之前总结过 B/B+ 树和 MySQL 相关知识点,那边文章最后也简单介绍了建立索引需要注意的地方,考虑到数据库索引在实际应用中的重要性,也是面试题目的重要考察点,还是考虑更完整,更系统的学习总结下
关于索引
在数据库中,对无索引的表进行查询一般称为全表扫描。全表扫描是数据库服务器会读取表中所有行,并检查每一行是否满足语句的限制条件,直到找到所有符合给定条件的记录返回为止。
索引扫描利用索引在存储结构中已经进行排序的特性,只需扫描一部分数据就可以得到结果。在数据量不大的情况下,全表扫描和索引扫描的性能差距不是很大。因为索引也会占用硬盘资源,如果索引所占的空间大于数据的话,很可能全表扫描性能更好。
对于任何DBMS,索引都是进行优化的最主要的因素。对于少量的数据,没有合适的索引影响不是很大,但是,当随着数据量的增加,性能会急剧下降。
索引备选列
用于索引的备选数据列一般是那些出现在 WHERE,JOIN,ORDER BY 或者 GROUP BY 子句中的列。比如:
SELECT
col_a <- 不是备选列
FROM
tbl1 LEFT JOIN tbl2
ON tbl1.col_b = tbl2.col_c <- 备选列
WHERE
col_d = expr; <- 备选列
选择索引
尽量使用整型字段
若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
- 整型数据比起字符,处理开销更小。在比较字符串时,引擎会逐个比较字符串中的每一个字符,而对于整型,只需要比较一次就够了;
- 整型只需要 4 个 byte,而字符串一般不止这么多。索引一般以 B+ 树存储在硬盘上,索引空间比较小,意味着硬盘一个页可以存储更多的索引。通过预读等技术,数据库可以用更少的硬盘寻道时间读取更多索引,减少 IO 时间。
选择高区分度索引
区分度表示字段不重复的比例,公式为: count(distinct col)/count(*)。区分度越高说明扫描的记录越少,唯一键的区分度是 1。这个区分度有经验值么?使用场景不同,这个值很难确定,一般需要 JOIN 的字段,区分度要求 0.1 以上。
前缀索引
选择长度较短的字段原因和尽量使用整型类似,主要也是由计算复杂度和存储空间考虑。如果索引字段为字符串,而且前面 n 个字符都不同,就不需要索引整个数据列,只索引前 n 个字符就可以了。在索引 CHAR、VARCHAR、BINARY、VARBINARY、BLOB和TEXT数据列时可以尝试前缀索引。
最左前缀匹配原则
最左前缀匹配原则主要用在复合索引的使用。假设有张表,其中 (name, cid) 为例,它内部结构简单如下排列:
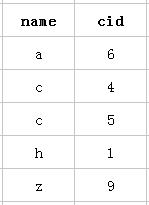
MySQL 创建复合索引的规则是首先会对复合索引的最左边的,也就是第一个 name 字段的数据进行排序,在第一个字段的排序基础上,然后再对后面第二个的 cid 字段进行排序。所以第一个 name 字段是绝对有序的,而第二字段就是无序的了。所以通常情况下,直接使用第二个 cid 字段进行条件判断是用不到索引的。
更进一步,如果复合索引为 (name, cid, zid),意味着这个索引可以被用于检索一下数据列组合:
- name, cid, zid
- name, cid
- name
范围查询
MySQL 在查询复合索引时,使用最左前缀匹配原则,知道遇到范围查询就停止匹配。范围查询如:<,>,BETWEENT,LIKE。比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
尽量避免
即使设置了索引,但是在不当检索下,还是为进行全表扫描或者索引性能不佳的情况,应该尽量避免以下几种情况:
1. 索引列不要参与计算,保持“干净”
比如 from_unixtime(create_time) = '2014-05-29' 就不能使用到索引,原因很简单,B+ 树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成 create_time = unix_timestamp( '2014-05-29' )。
2. 避免 NULL 值判断
应尽量避免在 WHERE 子句中对字段进行 null 值判断,否则将导致引擎放弃使用。
索引而进行全表扫描。
3. 避免使用 OR 连接条件,可以用 UNION
应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10 union all select id from t where num=20
4. LIKE 查询时避免前置 %,这种模糊查询也能导致全表检索,若要提高效率,可以考虑全文检索。
5. 慎用 IN 和 NOT IN,对于连续的值可以考虑用 BETWEEN 代替 IN 和 NOT IN
内容来源
http://mp.weixin.qq.com/s/KsXS5f-1-217CY5R88qOHQ
https://www.zhihu.com/question/36996520?sort=created
http://blog.csdn.net/zhanglu0223/article/details/8713149
http://www.cnblogs.com/hustcat/archive/2009/10/28/1591648.html
