行的列头名称。进入数据 的目录(这里用PATH表示),然后输入如下命令删除第一行并且通过管道保存到以 train_noheader.tsv命名的新文件中:
> sed 1d train.tsv > train_noheader.tsv
接下来,我们启动spark的python命令行工具,命令如下,如果你熟悉Python,那你应该对IPython不会陌生,IPython是个非常有用的家伙,有兴趣的可以了解下。
> IPYTHON=1 pyspark
首先我们来引入相关的依赖包,下面是本文需要的全部依赖包,主要都是分类模型相关的。
from pyspark.mllib.regression import LabeledPoint
from pyspark.mllib.classification import LogisticRegressionWithSGD
from pyspark.mllib.classification import SVMWithSGD
from pyspark.mllib.classification import NaiveBayes
from pyspark.mllib.tree import DecisionTree, DecisionTreeModel
from pyspark.mllib.evaluation import BinaryClassificationMetrics
from pyspark.mllib.regression import LabeledPoint
依赖包引入之后,我们就可以使用对应的API来读入元数据了,通过观察records.first()的输出,大概对数据有个大致的了解。开始四列分别包含URL、页面的ID、 原始的文本内容和分配给页面的类别。接下来22列包含各种各样的数值或者类属特征。最后一列 为目标值,1为长久,0为短暂。
data_path = "/Users/caolei/WorkSpace/hack-spark/data/evergreen"
records = sc.textFile(data_path + "/train-no-header.tsv").map(lambda line : line.split("\t"))
records.first()
我们将用简单的方法直接对数值特征做处理。因为每个类属变量是二元的,对这些变量已有 一个用1-of-编码的特征,于是不需要额外提取特征。由于数据格式的问题,我们做一些数据清理的工作,在处理过程中把额外的(")去掉。数 据集中还有一些用"?"代替的缺失数据,本例中,我们直接用0替换那些缺失数据,而且定义了抽取特征和标签的函数。
records_trimmed = records.map(lambda record : map(lambda field : field.replace("\"", ""), record))
records_trimmed.cache()
def replace_special_simbal(a):
if a == "?":
return 0.0
else:
return float(a)
def extract_label(record):
return record[len(record)-1]
def extract_features(record):
return map(lambda field : replace_special_simbal(field), record[4:len(record) -1 ])
在清理和处理缺失数据后,我们提取最后一列的标记变量以及第5列到第25列的特征矩阵。 将标签变量转换为Int值,特征向量转换为Double数组。最后,我们将标签和和特征向量转换为 LabeledPoint实例。
data = records_trimmed.map(lambda r : LabeledPoint(extract_label(r), extract_features(r))).filter(lambda record : record.features.array.size == 22)
data.cache()
模型训练
其实不管是数据挖掘还是机器学习,或者更牛逼的AI,个人理解,重点在数据,如果数据准备和处理的得当,那模型和算法都是太大问题,下面是模型训练的代码。
# 模型训练,包括线性回归,SVNM,决策树和朴素贝叶斯
numIterations = 10
lrModel = LogisticRegressionWithSGD.train(data, numIterations)
svmModel = SVMWithSGD.train(data, numIterations)
maxTreeDepth = 5
dtModel = DecisionTree.trainClassifier(data, numClasses=2, categoricalFeaturesInfo={},impurity='gini', maxDepth=maxTreeDepth, maxBins=32)
# 朴素朴贝叶斯要求特征值非负
def deal_negative(a):
if a == "?" or float(a) < 0.0:
return 0.0
else:
return float(a)
def extract_no_negative_features(record):
return map(lambda field : deal_negative(field), record[4:len(record) -1 ])
data_for_bayes = records_trimmed.map(lambda r : LabeledPoint(extract_label(r), extract_no_negative_features(r))).filter(lambda record : record.features.array.size == 22)
bayesModel = NaiveBayes.train(data_for_bayes)
模型使用
模型训练出来之后,应该将模型用在测试数据上,简单起见,我们直接将模型运用在训练数据上,还是那句话,重点在熟悉API,而不是算法和效果。以逻辑回归为例:
lrModel.predict(data.first().features) # 输出1
data.first().label #输出0
这个结果说明我们预测错了,你可以尝试其他的数据点,来看看模型训练的是否满足要求,其中这块主要是由模型评估来保证的。
模型评估
在使用模型做预测时,如何知道预测到底好不好呢?换句话说,应该知道怎么评估模型性能。 通常在二分类中使用的评估方法包括:预测正确率和错误率、准确率和召回率、准确率召回率曲线下方的面积、ROC曲线、ROC曲线下的面积和F-Measure。
预测的正确率和错误率
在二分类中,预测正确率可能是最简单评测方式,正确率等于训练样本中被正确分类的数目除以总样本数。类似地,错误率等于训练样本中被错误分类的样本数目除以总样本数。我们通过对输入特征进行预测并将预测值与实际标签进行比较,计算出模型在训练数据上的 正确率。将对正确分类的样本数目求和并除以样本总数,得到平均分类正确率:
## 正确率和错误率
lrTotalCorrect = data.map(lambda r : 1 if (lrModel.predict(r.features) == r.label) else 0).reduce(lambda x, y : x + y)
lrAccuracy = lrTotalCorrect / float(data.count()) # 0.5136044023234485
svmTotalCorrect = data.map(lambda r : 1 if (svmModel.predict(r.features) == r.label) else 0).reduce(lambda x, y : x + y)
svmAccuracy = svmTotalCorrect / float(data.count()) #0.5136044023234485
nbTotalCorrect = data_for_bayes.map(lambda r : 1 if (bayesModel.predict(r.features) == r.label) else 0).reduce(lambda x, y : x + y)
nbAccuracy = nbTotalCorrect / float(data_for_bayes.count()) #0.5799449709568939
dt_predictions = dtModel.predict(data.map(lambda x: x.features))
labelsAndPredictions = data.map(lambda x: x.label).zip(dt_predictions)
dtTotalCorrect = labelsAndPredictions.map(lambda r : 1 if (r[0] == r[1]) else 0).reduce(lambda x, y : x + y)
dtAccuracy = dtTotalCorrect / float(data.count()) #0.654234179150107
最后发现,四个模型的准确率都在50%到60% 左右,跟随即差不多,这说明我们的模型训练的很不好。
准确率和召回率
在信息检索中,准确率通常用于评价结果的质量,而召回率用来评价结果的完整性。
在二分类问题中,准确率定义为真阳性的数目除以真阳性和假阳性的总数,其中真阳性是指 被正确预测的类别为1的样本,假阳性是错误预测为类别1的样本。如果每个被分类器预测为类别 1的样本确实属于类别1,那准确率达到100%。
召回率定义为真阳性的数目除以真阳性和假阴性的和,其中假阴性是类别为1却被预测为0 的样本。如果任何一个类型为1的样本没有被错误预测为类别0(即没有假阴性),那召回率达到 100%。
通常,准确率和召回率是负相关的,高准确率常常对应低召回率,反之亦然。为了说明这点, 假定我们训练了一个模型的预测输出永远是类别1。因为总是预测输出类别1,所以模型预测结果 不会出现假阴性,这样也不会错过任何类别1的样本。于是,得到模型的召回率是1.0。另一方面, 假阳性会非常高,意味着准确率非常低(这依赖各个类别在数据集中确切的分布情况)。
准确率和召回率在单独度量时用处不大,但是它们通常会被一起组成聚合或者平均度量。二 者同时也依赖于模型中选择的阈值。
直觉上来讲,当阈值低于某个程度,模型的预测结果永远会是类别1。因此,模型的召回率 为1,但是准确率很可能很低。相反,当阈值足够大,模型的预测结果永远会是类别0。此时,模 型的召回率为0,但是因为模型不能预测任何真阳性的样本,很可能会有很多的假阴性样本。不 仅如此,因为这种情况下真阳性和假阳性为0,所以无法定义模型的准确率。
图5-8所示的准确率-召回率(PR)曲线,表示给定模型随着决策阈值的改变,准确率和召回 率的对应关系。PR曲线下的面积为平均准确率。直觉上,PR曲线下的面积为1等价于一个完美模 型,其准确率和召回率达到100%。
ROC曲线和AUC
ROC曲线在概念上和PR曲线类似,它是对分类器的真阳性率假阳性率的图形化解释。
真阳性率(TPR)是真阳性的样本数除以真阳性和假阴性的样本数之和。换句话说,TPR是 真阳性数目占所有正样本的比例。这和之前提到的召回率类似,通常也称为敏感度。
假阳性率(FPR)是假阳性的样本数除以假阳性和真阴性的样本数之和。换句话说,FPR是 假阳性样本数占所有负样本总数的比例。
和准确率和召回率类似,ROC曲线(图5-9)表示了分类器性能在不同决策阈值下TPR对FPR 的折衷。曲线上每个点代表分类器决策函数中不同的阈值。
ROC下的面积(通常称作AUC)表示平均值。同样,AUC为1.0时表示一个完美的分类器,0.5则表示一个随机的性能。于是,一个模型的AUC为0.5时和随机猜测效果一样。下面是计算
PR和ROC的代码。
# Compute raw scores on the test set
lrPredictionAndLabels = data.map(lambda lp: (float(lrModel.predict(lp.features)), lp.label))
# Instantiate metrics object
lrmetrics = BinaryClassificationMetrics(lrPredictionAndLabels)
# Area under precision-recall curve
print("Area under PR = %s" % lrmetrics.areaUnderPR)
# Area under ROC curve
print("Area under ROC = %s" % lrmetrics.areaUnderROC)
svmPredictionAndLabels = data.map(lambda lp: (float(svmModel.predict(lp.features)), lp.label))
svmMetrics = BinaryClassificationMetrics(svmPredictionAndLabels)
print("Area under PR = %s" % svmmetrics.areaUnderPR)
print("Area under ROC = %s" % svmmetrics.areaUnderROC)
bayesPredictionAndLabels = data_for_bayes.map(lambda lp: (float(bayesModel.predict(lp.features)), lp.label))
bayesMetrics = BinaryClassificationMetrics(bayesPredictionAndLabels)
print("Area under PR = %s" % bayesMetrics.areaUnderPR)
print("Area under ROC = %s" % bayesMetrics.areaUnderROC)
逻辑回归和SVM的AUC的结果在0.5左右,表明这两个模型并不比随机好。朴素贝叶斯模型 和决策树模型性能稍微好些,AUC分别是0.58和0.65。但是,在二分类问题上这个性能并不是非 常好。
模型改进
根据上面的结果,我们已经确定我们训练出的模型很不少,但问题出在哪里呢?想想看,我们只是简单地把原始数据送进了模型做训练。事实上,我们并没有把所有数据用 在模型中,只是用了其中易用的数值部分。同时,我们也没有对这些数值特征做太多分析,包括特征标准化,归一化处理,异常数据处理,模型参数调优等。接下来计划写一篇专文来介绍这些。
总结
本篇主要是熟悉API为主,所以很多细节都是点到为止,在学习的过程中,也了解了一些Scala的东西,感觉用Scala比用Python还要简洁,学习的路还很长啊。
参考文章
Spark官网
Spark机器学习
留一交叉验证
